






作者:翁松秀
Maven打包Java版的spark程序到jar包,本地Windows测试,上传到集群中运行
文章目录Maven打包Java版的spark程序到jar包,本地Windows测试,上传到集群中运行Step1:Maven打包Jar包Step2:本地测试spark程序Step3:Jar包上传到集群Step4:集群上提交Jar包
学习spark的路漫漫啊~前面搭建好了本地环境,用eclipse跑了几个spark自带的程序,现在想用maven将程序打包成jar包,然后在本地测试,再上传到服务器集群中提交。
Windows本地搭建Spark开发环境
路漫漫其修远兮,吾将上下而求索。
Step1:Maven打包Jar包
windows本地测试版JavaWordCount代码:
package code.demo.spark;
import scala.Tuple2;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
//将hadoop路径映射为本地的hadoop路径
System.setProperty("hadoop.home.dir", "F:\\home\\hadoop");
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount").setMaster("local");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
//从本地磁盘中读取待统计的文件
JavaRDD lines = ctx.textFile("F:/home/spark/README.md");
JavaRDD words = lines.flatMap(new FlatMapFunction() {
private static final long serialVersionUID = 1L;
@Override
public Iterable call(String s) {
return Arrays.asList(SPACE.split(s));
}
});
JavaPairRDD ones = words.mapToPair(new PairFunction() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(String s) {
return new Tuple2(s, 1);
}
});
JavaPairRDD counts = ones.reduceByKey(new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List> output = counts.collect();
for (Tuple2, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
ctx.close();
}
}
win + R 打开运行窗口输入cmd打开命令行窗口,切换到程序所在目录,我的目录是:
E:\code\JavaWorkspace\SparkDemo
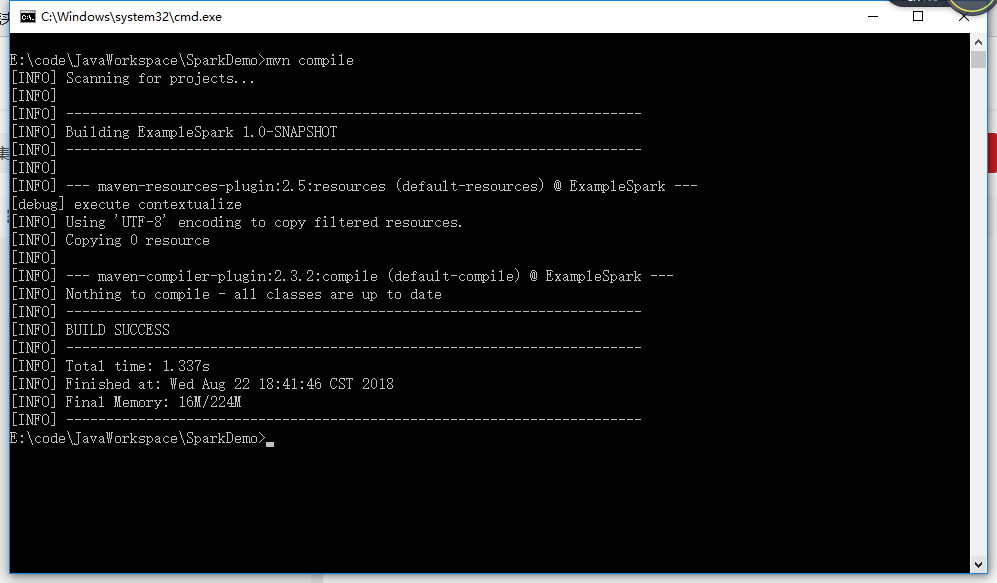
编译程序
mvn compile
打包程序
mvn package
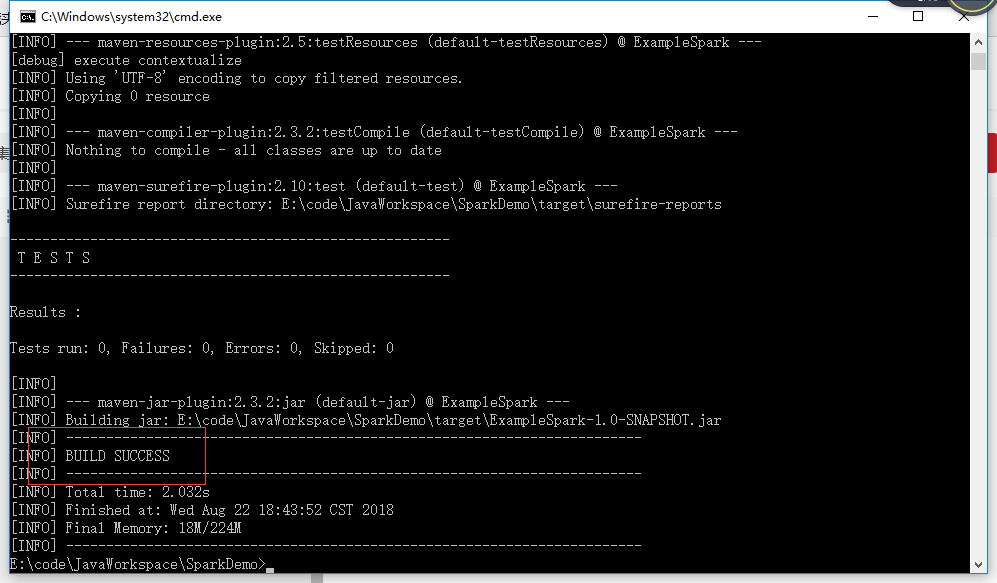
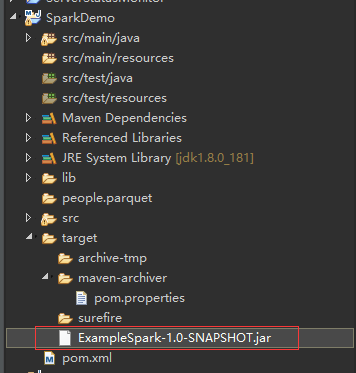
如果程序没有特殊情况,比如缺胳膊少腿,打包完后回看到“BUILD SUCCESS”,说明打包成功,这时在maven工程的target文件夹中就可以看到打包好的jar包。
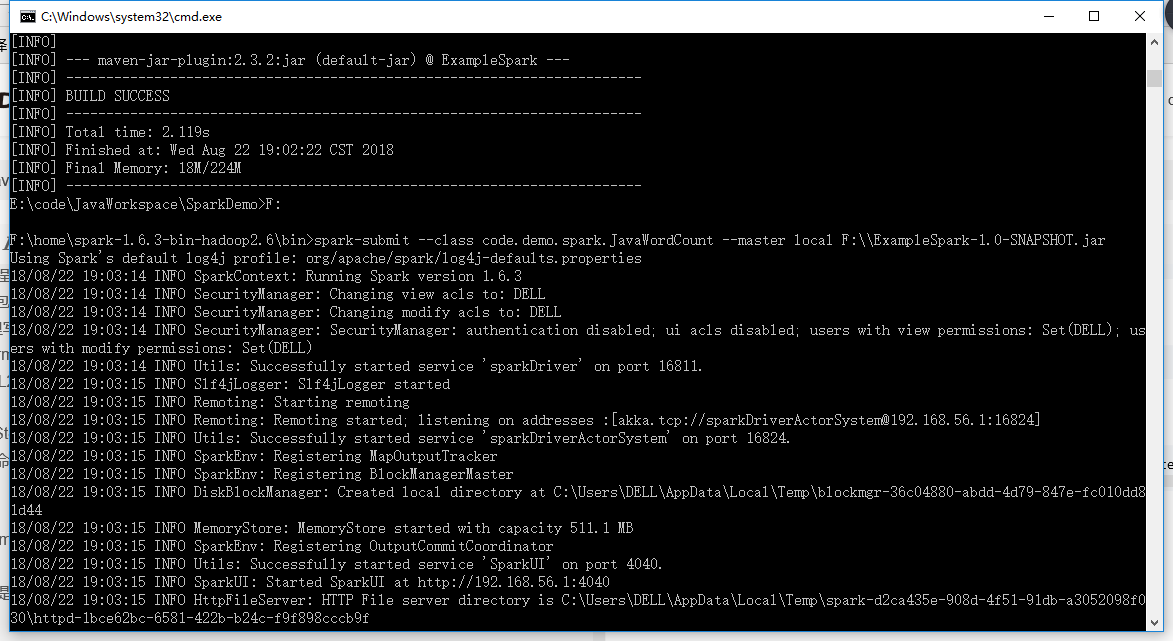
Step2:本地测试spark程序
打开命令行窗口进入spark安装目录的bin目录底下,我的spark安装路径是
F:\home\spark-1.6.3-bin-hadoop2.6
为了提交方便,我把打包好的jar包放到了F盘的根目录
F:\ExampleSpark-1.0-SNAPSHOT.jar
然后执行命令
