







简介:本项目FVSoundWaveDemo展示如何在iOS应用中将音频文件转换为可见的声波图形,这对于音乐播放器或语音记录器等应用非常重要。文章详细介绍了音频处理、频谱分析、图形绘制、性能优化、线程管理、用户交互、自定义配置和响应式布局等关键知识点,为iOS开发者提供了一个完整的实战案例。通过源码学习,开发者可以深入理解iOS平台上的音频处理和图形绘制技术,提升应用的交互体验。 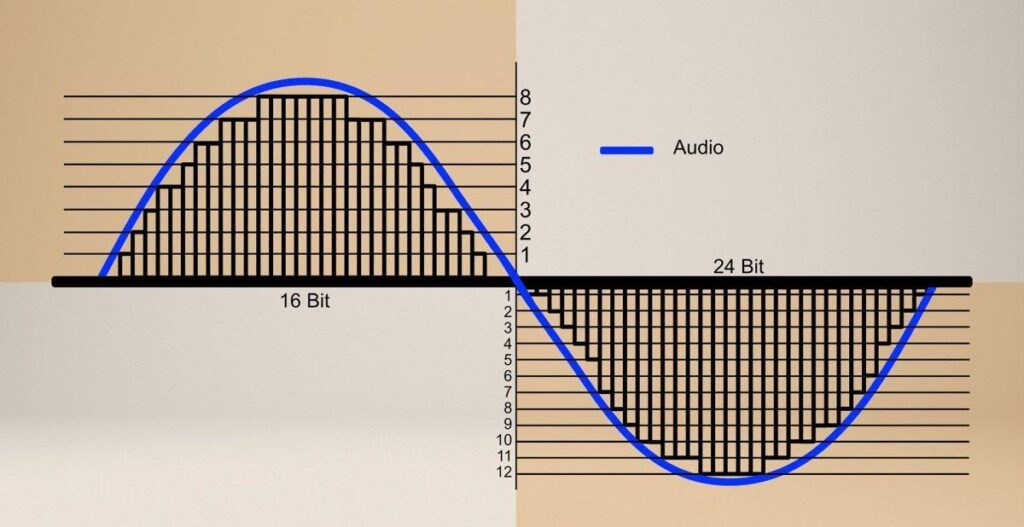
1. 音频转换为声波图形的iOS实现概述
音频转换为声波图形的过程是把音频信号的动态变化可视化的过程,对于开发者来说,通过iOS平台的实现不仅可以增强应用的交互体验,还可以帮助用户更直观地理解音频内容。本文将探讨如何利用iOS的多种框架和API来完成这一任务,从而为后续章节中更深层次的开发细节奠定基础。
在第一章中,我们将首先介绍音频信号转换为声波图形的基本概念及其在iOS平台上的开发环境,包括AVFoundation等核心框架。此外,我们将探讨音频信号数字化的核心环节,以及频谱分析如何成为连接音频与图形的桥梁。本章将为读者提供一个全面的认识框架,使其能够理解并期待接下来的详细技术实现。
接下来,我们将深入探讨如何通过音频文件的读取、音频信号的数字化处理,以及频谱分析等技术手段,实现音频信号到声波图形的转换,并讨论在iOS平台上如何优化这一过程的性能和用户体验。
2. 音频处理基础与框架选择
2.1 AVFoundation框架简介
AVFoundation是一个强大的iOS音频处理库,它提供了对媒体文件、音视频数据进行编码和解码、播放和录制等功能的接口。这个框架使开发者可以方便地在应用程序中集成专业的音视频处理能力。
2.1.1 AVFoundation框架的作用和特点
AVFoundation框架支持多种媒体格式,包括常见的音频和视频格式,提供了丰富的媒体处理工具。开发者可以使用它来实现音频的录制、播放、编辑,以及视频的录制、编辑等功能。
此外,AVFoundation框架的特点还包括: - 支持时间线基础的媒体处理,如剪辑、混合等。 - 支持多轨音频的混音处理。 - 支持实时音视频数据的采集和处理。 - 提供了用于监控音视频质量的回调机制。
2.1.2 如何使用AVFoundation播放音频
使用AVFoundation播放音频的基本步骤包括创建音频播放器、加载音频资源和执行播放操作。以下是一个简单的示例代码:
import AVFoundation
// 创建一个AVAudioPlayer对象
let audioPlayer = try! AVAudioPlayer(contentsOf: URL(fileURLWithPath: "path/to/your/audio/file.mp3"))
// 开始播放
audioPlayer.play()
在上述代码中,首先需要导入AVFoundation模块,然后使用 AVAudioPlayer 类来加载本地音频文件,并进行播放。这里的"path/to/your/audio/file.mp3"需要替换为实际音频文件的路径。
2.2 音频文件的读取与处理
音频文件的读取和处理是音频应用开发的基础,它包括了从文件系统中读取音频数据,并对这些数据进行预处理。
2.2.1 音频文件格式和选择
音频文件格式主要有WAV、MP3、AAC等,其中MP3和AAC格式是目前使用最为广泛的格式。不同的音频格式具有不同的特点和应用场景。例如,WAV格式的音频质量很高,适合做专业级音频处理;而MP3和AAC格式则适合在网络传输和移动设备上播放。
在选择音频格式时,需要考虑到应用场景、文件大小、音质要求等因素。如果应用的重点在于高质量的音频回放,可能会选择无损的音频格式;如果应用需要流式传输,则可能选择压缩率更高的格式。
2.2.2 音频数据的读取和预处理
音频数据的读取通常涉及到解码过程,需要将音频文件中的压缩数据解码为可直接处理的PCM(脉冲编码调制)数据。在iOS中,可以使用 AVAssetReader 和 AVAssetReaderTrackOutput 来读取和解码音频数据。
以下是一个简单的读取音频文件并获取PCM数据的代码示例:
import AVFoundation
// 创建AVURLAsset对象
let asset = AVURLAsset(url: URL(fileURLWithPath: "path/to/your/audio/file.mp3"))
// 创建AVAssetReader对象
let assetReader = AVAssetReader(asset: asset)
