






贪心算法 题型总结
1 基本思想
从问题的某一个初始解出发,通过一系列的贪心选择-当前状态下的局部最优选择,逐步逼近给定的目标;
在每个阶段,都作出一个按照()某个评价函数最优的决策,这个评价函数最优称为贪心准则(类似于动态规划的状态转移方程)
2 基本步骤
和动态规划类似
3 性质
一般具有以下两种限制
3.1 贪心选择性质
其指全局最优解可以通过局部最优解来得到(这也是和动态规划的主要区别),动态规划的算法通常以自底向上的方式来解各种子问题,而贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择,每一次的贪心选择就将所求问题简化为规模更小的子问题。
3.2 最优子结构性质
当一个问题的最优解包含其子问题的最优解时,称此问题具有 最优子结构性质,问题的最优子结构性质是该问题可以用动态规划或者贪心算法求解的关键特征。
4 和动态规划的区别

5 问题
5.1 小数背包问题
还记得之前动态规划讲的背包问题吗?那是01背包问题,无法用贪心算法来解决,因为贪心算法无法保证其背包的价值是全局最优解(背包可能没有装满),其适合于求解在将背包装满的情况下取得的最大价值。
题目:
问题描述:给定n种物品和一个背包。物品i的重量是Wi,其价值为Vi,
背包的容量为C 应如何选择装入背包的物品 使得装入背包中物品的
总价值最大? 这里,在选择物品i装入背包时,可以选择物品i的一部分,
而不一定要全部装入背包,不能重复装载。
现在有三种贪心策略:
按照价值最大贪心,是目标函数增长最快的,但是背包容量却可能消耗的太快,使得装入背包的物品个数减少,而且有很大的几率会冗余,从而不能保证目标函数达到最大值。
按照重量最大贪心,使得背包增长最慢,很显然,重量和价值没有关系,这也无法保证目标函数达到最大值。
按照价值率(价值除以质量),使得单位重量价值增长最快。保证了价值和重量,是最优解。
假定n=3, C=20, v=(25, 24, 15), w= (18, 15, 10),列举4个可行解:

也就是说,如果我们按照价值最大贪心,得到的解就是②;如果按照重量最大贪心,得到解则是③,而最优解是④;
则伪代码如下:
GreedyKnapsack( n, M, v[], w[], x[] )
{
//按价值率最大贪心选择
Sort( n, v, w); //使得v / ≥ / ≥ ≥ / 1/w1 ≥ v2/w2 ≥ … ≥ vn/wn
for i = 1 to n do x[i]=0;
c = M;
for i = 1 to n do
{
if( w[i] > c) break;
x[i]=1; //标记使用1整个
c-=w[i]; //减去该物品重量
}
if( i≤n) x[i] = c/w[i]; //使物品i是选择的最后一项
// 如果需要统计最大价值,则遍历数组x,乘以对应价值求和即可
}
具体实现如下:
#include
#include
#include
using namespace std;
//排序,前者为价值,后者为重量
boolcompare(std::pair i, std::pair j){
return (double)i.first/(double)i.second > (double)j.first/(double)j.second;
}
voidGreedyKnapsack(intlimit_weight, vector<:pair>> goods, vector& result){
if (goods.size() == 0) {
return ;
}
std::sort(goods.begin(), goods.end(), compare);
int i = 0;
for (auto p : goods) {
std::cout << "第" << i << "个物品,价值为" << p.first << ",重量为" << p.second << ",单位重量价值率为" << (double)p.first/p.second << std::endl;
i++;
}
result.assign(goods.size(), 0.0); //初始化
auto itr = goods.begin();