spark-submit --class code.demo.spark.JavaWordCount --master local F:\\ExampleSpark-1.0-SNAPSHOT.jar
Step3:Jar包上传到集群
准备工作:因为WordCount程序需要读取文件,为了方便起见,所以我们将程序中要统计的文件word.txt上传到HDFS
命令格式:hadoop fs -put 本地路径 HDFS路径
命令如下:
hadoop fs -put /home/hmaster/word.txt hdfs://hadoop-mn01:9000/user/hmaster/word.txt
查看是否上传成功:
hadoop fs -ls hdfs://hadoop-mn01:9000/user/hmaster
如果看到word.txt说明成功,没有则失败。上传失败的原因可能hdfs上面路径不存在,比如说hmaster文件夹不存在,在hdfs的user目录下创建hmaster文件夹:
hadoop fs -mkdir /user/hmaster
集群版代码:直接从HDFS读取要统计单词的文件word.txt
package code.demo.spark;
import scala.Tuple2;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
//从hdfs中读取word.txt进行单词统计
JavaRDD lines = ctx.textFile("hdfs://hadoop-mn01:9000/user/hmaster/word.txt");
JavaRDD words = lines.flatMap(new FlatMapFunction() {
private static final long serialVersionUID = 1L;
@Override
public Iterable call(String s) {
return Arrays.asList(SPACE.split(s));
}
});