// 创建AVAssetReaderTrackOutput对象,指定音频轨
let assetReaderOutput = AVAssetReaderTrackOutput(track: asset.tracks(withMediaType: .audio)[0], outputSettings: nil)
// 将输出添加到assetReader中
assetReader.add(assetReaderOutput)
// 启动读取操作
assetReader.startReading()
// 读取数据
let buffer = CMSampleBufferCreate(kCFAllocatorDefault, false, 0, nil, nil, assetReaderOutput.outputSettings, 0)
assetReaderOutput.copyNextSampleBufferIntoSampleBuffer(buffer!)
let audioBufferList = CMSampleBufferGetAudioBufferListPtr(buffer!)
// 音频数据处理...
在这段代码中,首先创建了一个 AVURLAsset 对象来加载音频文件,然后创建了一个 AVAssetReader 对象来读取数据, AVAssetReaderTrackOutput 用于获取音频轨的解码后的数据。最后通过循环读取解码后的数据。
请注意,代码中的资源路径和类型选择需要根据实际应用进行调整。上述代码段仅作为演示如何读取音频文件和获取PCM数据的示例。
3. 音频信号的数字化表示
音频信号的数字化表示是将模拟音频信号转换成计算机可以处理的数字形式的过程。这一过程涉及到两个重要的参数:采样率和位深度。它们共同决定了数字化信号的质量和所能表达的动态范围。
3.1 采样率的原理和影响
3.1.1 采样率的定义和标准
采样率是指每秒钟内对模拟信号进行数字化采样的次数,通常用赫兹(Hz)表示。根据奈奎斯特定理,采样率至少应该是信号最高频率的两倍,才能保证信号不会发生混叠现象。实际应用中,为了提高信号质量和避免混叠,通常采用比理论值更高的采样率。
3.1.2 采样率对声波图形的影响
采样率直接影响声波图形的精度和细腻程度。采样率高,声波图形更接近实际的波形,细节更加丰富;反之,如果采样率较低,声波图形可能会失真,尤其是在高频率部分。此外,高采样率也意味着更多的数据需要处理,这可能会对系统的处理能力和存储空间提出更高的要求。
3.2 位深度的作用与选择
3.2.1 位深度的定义和作用
位深度指的是每个采样点的数值精度,以位(bit)为单位。位深度越大,所能表示的信号动态范围就越宽,能更精确地描绘出声波的细节。在数字化过程中,较高的位深度可以更好地记录声音的强弱变化,避免出现量化噪声。
3.2.2 位深度对音频质量的影响
选择合适的位深度对于音质有着直接的影响。一般来说,较高的位深度可以带来更高的信噪比和更宽的动态范围,从而提供更丰富和细腻的音频体验。然而,位深度的提高也会导致文件体积的增大,这在存储和传输时可能成为一个问题。
实际应用中的采样率与位深度选择
在设计音频处理应用时,需要根据最终目标来选择合适的采样率和位深度。对于专业的音频工作站,可能会选择高采样率和高位深度(如96kHz/24bit)来保证音质。而在移动设备上,由于受到存储和处理能力的限制,可能会选择较低的采样率和位深度(如44.1kHz/16bit)以优化性能。
接下来,我们将详细探讨如何在编程中使用采样率和位深度参数来处理音频文件,并生成高质量的声波图形。
4. 频谱分析与声波图形生成
4.1 快速傅里叶变换(FFT)基础
4.1.1 FFT的原理和应用
快速傅里叶变换(Fast Fourier Transform, FFT)是数字信号处理领域中一项至关重要的算法,用于高效地将信号从时域转换到频域。与传统的离散傅里叶变换(Discrete Fourier Transform, DFT)相比,FFT极大地提高了计算速度,降低了时间复杂度,从原来的O(N^2)减少到O(NlogN),其中N是样本点的数量。
FFT的核心思想是利用信号的对称性和周期性特点,通过分治算法将原始序列分解为更小的子序列,对每个子序列进行快速计算后,再通过迭代和合并来完成整体的频域转换。这种算法特别适合于处理周期性重复的信号,如音频信号。
在音频处理领域,FFT被广泛用于频谱分析,即从音频信号中提取出频率成分,并量化各成分的幅度和相位。通过频谱分析,我们可以实现很多有用的音频处理功能,例如噪声消除、音高检测、信号压缩等。
4.1.2 FFT在音频处理中的作用
