







原标题:一次马失前蹄的SQL优化:递归查询引发的血案
作者介绍
黄浩:从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
在分享时,有读者表示“很想知道,作者失败的时候是怎么办?”,并且看热闹不嫌事大,要求“来一篇文章呗”。好吧,正所谓,常在河边走,哪有不湿鞋。本人在SQL优化领域摸爬滚打多年,“接客”无数,难免会遇到些难以伺候的“官人”,本文就跟大家分享一次不成功的优化经历与教训。
一个由正则表达式引发的“血案”
话说某天一大早,我收到了一封来自社区的邮件,居然有人在社区提问时@我,在邀请的一众专家中,居然有我!瞬间,我受宠若惊并诚惶诚恐,要知道,这是我第一次受邀解决问题。
我战战兢兢点开邮件中的链接,提问的标题是《Oracle正则表达式作为条件执行计划会改变》。看标题,似乎是正则表达式干扰了执行计划,我的第一反应是:是不是因为使用了正则表达式,导致了索引优化器不能走索引扫描?我心存侥幸:如果是这样,该多好呀。再往下看正文内容:
SQL如下:
SELECT TA.*
FROM TAB_T1 TA
INNER JOIN (SELECT ROW_NUMBER() OVER(PARTITION BY L.HDID_C ORDER BY L.LLID_C DESC) RN,
L.HDID_C,
L.URDID_C
FROM ESF.TAB_T2 L) R
ON (R.HDID_C = TA.APLTNN_C AND R.RN = 1)
WHERE TA.ATPY_C =
在实际应用中,会对TA.CACSS_C做过滤,当条件值为常量时,如:AND TA.CACSS_C IN ('10001'),其执行计划如下:
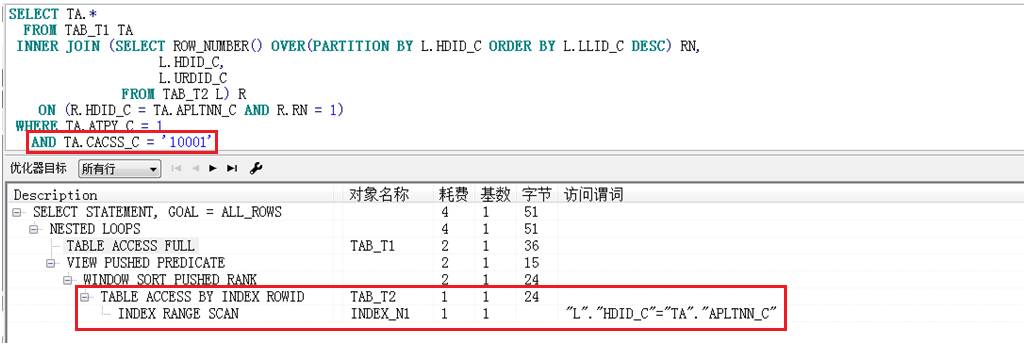
此时,TAB_T2的访问方式是通过INDEX_N1 INDEX RANGE SCAN的。
而当过滤值变成一个正则表达式的子查询时:
SELECT TA.*
FROM TAB_T1 TA
INNER JOIN (SELECT ROW_NUMBER() OVER(PARTITION BY L.HDID_C ORDER BY L.LLID_C DESC) RN,
L.HDID_C,
L.URDID_C
FROM ESF.TAB_T2 L) R
ON (R.HDID_C = TA.APLTNN_C AND R.RN = 1)
WHERE TA.ATPY_C = 1
AND TA.CACSS_C IN
(SELECT REGEXP_SUBSTR(CONT, '[^,]+', 1, LEVEL)
FROM (SELECT '10001' CONT FROM DUAL)
CONNECT BY LEVEL <= REGEXP_COUNT(CONT, '[^,]+'))
执行计划如下:
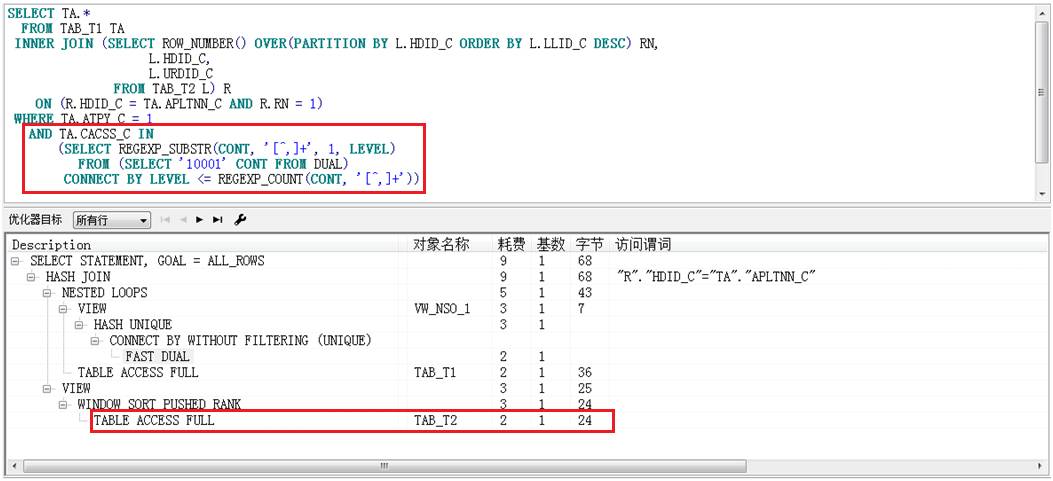
此时,TAB_T2的访问方式是TABLE ACESS FULL。
要说明的是:在该例中,无论是写成常量还是正则表达式,其值是一样的,都是1001。
请教各位专家:为何有了正则表达式,执行计划就变了呢?
似是而非,扑朔迷离
果然是正则表达式干扰了优化器对索引的选择。但是仔细一看,又不是那么回事:
我们常见的正则表达式干扰索引扫描的场景是这样的:regexp_like(column_name, 'a')。如果我们在column_name字段上创建了索引,该条件自然无法选择index range scan的访问方式。
而在该提问中,正则表达式REGEXP_SUBSTR的参数并非表的字段,而是一个常量。
在没有正则表达式的时候,INDEX RANGE SCAN的INDEX是INDEX_N1对应的字段是HDID_C,该字段来自TAB_T2,是关联字段,而非过滤字段。
正则表达式是出现在IN子查询中,而IN表达式的字段为CACSS_C,一方面,没有正则表达式情况下使用的索引也非CACSS_C字段对应的索引,另一方面,该字段并
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









