






前言:本文基于与ChatGPT的对话学习和理解,由我个人整理而成。由于个人能力有限,难免可能存在一些错误。同时,也请您谅解其中可能存在的无意义与冗余内容。
目录
项目要求:
设计一个管理英文单词簿的程序。
(1)功能需求:
1)使用文件存储英文单词和该单词的中文解释,例如“sum, 大阳”“moon, 月亮”等。
2)可以向单词簿添加、修改、删除单词。
3)输入一个英文单词,可以查询对应的中文解释。
(2)数据组织及存储要求
1)单词薄存储在.txt文件中,增、删、改、查、浏览操作均对文件进行;
2)单词信息要求使用泛型集合方式,具体实现类型自定;
(3)界面设计要求(两种方式,选择一种)
1)在控制台输入、输出;
实现思路:
- 创建一个名为
FileManager的类,该类负责文件的读取和保存操作。其中,loadWordBook()方法用于从文件中加载单词簿,返回一个Map<String, String>类型的单词簿;saveWordBookToFile(Map<String, String> wordbook)方法用于将单词簿保存到文件中。 - 创建一个名为
InputHelper的类,该类负责用户输入的处理。其中,getChoice()方法用于获取用户选择的操作;consumeNewLine()方法用于消费输入中的换行符;getWordInput()和getMeaningInput()方法分别用于获取用户输入的单词和对应的中文解释。 - 创建一个名为
WordBookManager的类,该类是程序的主要控制类。其中,run()方法是程序的入口点,包含了程序的主要逻辑。在循环中,根据用户选择的操作执行相应的方法。 - 在
WordBookManager类中定义添加、修改、删除、查询、浏览操作的方法。这些方法会调用InputHelper类获取用户输入,并根据输入进行相应的操作。具体步骤如下:- 添加操作:获取用户输入的单词和中文解释,如果单词已存在于单词簿中,则提示单词已存在;否则,将单词和中文解释添加到单词簿中。
- 修改操作:获取用户输入的单词和中文解释,如果单词不存在于单词簿中,则提示单词不存在;否则,更新单词簿中该单词对应的中文解释。
- 删除操作:获取用户输入的单词,如果单词不存在于单词簿中,则提示单词不存在;否则,从单词簿中删除该单词。
- 查询操作:获取用户输入的单词,如果单词不存在于单词簿中,则提示单词不存在;否则,输出该单词对应的中文解释。
- 浏览操作:遍历单词簿,输出每个单词及其对应的中文解释。
- 在
WordBookManager类的main()方法中创建一个WordBookManager对象,并调用run()方法启动程序。
以上是基于控制台输入和输出的界面设计要求的实现思路。
项目介绍
目录结构
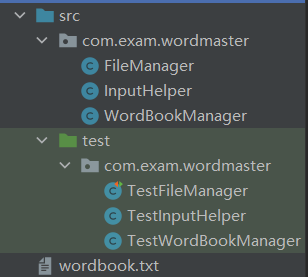
FileManager.java
public class FileManager {
private static final String FILE_PATH = "wordbook.txt"; // 单词簿文件路径
// 加载单词簿
public static Map<String, String> loadWordBook() {
Map<String, String> result = new HashMap<>(); // 存储加载的单词和对应的意思
File file = new File(FILE_PATH); // 创建一个File对象表示单词簿文件
if (file.exists()) { // 如果文件存在
try (BufferedReader reader = new BufferedReader(new FileReader(file))) {
String line;
while ((line = reader.readLine()) != null) { // 逐行读取单词簿文件内容
String[] parts = line.split(","); // 使用逗号分隔每个单词和对应的意思
if (parts.length == 2) { // 如果分割后得到两个部分
String word = parts[0].trim(); // 去除空格后的单词
String meaning = parts[1].trim(); // 去除空格后的意思
result.put(word, meaning); // 将单词和意思存储到result中
}
}
} catch (IOException e) {
System.out.println("无法从文件中读取单词簿");
e.printStackTrace();
}
}
return result; // 返回加载的单词簿
}
// 将单词簿保存到文件
public static void saveWordBookToFile(Map<String, String> wordbook) {
try (FileWriter writer = new FileWriter(FILE_PATH)) { // 创建一个文件写入流
for (Map.Entry<String, String> entry : wordbook.entrySet()) {
// 将每个单词和意思以逗号分隔并写入文件
writer.write(entry.getKey() + ", " + entry.getValue() + "\n");
}
System.out.println("单词簿已保存到文件");