在音频处理软件中,FFT将音频信号的时域表示转换为频域表示,生成频谱数据。频谱数据以一系列复数的形式表示,每个复数对应一个频率的幅度和相位信息。通过分析这些数据,可以绘制出声波的频谱图,直观地显示出各个频率成分的分布和强度。
例如,在音乐播放器应用中,实时的频谱图可以作为用户界面的一部分,为用户提供视觉反馈,增强体验感。在专业音频编辑软件中,频谱图则可以帮助音频工程师分析和编辑音频文件的特定频率成分,进行声音质量的优化。
代码块展示及分析
下面是一个使用Swift语言和Apple的Accelerate框架进行FFT操作的简单示例。Accelerate框架提供了优化的数学函数,包括FFT处理。
import Accelerate
// 创建输入输出复数数组,假定输入数组中有2的幂个样本点
let inputComplexNumbers = [vDSP ComplexDouble](re: [0.0, 1.0, 2.0, 3.0], im: [4.0, 5.0, 6.0, 7.0])
var outputComplexNumbers = inputComplexNumbers
// 创建FFT设置
let fftSetup = vDSP_fftsetup_dft(_log2f(inputComplexNumbers.count), vDSP_DFT_FORWARD)
// 执行FFT
vDSP_fft_zip_dft(fftSetup, &outputComplexNumbers, 1, Int(inputComplexNumbers.count / 2), 1)
// 输出结果数组包含了频谱数据
print(outputComplexNumbers)
以上代码展示了如何使用Apple的Accelerate框架中的FFT函数进行频谱分析。其中, vDSP_fftsetup_dft 用于创建FFT的配置, vDSP_fft_zip_dft 函数执行实际的FFT运算。结果存储在 outputComplexNumbers 数组中,这个数组现在包含了音频信号的频谱信息。
4.2 频谱数据转换为声波图形
4.2.1 频谱数据的获取和处理
获取频谱数据通常涉及两个步骤:首先通过FFT将时域信号转换为频域数据,然后对这些数据进行处理,以便于声波图形的绘制。在处理过程中,开发者可能需要对频谱数据进行过滤和归一化,以确保声波图形的准确性和易读性。
过滤的目的是剔除那些不感兴趣的频率成分,例如某些噪声频率,或对音频信号进行频带分割。归一化则涉及到将频谱数据的幅度调整到一个共同的范围内,使得不同的音频文件或不同时间点的声波图形具有可比性。
4.2.2 将频谱数据绘制成图形
绘制成图形的过程需要将频谱数据映射到二维空间上。通常,X轴代表频率,而Y轴代表该频率成分的幅度。声波图形可以通过多种方式表现,如条形图、折线图,甚至是等高线图。
实现过程中,开发者需要考虑图形的平滑程度和更新频率。平滑处理可以减少图形的噪点,而更新频率则与图形的实时性密切相关。过高的更新频率可能会造成性能问题,而过低则会导致用户体验不佳。
代码块展示及分析
以下示例是一个使用Core Graphics进行声波图形绘制的代码段:
func drawWaveform(from fftData: [vDSP_ComplexDouble], context: CGContext) {
// 绘制频谱声波图形
let numberOfBins = fftData.count / 2
let step = context.bounds.size.width / CGFloat(numberOfBins)
guard let path = CGPath() else { return }
path.move(to: CGPoint(x: step * 0, y: context.bounds.size.height))
for i in 1..<numberOfBins {
let magnitude = abs(fftData[i].re)
let x = step * CGFloat(i)
let y = context.bounds.size.height - magnitude * context.bounds.size.height
path.addLine(to: CGPoint(x: x, y: y))
}
path.closeSubpath()
// 设置绘图样式
let lineColor = UIColor.blue.cgColor
let strokeColor = UIColor.black.cgColor