i = 0;
for (; itr != goods.end(), i < result.size(); itr++, i++) {
if ((*itr).second > limit_weight) break; //一定要立马退出,便于后面做部分计算
result[i] = 1; //mark
limit_weight -= (*itr).second;
}
if (itr != goods.end()) {
result[i] = (double)limit_weight/(*itr).second;
}
}
intmain(){
vector result;
vector<:pair int>> goods = {{25, 18}, {24, 15}, {15, 10}};
int limit_weight = 20;
GreedyKnapsack(limit_weight, goods, result);
cout << "--------结果-------" << endl;
for (auto itr = result.begin(); itr != result.end(); itr++) {
if ((*itr) > 0.0) {
std::cout << "需要第" << std::abs(std::distance(result.begin(), itr)) << "个物品 : " << *itr << "个" << std::endl;
}
}
return 0;
}
一个小插曲,一开始想用的是map,发现不能自定义比较函数,就用了vector。
5.3 活动选择问题
贪心策略:对输入的活动以其完成时间的非减序排列,算 法每次总是选择具有最早完成时间的相容活动加入最优解 集中。直观上,按这种方法选择相容活动为未安排活动留下尽可能多的时间。也就是说,该算法的贪心选择的意义是使剩余的可安排时间段极大化,以便安排尽可能多的相 容活动。
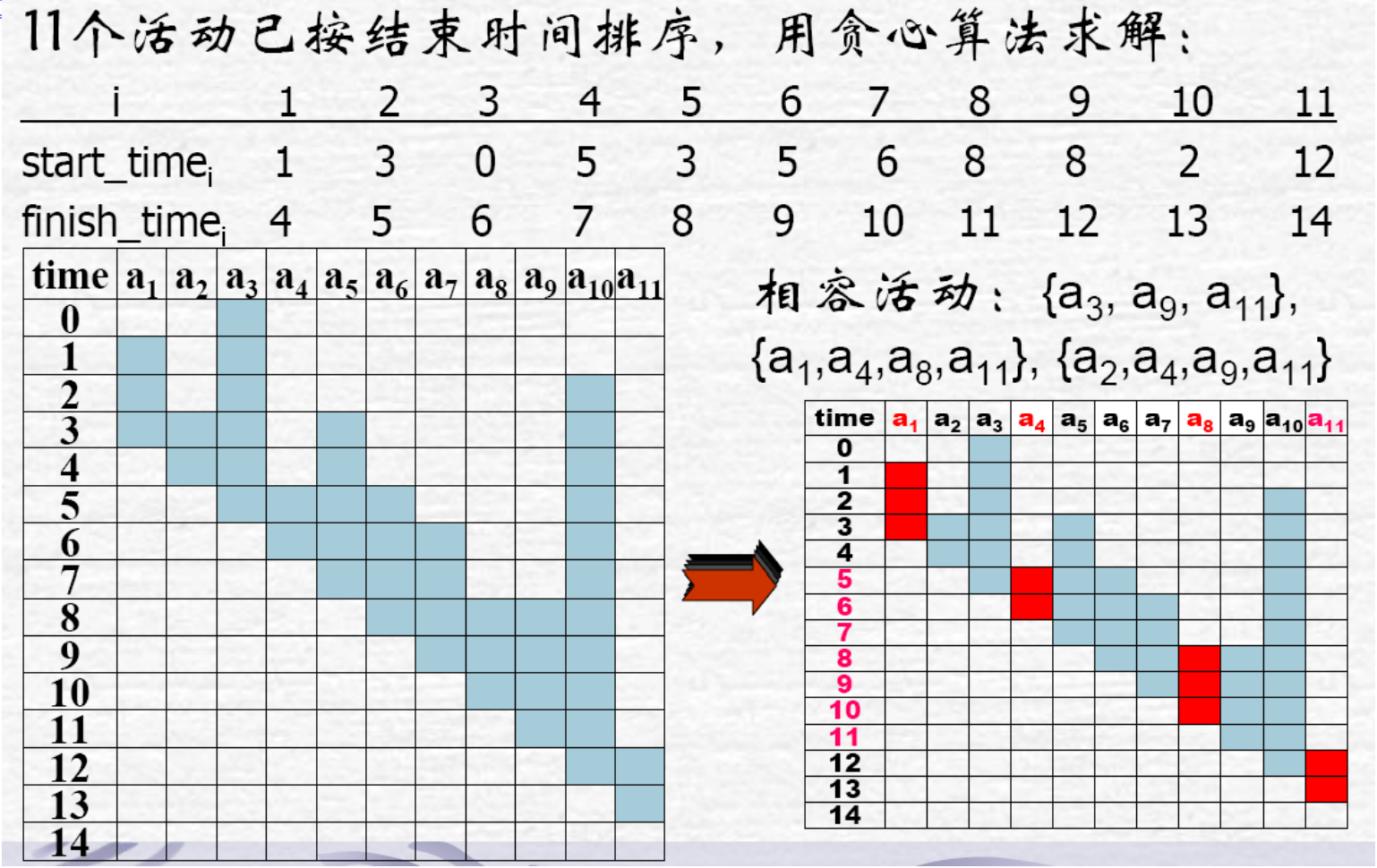
实现
// 活动比较
boolactivity_compare(std::pair i, std::pair j){
if (i.second < j.second)
return true;
else if (i.second == j.second)
return i.first < j.first;
else
return false;
}
//递归方式
intActivitySelector_Recursive(std::vector<:pair>>& solution, std::vector<:pair>> activities,intstart,intend){
if (start > end) {
return 0;
}
int i = start + 1;
for (; i <= end; i++) {
// 找到第一个大于起始活动的活动(这里的结束时间并没有没有占用该时间)
if (activities[i].first >= activities[start].second) {
solution.push_back({activities[i].first, activities[i].second});
break;
}
}
if (end >= start) {
return ActivitySelector_Recursive(solution, activities, i, end);
}
else {
return 0;
}
}
//迭代方式
voidActivitySelector_Iteration(std::vector<:pair>>& solution, std::vector<:pair>> activities){
int len = activities.size();
int last_select = 0;
for (int i = 0; i < len; i++) {
int j = i+1;
while (j < len && activities[j].first < activities[last_select].second) {
j++;
}
if (j >= len) break;
