







本文是笔者在对差分隐私的学习过程中,尝试对差分隐私概念进行的梳理,主要偏向于对其理念和背后原理的解释和分析,而没有将一些具体的细节(敏感度、各种机制)放上来,同时还夹带了笔者自己的一些思(si)考(huo),如果错误之处还请各位大佬指出!(后续可能还会添加一些内容)
1.Derivation
1.1 隐私的“确保”
“确保”这个词可以说是隐私研究的问题核心所在,而我们平常提到的绝大部分“隐私保护”方法,都不能做到“确保”这一点。我们举一个例子:
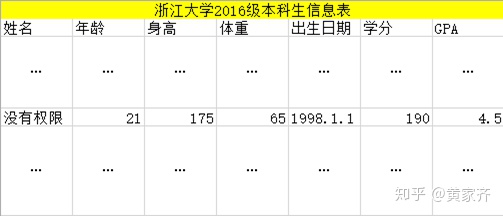
“匿名保护”是最常见的一种隐私保护方法,但在攻击者有足够外部知识的情况下,匿名保护可以说是形同虚设的。比如,上图是一张学生信息表,为了保护学生的隐私(学分、GPA),它将学生的姓名抹去了。然而,虽然使用了匿名保护,但是,如果攻击者掌握了学生的一些外部知识(比如年龄、升高、体重、出生日期),通过这些外部知识,攻击者很快就能知道他在表中所在的位置,也就可以轻松获取我们本希望被保护的隐私信息(学分、GPA)了。
我们在上面提到的,只是外部知识攻击(也叫背景知识攻击)的一个非常简单的例子,事实上,几乎所有的隐私保护方法,比如k-anonymity等,都无法抵御外部知识攻击。不过不必担心,差分隐私是可以抵御外部知识攻击的,差分隐私描述了这样一个承诺:即使攻击者掌握了(隐私数据之外的)无限多的外部知识,我们的隐私数据仍然是安全的。这听起来好像有点不可思议,我们下面就来具体讲述它是怎样做到隐私的完全确保的。
1.2 随机隐私
我们首先来介绍一下随机隐私的概念。在1965年Warner提出了随机应答(Randomized Response)方法,它是第一个通过引入随机性来保证隐私的机制。这一技术针对的是问卷采样问题,方案如下:
对于一个(回答“是”或“否”的)问题,回答者先暗中抛一个硬币,如果是正面,就如实回答问题;否则,再抛一次硬币,根据第二次抛出的正反面来回答是或否。
在这个方案下,回答者在75%的情况下会回答真实的答案,因此我们可以根据调查结果中回答“是”的比例X,使用
这个方案的“隐私”来自于:回答者可以“理直气壮”地否认自己的回答。事实上,不管实际情况如何,都有至少25%的可能性给出答案是或答案否,因此就算得知了回答者的回答,也无法以此来确定他的实际情况。
这个方法虽然简单,但是其背后反映出了深刻的随机化隐私理念,也包括了我们后面将会学到的“本地化隐私”的思想,同学们可以好好体会一哈~
差分隐私就是通过引入随机性来确保隐私的。我们再来看知乎上 @卡兵 举的一个例子(强烈推荐大家阅读一下原文,讲的非常细致通透):
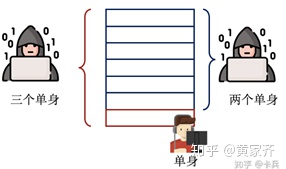
在这个数据库中,每个人的“是否单身”数据都是隐私信息,不可被查询,但是数据库的单身人数总和是可查询的。
当张三不在数据集中时,我们查询到,数据集中的单身人数为2,在张三加入到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