let fill = CGGradient(colorsSpace: CGColorSpace.sRGB, colors: [lineColor, strokeColor], locations: [0.0, 1.0])
// 在路径上添加渐变色
let gradientLayer = CAGradientLayer()
gradientLayer.frame = context.bounds
gradientLayer.colors = [lineColor, strokeColor]
gradientLayer.startPoint = CGPoint(x: 0, y: 0.5)
gradientLayer.endPoint = CGPoint(x: 1, y: 0.5)
gradientLayer.mask = CAShapeLayer()
gradientLayer.mask?.path = path
context.saveGState()
context.clip(to: context.bounds)
gradientLayer.render(in: context)
context.restoreGState()
}
在这段代码中,我们首先根据FFT数据创建了一个路径 CGPath ,用以绘制频谱图形。每个频谱的幅度值都经过归一化,并映射到绘图区域的Y坐标上。然后,我们使用 CAGradientLayer 添加了一个渐变效果,以增强视觉效果。最后,这个渐变层被应用到当前图形上下文中,完成了声波图形的绘制。
表格展示
下面是一个简化的声波图形参数表,说明了不同频率成分对应的图形属性。
| 频率(Hz) | 幅度 | 颜色 | 图形宽度 | |------------|------|------|----------| | 20-60 | 0.05 | 蓝色 | 狭窄 | | 60-250 | 0.15 | 绿色 | 中等 | | 250-500 | 0.35 | 黄色 | 宽阔 | | 500-2000 | 0.45 | 橙色 | 宽阔 | | 2000-6000 | 0.25 | 红色 | 中等 | | 6000+ | 0.10 | 灰色 | 狭窄 |
这个表格用于在绘制声波图形时确定不同频率成分的颜色和图形宽度,从而使得图形更加直观和美观。
5. 图形渲染与性能优化
音频转换成声波图形的过程不仅包括了音频的处理和分析,也涉及到最终声波图形的渲染和优化。这一章节我们将探讨如何利用iOS平台上的 Core Graphics 技术来绘制声波图形,并讨论相关的性能优化策略。
5.1 Core Graphics绘图技术
Core Graphics 是iOS提供的一个用于2D渲染的框架,其API设计以绘图上下文为中心,可用来绘制各种图形和图片。为了绘制声波图形,我们需要使用 Core Graphics 提供的API来在屏幕上绘制线条,将音频频谱数据可视化为波形。
5.1.1 Core Graphics的基础和API介绍
Core Graphics 是基于Quartz绘图引擎的一个C语言API集合,允许开发者在视图中进行复杂的图形绘制操作。它由以下几个核心组件构成:
- CGContext : 作为绘图的基础,提供了创建图形、路径、渐变、阴影等功能。
- CGPath : 提供了创建复杂路径的能力,如线条、矩形、椭圆、圆弧等。
- CGImage : 用于处理位图图像数据。
- CAGradientLayer : 提供了创建渐变效果的能力。
使用 Core Graphics 需要首先获得一个上下文 CGContextRef ,随后便可以通过调用API来绘制图形。下面的代码示例展示了如何创建一个简单的上下文并绘制一个矩形:
CGContextRef ctx = UIGraphicsGetCurrentContext();
if (ctx) {
// 设置填充颜色为红色
CGContextSetFillColorWithColor(ctx, [UIColor redColor].CGColor);
// 创建一个矩形路径
CGRect rect = CGRectMake(50, 50, 100, 100);
CGContextAddRect(ctx, rect);
// 填充矩形
CGContextFillRect(ctx);
}
在这个代码块中,首先检查当前是否有有效的上下文,然后设置填充颜色为红色,并创建了一个矩形路径。最后,使用 CGContextFillRect 函数来填充该路径。这只是 Core Graphics 绘图能力的一个简单例子。
5.1.2 使用Core Graphics绘制声波图形