JavaPairRDD ones = words.mapToPair(new PairFunction() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(String s) {
return new Tuple2(s, 1);
}
});
JavaPairRDD counts = ones.reduceByKey(new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List> output = counts.collect();
for (Tuple2, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
ctx.close();
}
}
从本地windows上传jar包到linux服务器的集群里,我用的是WinSCP,除了WinSCP还有其他的方法,不一一例举。
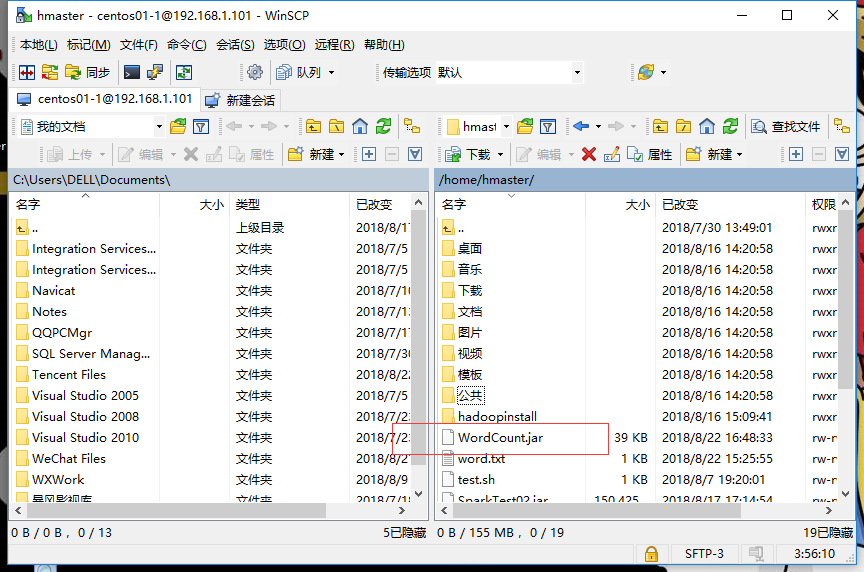
Step4:集群上提交Jar包
打开spark主节点服务器的终端,进入spark的安装目录,执行提交命令:
.bin/spark-submit --class code.demo.spark.JavaWordCount --master spark://hadoop-mn01:7077 /home/hmaster/WordCount.jar
命令解释:
.bin/spark-submit :提交命令,提交应用程序
–class code.demo.spark.JavaWordCount:应用程序的主类
–master spark://hadoop-mn01:7077 :运行的master,跟本地测试local不一样
/home/hmaster/WordCount.jar:jar包所在路径
提交之后程序运行完后就能看到统计的结果:
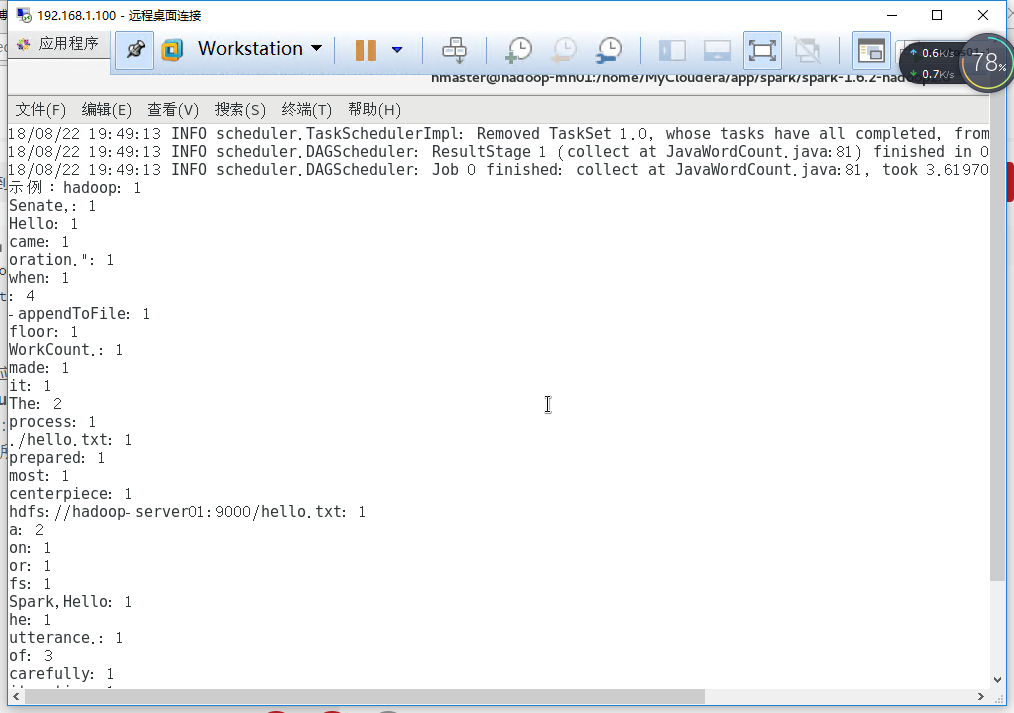
Hello WordCount!














 6366
6366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