solution.push_back({activities[j].first, activities[j].second});
last_select = j;
}
}
voidtestActivitySelector_Recursive(){
std::vector<:pair int>> solution;
std::vector<:pair int>> activities = {{0,0}, {1,4}, {0, 4}, {3,5}, {0,6}, {5,7}, {3,9}, {5,9}, {6,10}, {8,11}, {8,12}, {2,14}, {12,16}};
// 按照活动的结束时间排序(升序)
std::sort(activities.begin(), activities.end(), activity_compare);
ActivitySelector_Recursive(solution, activities, 0, (int)activities.size()-1);
for (auto itr = solution.begin(); itr != solution.end(); itr++) {
std::cout << "第" << std::distance(solution.begin(), itr) + 1 << "个活动:" << (*itr).first << "->" << (*itr).second << std::endl;
}
}
voidtestActivitySelector_Iteration(){
std::vector<:pair int>> solution;
std::vector<:pair int>> activities = {{0,0}, {1,4}, {0, 4}, {3,5}, {0,6}, {5,7}, {3,9}, {5,9}, {6,10}, {8,11}, {8,12}, {2,14}, {12,16}};
// 按照活动的结束时间排序(升序)
std::sort(activities.begin(), activities.end(), activity_compare);
ActivitySelector_Iteration(solution, activities);
for (auto itr = solution.begin(); itr != solution.end(); itr++) {
std::cout << "第" << std::distance(solution.begin(), itr) + 1 << "个活动:" << (*itr).first << "->" << (*itr).second << std::endl;
}
}
intmain(){
testActivitySelector_Iteration();
return 0;
}
这里有个比较坑的地方,不知道怎么处理一个活动范围包含另一个活动的范围的问题?我的做法是先要按照活动的结束时间再根据活动的起始时间进行排序,避免出现一种情况就是某个课程的时间范围包括另一种的时间范围的情况,所以在面对[0, 4]和[1, 4]的时候优先选择[0, 4]
5.4 单源最短路径问题
最短路径问题可以是使用Belleman-Ford和Dijkstra算法,不同的是,前者边的权值出赋值现了负值,要想责出最大的目标值,这时不能再使用贪心算法,而是需要遍历所有边,找出下一个具有最小权值的路径。但是后者边的权值都限定为了正数及0 ,只需要计算当前路径下的最小权值即可。
原理为:采用贪心的思想,选择离当前结点距离最近的结点,并且判断原距离(指起始结点到目标结点的距离,后面用距离替代)和原结点加上中间结点的距离比较,取较小那个,除此之外,还更新从该中间结点到其它任意结点的距离。
既然是贪心算法,则其推导公式为:
dist[j]=min{dist[j],dist[i]+matrix[i][j]}
j代表目标结点,i代表中间结点,dist[j] 代表原来的结点到目标结点j的距离,dist[i]+matrix[i][j]代表到达中间结点的距离加上从i到j的距离。
实现
//
// Created by staff on 17/3/6.