为了绘制声波图形,我们需要将音频信号的频谱数据转换为一系列点,这些点会构成一个路径,通过 Core Graphics 绘制成线段或者曲线。考虑到声波图形的动态特性,通常这些绘制会在一个动画循环中不断更新。
下面的步骤解释了如何使用 Core Graphics 绘制动态的声波图形:
- 获取音频数据 : 从音频会话或者录音会话中获取实时音频数据。
- 分析音频数据 : 将音频数据进行傅里叶变换(FFT),得到频谱数据。
- 转换频谱数据为路径 : 频谱数据中的每个值可以代表声波图形的高度,这些值按照时间顺序排列,可以构成声波图形的各个点。
- 创建并渲染图形 : 使用
Core Graphics创建一个图形上下文并根据路径数据绘制声波图形。 - 动画循环 : 在一个定时器或者音频播放回调中重复步骤3和4,这样可以实时地更新声波图形。
这里是一个基本的代码示例,演示了如何在定时器中绘制声波图形:
- (void)drawWaveform {
CGContextRef ctx = UIGraphicsGetCurrentContext();
// 这里的data是你通过FFT得到的频谱数据数组
NSArray *data = self.spectrumData;
// 清除旧的图形数据
CGContextClearRect(ctx, self.bounds);
// 绘制声波图形
CGPoint previousPoint = CGPointZero;
for (NSInteger i = 0; i < data.count; ++i) {
CGFloat value = [data[i] floatValue];
CGFloat x = self.bounds.size.width * (i / (CGFloat)data.count);
CGFloat y = self.bounds.size.height * (value / 128.0); // 假设128是最大值
CGPoint point = CGPointMake(x, y);
if (i > 0) {
CGContextAddLineToPoint(ctx, previousPoint, point);
}
previousPoint = point;
}
// 关闭路径
CGContextClosePath(ctx);
// 使用黑色填充路径
CGContextSetFillColorWithColor(ctx, [UIColor blackColor].CGColor);
CGContextDrawPath(ctx, kCGPathFill);
// 确保上下文没有被错误地修改
CGContextRestoreGState(ctx);
}
这段代码解释了如何在 UIGraphicsGetCurrentContext 获取的上下文中绘制声波图形。首先,我们假定 data 是一个包含频谱数据的数组。然后,我们将数组中的每个值转换成点,形成一条线。如果 data 是连续的频谱数据,这段代码将会绘制出连续的声波图形。在实际应用中,你可能需要根据时间间隔取样频谱数据来适应不同的帧率。
5.2 性能优化策略
在声波图形渲染过程中,性能优化是至关重要的。尤其是对于实时音频分析和绘制的应用,性能优化可以提升用户体验,减少卡顿和延迟。
5.2.1 缓存机制的设计与实现
在动态绘制声波图形时,重复执行绘图操作会消耗大量的CPU资源。一个有效的优化方法是引入缓存机制。基本的缓存思想是减少不必要的绘图操作,仅更新改变的部分。
例如,在声波图形绘制时,只有新的音频数据到来时,我们才需要更新声波图形的绘制。在这种情况下,可以采用一个缓存机制来存储已经绘制的声波图形的某些部分。在更新声波图形时,仅重绘新的部分并使用缓存的内容来绘制旧的部分。
下面是一个简化的实现示例:
- (void)updateWaveformWithNewData:(NSArray *)newData {
// 只有当新数据到来时才进行更新
if (self.lastData.count > 0) {
// 使用缓存机制来重用旧的图形数据
[self reuseCacheForNewWaveformData:self.lastData newData:newData];
}
// 更新私有属性以保存新数据
self.lastData = [newData copy];
}
- (void)reuseCacheForNewWaveformData:(NSArray *)oldData newData:(NSArray *)newData {
// 这里可以根据实际的绘图逻辑来实现重用和更新的逻辑
// 例如,可能需要比较oldData和newData的差异,并仅重绘改变的部分
// ...
