






一、计划表
PSP2.1
Personal Software Process Stages
预估耗时(分钟)
实际耗时(分钟)
Planning
计划
· Estimate
· 估计这个任务需要多少时间
400
690
Development
开发
· Analysis
· 需求分析 (包括学习新技术)
20
15
· Design Spec
· 生成设计文档
20
0
· Design Review
· 设计复审
20
30
· Coding Standard
· 代码规范 (为目前的开发制定合适的规范)
20
15
· Design
· 具体设计
20
30
· Coding
· 具体编码
60
90
· Code Review
· 代码复审
20
30
· Test
· 测试(自我测试,修改代码,提交修改)
20
120
Reporting
报告
· Test Repor
· 测试报告
120
240
· Size Measurement
· 计算工作量
20
30
· Postmortem & Process Improvement Plan
· 事后总结, 并提出过程改进计划
60
90
合计
400
690
二、 解题思路
题目要求:文本读写、词频统计。
文本读写用io库 ,读入字符串后用正则表达式或者自己写字符串分割函数或者封装好的分割函数来获取单词,词频统计用HashMap存,结果排序一下输出。
三、 设计实现
流程图如下:

主函数里调用各个功能。
单元测试:每个函数依次测试,测试通过后;整合到主函数里;然后用命令行窗口进行整体功能测试。
四、改进程序

 目前没怎么改进程序,由图中可以看见,Tool类之调用了一次,就是在主函数统计那一次。其余的就是排序跟文本读写,HashMap的插入与查找的性能消耗。
目前没怎么改进程序,由图中可以看见,Tool类之调用了一次,就是在主函数统计那一次。其余的就是排序跟文本读写,HashMap的插入与查找的性能消耗。
五、 代码说明
这是主函数,实现主要流程。
public class Main {
public static void main(String[] args) {
//文本读入
File file = new File(args[0]);
FileRead fileRead = new FileRead();
String data = fileRead.Input(file);
//处理文本
Tools tools = new Tools();
int length = data.length();
int wordAmount = tools.WordCount(data);
int lines = data.split("\n").length;
List> wordList = tools.WordSort();
//文本输出
fileRead.Output(length,wordAmount,lines,wordList);
}
}
Tool类中的词频统计:
调用了几个函数,StringTokenizer()——split()函数的加强版,也是用来分割字符串的;replaceAll()——替换部分非字母数字字符。
public int WordCount(String data){
int amount = 0;
String data_l = data.toLowerCase(); // 全部字母转小写。
String regex = "[^0-9a-zA-Z]"; //正则表达式,过滤非字母数字字符。
data_l = data_l.replaceAll(regex, " "); //清洗文本。
StringTokenizer words = new StringTokenizer(data_l); //分割文本成单词。
try {
while (words.hasMoreTokens()) {
String word = words.nextToken();
if (word.length() >= 4) { //判断单词长度是否大于等于4
if (Character.isLetter(word.charAt(0)) && Character.isLetter(word.charAt(1)) && Character.isLetter(word.charAt(2)) && Character.isLetter(word.charAt(3))) { //判断单词前4个是否为字母
amount++;
if (!wordCount.containsKey(word)) {
wordCount.put(word, new Integer(1));
} else {
int count = wordCount.get(word) + 1;
wordCount.put(word, count);
}
}
}
}
}catch (Exception e){
System.out.println("词频统计报错:");
System.out.println(e.getMessage());
}
return amount;
}
其他 FileRead就是一些文本处理,读与写。
六、异常处理
有基本的容错性: 根据输入的文件名找不到文件。
 文件过大,会数组越界无法读入,现已修复。顺带优化了读写的速度。 找了一个日志文件测试了一下。
文件过大,会数组越界无法读入,现已修复。顺带优化了读写的速度。 找了一个日志文件测试了一下。
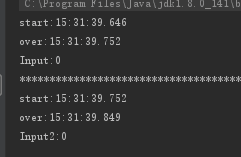
 调优:
调优:

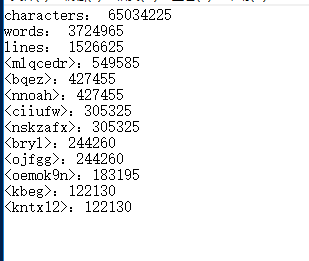
发现String通过"+"这种方法来拼接字符串是非常低效率的,于是用StringBuilder来代替。 附上几次的测试图:
七、总结
这次作业总体来说,花在写报告跟测试的时间比较多。而且对于词频统计这一问题来说,以前做过类似的oj题,但是算法题跟项目又是两码事,算法题只要做到最优能过测试就行,但是项目不一样。《构建之法》中提到的,“能证明所开发的软件是可以继续维护和发展的”,项目不仅仅做到满足用户需求,还要做到低耦合,无论是方便以后别人参与进来还是接手你的项目,都会更省时间。所以虽然花了很多时间,但是我觉得是有价值的。单元测试也是如此。














 3442
3442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