//
#include
#include
#define INF (~(0x1<<31))//无穷大
struct Graph {
public:
Graph(int m, int e, bool haveDirectioon = true) {
this->m_VerCnt = m;
this->m_EdgeCnt = e;
std::vector<:vector>> temp(this->m_VerCnt, std::vector(this->m_VerCnt, 0));
this->m_Matrixs = temp;
this->m_haveDirectioon = haveDirectioon;
}
// 邻接矩阵
std::vector<:vector>> m_Matrixs;
// 顶点数目
int m_VerCnt;
// 边数目
int m_EdgeCnt;
// 是否是有向图
bool m_haveDirectioon;
};
// 初始化
voidinit(Graph &graph){
// 设置邻接矩阵
for (int i = 0; i < graph.m_VerCnt; i++) {
for (int j = 0; j < graph.m_VerCnt; ++j) {
// 除了自己,都不可达
if (i == j) {
graph.m_Matrixs[i][j] = 0;
}
else {
graph.m_Matrixs[i][j] = INF;
}
}
}
// 根据边的数目设置
std::cout << "输入图的具体值" << std::endl;
int p, q;
for (int i = 0; i < graph.m_EdgeCnt; i++) {
std::cin >> p >> q >> graph.m_Matrixs[p][q];
if (!graph.m_haveDirectioon) { //如果设置了无向图,则不需要输入那么多
graph.m_Matrixs[q][p] = graph.m_Matrixs[p][q];
}
}
// 输出邻接矩阵
std::cout << "输出图的矩阵" << std::endl;
for (int i = 0; i < graph.m_VerCnt; i++) {
for (int j = 0; j < graph.m_VerCnt; ++j) {
if (graph.m_Matrixs[i][j] == INF) {
std::cout << "~~ ";
}
else {
std::cout << graph.m_Matrixs[i][j] << " ";
}
}
std:: cout << std::endl;
}
}
/***
*@param start 起始顶点
*@param prevs 前驱顶点的数组
*@param dist 记录起始顶点到各个顶点的距离
*/
voidDijkstra(Graph graph,intstart, std::vector& prevs, std::vector& dis){
// 访问标志
bool visited[graph.m_VerCnt];
// 初始化前驱顶点数组和起始顶点的距离数组
for (int i = 0; i < graph.m_VerCnt; ++i) {
visited[i] = false;
dis[i] = graph.m_Matrixs[start][i];
if (dis[i] == INF) {
prevs[i] = -1;
}
else {
prevs[i] = start;
}
}
visited[start] = true;
dis[start] = 0; //dis中存储的是start到每个结点(用下标表示)的距离
// 每次找出一个顶点的最短路径
for (int i = 0; i < graph.m_VerCnt; ++i) {
if (i == start) {
continue;
}
int min = INF;
// 找出当前节点最短路径的节点next
int next = start;
for (int j = 0; j < graph.m_VerCnt; ++j) {
if (!visited[j] && dis[j] < min) {
min = dis[j];
next = j;
}
}
// 标记
visited[next] = true;
// 更新当前为最短路径的节点的状态,如果大于最短路程(可能包括不可达)则进行更新
for (int j = 0; j < graph.m_VerCnt; ++j) {
int temp = graph.m_Matrixs[next][j] == INF ? INF : graph.m_Matrixs[next][j] + min;
if (!visited[j] && dis[j] > temp) {
dis[j] = temp;
prevs[j] = next; //强制其需要通过next再访问到j节点
}
}
}
}
intmain(){
int n_cnt, e_cnt; //顶点数目,边数目
std::cout << "输入图的结点个数和边个数"<< std::endl;
std::cin >> n_cnt >> e_cnt;
Graph g(n_cnt, e_cnt);
init(g); //初始化
std::vector prevs(g.m_VerCnt, 0);
std::vector dist(g.m_VerCnt, 0);
int start;