}
通过这个方法,我们能够减少不必要的图形绘制,因为只有数据变化的部分才被重新绘制,其余的可以使用缓存来快速展示。
5.2.2 数据下采样的原理和应用
数据下采样是一种常见的降低数据处理负载的方法。在音频处理中,下采样就是减少采样率,从而减少处理的数据量。理论上,只要下采样的结果仍能满足声波图形的分辨率要求,这种方法是有效的。
例如,在音频的频率分析阶段,如果原始的采样率是44.1kHz,我们可以将其降低到22kHz、11kHz甚至更低,这取决于具体的应用需求。较低的采样率意味着每个单位时间需要处理的数据量更少,这将减少FFT的计算量和声波图形的绘制量。
在实施下采样的时候,需要考虑如何选择合适的采样率和下采样算法,确保声波图形能够反映出音频信号的关键特征,同时减少性能负载。以下是一个简化的下采样过程示例:
- (NSArray *)downsampleData:(NSArray *)data toRate:(NSInteger)rate {
NSMutableArray *downsampledData = [NSMutableArray array];
// 以rate为步长遍历原数据
for (NSInteger i = 0; i < data.count; i += rate) {
// 在这里进行采样值的计算,比如取平均值
CGFloat value = 0;
for (NSInteger j = 0; j < rate; ++j) {
if (i + j < data.count) {
value += [data[i + j] floatValue];
}
}
value /= rate;
[downsampledData addObject:@(value)];
}
return downsampledData;
}
在这个代码示例中, data 数组包含了原始的音频数据。我们将它以 rate 的步长进行下采样,将相邻的 rate 个数据值的平均值作为下采样后的数据值。注意,在实际应用中,下采样算法可能会更加复杂,并且需要考虑防止数据失真等因素。
通过合理地选择下采样率和采样策略,可以在保证图形质量和用户感受的前提下,有效减少性能开销,提升应用的整体性能。
6. 线程管理与用户交互
音频处理和声波图形显示在iOS应用中属于资源密集型操作。在处理这些任务时,线程管理和用户交互设计显得尤为重要。妥善管理线程可以提高应用性能,防止界面卡顿,而优秀的用户交互设计则能提升用户体验。本章将详细介绍如何在iOS应用中实现有效的线程管理以及如何优化用户交互。
6.1 线程管理机制
在多任务操作系统中,线程管理是维持应用响应性和性能平衡的关键。iOS系统提供了几种线程管理的机制,其中 Grand Central Dispatch (GCD)和 OperationQueue 是最常使用的。
6.1.1 gcd的基本使用和优势
GCD是苹果提供的一个强大且简洁的C语言库,用于优化应用程序对多核处理器的使用,简化多线程编程。使用GCD的优势主要体现在以下几点:
- 简洁的API :相较于传统的多线程编程,GCD提供了一个更为简洁的API,开发者无需直接管理线程的创建与销毁。
- 高效的线程调度 :GCD背后由系统调度器进行管理,能够根据设备的负载情况自动优化线程的使用。
- 自动引用计数(ARC)的集成 :与ARC集成良好,无需手动管理对象引用,避免了内存泄漏。
下面是一个使用GCD进行异步任务的示例代码:
DispatchQueue.global(qos: .background).async {
// 执行耗时的音频处理操作
DispatchQueue.main.async {
// 处理完音频后,回到主线程更新UI
}
}
在上述代码中,耗时操作在全局后台队列中异步执行,完成后在主线程更新UI,这样做可以保持UI的流畅性。
6.1.2 OperationQueue的高级应用
OperationQueue 是基于GCD之上的更高级的抽象,它允许对单个任务( NSOperation )进行更多的控制。 NSOperation 可以被取消、依赖以及设置优先级。
OperationQueue 的主要优势包括:
- 任务依赖和执行顺序控制 :可以设置操作之间的依赖关系,以控制执行顺序。
- 并发控制 :可以限制同时执行的操作数量。
- 取消操作 :可以取消正在排队或正在执行的操作。
以下是一个使用 OperationQueue 的示例,展示了一个音频处理队列,其中包括多个步骤,每个步骤都是一个 NSOperation 对象:
let queue = OperationQueue()
let processOperation = NSBlockOperation {
// 处理音频数据
}
let audioAnalysisOperation = NSBlockOperation {
// 进行音频分析
}
// 设置操作依赖,确保按照正确的顺序执行
audioAnalysisOperation.addDependency(processOperation)
// 将操作添加到队列中
queue.addOperations([processOperation, audioAnalysisOperation], waitUntilFinished: false)
通过这样的管理,可以有效地将音频处理任务分散到不同的操作中,提高应用性能。
6.2 用户交互体验优化
优秀的用户交互体验是任何应用成功的关键。为了优化用户交互,需要考虑手势识别技术以及事件处理策略。
6.2.1 手势识别技术与应用
iOS中的手势识别技术可以提供直观、流畅的交互方式。 UIKit 提供了多种手势识别器,如 UITapGestureRecognizer 和 UIPanGestureRecognizer 等。正确地利用这些手势识别器,可以极大地提升用户体验。
以下是如何在视图上添加一个简单的双击手势识别器的代码示例:
let doubleTapGesture = UITapGestureRecognizer(target: self, action: #selector(handleDoubleTap))
doubleTapGesture.numberOfTapsRequired = 2
view.addGestureRecognizer(doubleTapGesture)
@objc func handleDoubleTap() {
// 双击操作的响应代码
}
6.2.2 事件处理的策略和实现
事件处理策略应当考虑应用的上下文和用户期望。对于音频处理应用来说,常见的事件处理策略包括:
- 监听音频播放状态 :实现
AVAudioPlayerDelegate的代理方法,来监听播放、暂停、停止等状态。 - 触摸反馈 :对于用户界面触摸操作,应用应该提供相应的反馈,如视图变化、声音提示等。
- 触摸调节音量和进度 :用户可以通过触摸屏幕的特定区域来调整音量和进度,这样的交互需要精细设计以满足用户的直觉。
事件处理实现的一个简单示例:
player.delegate = self
player.play()
func audioPlayer(_ player: AVAudioPlayer, did_failWithError error: Error) {
// 播放失败处理逻辑
}
func audioPlayerDidFinishPlaying(_ player: AVAudioPlayer, successfully flag: Bool) {
// 播放完成处理逻辑
}
通过上述策略和代码示例的结合,我们可以看到如何构建一个响应用户操作的音频应用,并且保持应用的响应性和稳定性。
通过本章节的介绍,我们了解了在iOS音频应用中实现有效线程管理和优化用户交互的方法。下一章我们将继续探索如何配置自由化和实现响应式设计,使应用更加灵活和适应不同的用户需求。
7. 配置自由化与响应式设计
随着应用程序的发展和用户需求的多样化,提供一个高度可定制的用户界面和灵活的布局适应性变得至关重要。在iOS平台实现音频数据视觉化的应用时,我们需要考虑到不同的配置选项,以满足不同用户和设备的需求。
7.1 自定义声波图形配置
7.1.1 声波图形颜色和线宽的定制
为了提供个性化的用户体验,允许用户自定义声波图形的颜色和线宽是一个重要特性。这可以通过在应用中实现颜色选择器和线宽选择器来完成。
具体实现步骤如下:
- 在界面上添加颜色选择器和线宽选择器。
- 当用户选择不同的颜色或线宽时,应用将更新声波图形的显示设置。
- 声波图形视图需要监听颜色和线宽的变化,并响应这些变化以重新绘制图形。
代码示例:
class WaveformView: UIView {
@objc var updateWaveform: ((Color, CGFloat) -> Void)?
func setColor(color: Color) {
// 更新内部状态
// 调用updateWaveform回调
updateWaveform?(color, lineThickness)
// 重新绘制声波图形
setNeedsDisplay()
}
func setLineThickness(_ thickness: CGFloat) {
// 更新线宽设置
// 调用updateWaveform回调
updateWaveform?(currentColor, thickness)
// 重新绘制声波图形
setNeedsDisplay()
}
// ...