std::cout << "输入图的开始结点"<< std::endl;
std::cin >> start;
Dijkstra(g, start, prevs, dist);
std::cout << "输出从结点"<< start << "到其它各个结点的最短距离"<< std::endl;
for (int i = 0; i < g.m_VerCnt; i++) {
if (i != start) {
std::cout << start << "->"<< i << ": "<< dist[i] << std::endl;
}
}
return 0;
}
结果:

实现2 用优先队列实现
#include
#include
#include
using namespace std;
const int MAX = 10240;
typedef pair pii;
int N, M;
int pDist[MAX];
vector > pMap[MAX];
priority_queue, greater > Q; // 优先队列
voidDijkstra(ints);
intmain(){
cin >> N >> M;
for(int i = 1; i <= M; i++)
{
int s, e, v;
cin >> s >> e >> v; // 无向图
pMap[s].push_back(make_pair(e, v));
pMap[e].push_back(make_pair(s, v));
}
Dijkstra(1);
return 0;
}
voidDijkstra(ints){
for(int i = 1; i <= N; i++) // 初始化
{ pDist[i] = 2147483647; }
pDist[s] = 0;
Q.push(make_pair(pDist[s], s)); // 将源点加入队列
while(!Q.empty())
{
pii x = Q.top(); Q.pop(); // 取最短的边
if(x.first != pDist[x.second]) { continue; } // 防止重复计算
for(int i = 0; i < pMap[x.second].size(); i++)
{
int v = pMap[x.second][i].first; // 待松弛的顶点
int w = pMap[x.second][i].second; // 从顶点x.second到顶点i的距离
if(pDist[v] > pDist[x.second] + w)
{
pDist[v] = pDist[x.second] + w; // 松弛
Q.push(make_pair(pDist[v], v));
}
}
}
for(int i = 1; i <= N; i++)
{
cout << pDist[i] << " ";
}
cout << endl;
}
这个代码的特殊之处在于其使用了优先队列,并且注意,优先队列存储的格式是个pair,前面是中间结点的距离,后面是中间结点,并且使用了内置的greater函数进行从小到大来排序,这样保证每次取出来的都是最小的。一直迭代到什么时候呢?直到其不存在从一个点到另外一个点的距离还可以拆分,也就是其的距离并不是最小的。
代码可以参考维基百科:
function Dijkstra(G, w, s)foreach vertex v in V[G]// 初始化d[v] := infinity // 將各點的已知最短距離先設成無窮大
previous[v] := undefined // 各点的已知最短路径上的前趋都未知
d[s] := 0 // 因为出发点到出发点间不需移动任何距离,所以可以直接将s到s的最小距离设为0
S := empty set
Q := set of all vertices
while Q is not an empty set // Dijkstra演算法主體
u := Extract_Min(Q)
S.append(u)
foreach edge outgoing from u as (u,v)ifd[v] > d[u] + w(u,v)// 拓展边(u,v)。w(u,v)为从u到v的路径长度。d[v] := d[u] + w(u,v) // 更新路径长度到更小的那个和值。
previous[v] := u // 紀錄前趨頂點
5.5 最小生成树问题
最小生成树是指从一个连通加权无向图中选择连接每一个结点,保证其符合树的性质,同时又满足其每个结点的权重相加起来是最小的。
比如说有几个城市你要设计一个路线,这个路线能走完所有的这几个城市,而且路程最短,这个路线就是最小生成树的含义。
问题将另作总结
最小生成树和最短生成路径的区别
最小生成树:无向图的最短路径,保证整棵树的权重是最小的,所以在更新结点的距离时,其更新的是自身结点到所有其它结点的距离,算法包括prime和kruskal;
最短生成路径:有向图的最短路径,只能保证从一个结点到另一个结点的权重是最小的,在更新结点的位置时,更新的是起始结点到其它结点的距离,算法包括floyd和djkstra;
ps:prime和djkstra算法真的很像,注意区分
6 总结
贪心算法和动态规划类似,只能提供一个大概的思路,遇到具体的题目仍然需要具体分析,像最短路径和最小生成树的算法是利用到了贪心的思想并且进行了发散,而像是活动选择这种问题才是单纯的用贪心算法去解决。
















 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