}
在上述代码中,我们定义了一个 WaveformView 类,它有一个 updateWaveform 的回调,当颜色或线宽改变时,它将被调用,并触发声波图形的重新绘制。
7.1.2 配置选项的实现和用户界面设计
自定义配置选项应通过简洁直观的用户界面呈现给用户。使用 UIPickerView 或 UIStepper 等控件,可以很容易地让用户选择颜色和线宽。
用户界面设计中,颜色选择器可以通过展示一个颜色条或者颜色盘来让用户选择颜色,线宽选择器则可以通过一个滑动条来调节。实现过程中,每当用户做出选择时,都要实时更新视图以提供即时反馈。
7.2 响应式布局的实现
在iOS应用中,为了确保用户体验的一致性和美观性,声波图形显示的响应式布局是必不可少的。我们可以利用Auto Layout和Size Classes来实现这一点。
7.2.1 Auto Layout在声波图形显示中的应用
Auto Layout可以根据不同的屏幕尺寸和方向动态调整声波图形视图的位置和大小。它通过一系列的约束来定义视图间的相对位置,从而实现了视图布局的灵活性。
class WaveformViewController: UIViewController {
// ...
override func viewDidLoad() {
super.viewDidLoad()
let waveformView = WaveformView()
// 添加视图到视图控制器的视图中
view.addSubview(waveformView)
// 设置约束条件
waveformView.translatesAutoresizingMaskIntoConstraints = false
NSLayoutConstraint.activate([
waveformView.leadingAnchor.constraint(equalTo: view.leadingAnchor, constant: 10),
waveformView.trailingAnchor.constraint(equalTo: view.trailingAnchor, constant: -10),
***Anchor.constraint(equalTo: ***Anchor, constant: 20),
waveformView.bottomAnchor.constraint(equalTo: view.bottomAnchor, constant: -20),
// 其他需要的约束
])
}
}
7.2.2 Size Classes的使用和布局适应性
Size Classes提供了一种方法来处理不同设备上可能不同的布局需求。通过定义不同的布局方案,我们可以确保声波图形在所有设备上都能正确展示。
例如,我们可以为iPhone的普通尺寸和iPad的横屏模式设置不同的约束集合:
override func viewDidLoad() {
super.viewDidLoad()
let waveformView = WaveformView()
view.addSubview(waveformView)
waveformView.translatesAutoresizingMaskIntoConstraints = false
// 为iPhone设置约束
NSLayoutConstraint.activate([
waveformView.leadingAnchor.constraint(equalTo: view.leadingAnchor, constant: 10),
waveformView.trailingAnchor.constraint(equalTo: view.trailingAnchor, constant: -10),
// 其他需要的iPhone约束
])
// 为iPad设置不同的约束
if UIDevice.current.userInterfaceIdiom == .pad {
NSLayoutConstraint.activate([
waveformView.leadingAnchor.constraint(equalTo: view.leadingAnchor, constant: 20),
waveformView.trailingAnchor.constraint(equalTo: view.trailingAnchor, constant: -20),
// 其他需要的iPad约束
])
}
}
通过使用Size Classes和Auto Layout,应用可以确保声波图形在不同尺寸的设备和不同方向的屏幕上都具有良好的可视性和可用性。
简介:本项目FVSoundWaveDemo展示如何在iOS应用中将音频文件转换为可见的声波图形,这对于音乐播放器或语音记录器等应用非常重要。文章详细介绍了音频处理、频谱分析、图形绘制、性能优化、线程管理、用户交互、自定义配置和响应式布局等关键知识点,为iOS开发者提供了一个完整的实战案例。通过源码学习,开发者可以深入理解iOS平台上的音频处理和图形绘制技术,提升应用的交互体验。

















 8172
8172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