} catch (IOException e) {
System.out.println("无法将单词簿保存到文件");
e.printStackTrace();
}
}
}
private static final String FILE_PATH = "wordbook.txt";
static关键字用于声明类成员,表示该成员与类相关联(类级别访问),而不是与对象实例相关联。因此,在private static final String FILE_PATH中的static关键字的作用是将FILE_PATH字符串与类相关联,而不是与对象实例相关联。这意味着在类的任何地方,无论创建多少个对象实例,都只会存在一个
FILE_PATH的拷贝。这样做有以下几个好处:
节省内存:由于
FILE_PATH只需要一份拷贝,而不是每个对象实例都有自己的拷贝,因此节省了内存空间。具有全局性:
static成员可以通过类名直接访问,而不需要创建对象实例。这意味着其他类甚至不需要创建FileManager对象实例,就可以使用FILE_PATH字符串。一致性:由于
FILE_PATH是静态的,它的值在整个程序运行期间保持不变。这对于需要在多个地方使用相同路径的情况非常有用,可以确保使用的始终是同一个路径。总结来说,使用
static将FILE_PATH字符串与类相关联,而不是与对象实例相关联,节省了内存,提供了全局性和一致性的访问方式。这样的设计在许多实际应用中都是非常有用的。
final常量,
FILE_PATH被声明为一个私有的静态常量,并且其初始值为"wordbook.txt"。这意味着无论在任何时候,在代码的其他部分都无法对该常量进行修改。这并不意味着你不能对文件本身进行增删查改操作。
FILE_PATH只是一个指向文件路径的字符串常量。如果你需要对文件进行增删查改操作,可以使用其他方法和工具来完成,但要注意不要直接修改FILE_PATH本身。
FILE_PATH = "wordbook.txt",位于项目名之下,与src同一级
Map<String, String> result = new HashMap<>();这行代码在声明一个变量result,它的类型是Map<String, String>,表示这个变量可以存储键是字符串类型,值也是字符串类型的映射关系。
Map是 Java 中提供的一种数据结构,用于存储键值对的集合。它提供了快速的查找功能,可以通过给定的键来获取对应的值。<String, String>表示这个Map存储的键和值都是字符串类型。第一个String表示键的类型,第二个String表示值的类型。
HashMap是Map接口的一个具体实现类,用于存储键值对。它使用哈希表作为底层数据结构,在大多数情况下提供了快速的插入、删除和查找操作。所以,
Map<String, String> result = new HashMap<>();这行代码意味着我们创建了一个新的空的HashMap对象,并将其赋值给变量result。在这个程序中,result用于存储加载的单词簿中的单词和对应的意思。
Map<String, String> result = new HashMap<>();
HashMap<Object, Object> map = new HashMap<>();
在上述代码中,第一行创建了一个
Map对象,并使用泛型指定了键和值的类型为String,并且选择使用了HashMap来实现这个Map对象。第二行则直接创建了一个HashMap对象,没有使用泛型。两者的主要区别如下:
泛型指定:第一个使用了泛型
<String, String>,指定了键和值的类型为String,这样可以在编译时进行类型检查,避免了类型错误。而第二个没有使用泛型,键和值的类型是Object,需要在运行时进行类型转换,存在类型安全性的风险。可读性和可维护性:使用泛型的代码更加清晰和可读,因为明确了键和值的类型。这有助于其他开发人员快速理解代码的含义和功能。同时,使用泛型也提供了更好的代码可维护性,因为可以在编码时就捕捉到类型错误。
编译器优化:在使用泛型的情况下,编译器可以对代码进行更多的类型检查,并提供更好的编译器优化。这可能会带来更高的性能或更少的内存占用。
总结来说,使用第一个方式创建
Map对象,即Map<String, String> result = new HashMap<>();,在类型安全性、代码可读性和可维护性方面更优于第二个方式。虽然第二个方式在某些特定场景下可能也是可行的,但建议在实际开发中尽量使用第一个方式来创建Map对象。
try (BufferedReader reader = new BufferedReader(new FileReader(file)))使用了
try-with-resources来处理文件读取操作。具体来说,BufferedReader(缓冲区读取)和FileReader(字符流)都实现了AutoCloseable接口,因此可以在try语句中创建并打开这两个资源,并在代码块结束后自动关闭它们。
FileReader是用于打开和读取文件的类,而BufferedReader则是通过对FileReader对象进行包装,提供了缓冲和按行读取文件的功能,使文件读取更加高效和方便。使用BufferedReader可以一次读取多个字符,减少了对硬盘的频繁访问,提高了读取效率。代码的执行流程如下:
首先,创建一个
File对象(假设命名为file),它表示要读取的文件。进入
try代码块。在
try代码块中,使用嵌套构造函数创建了一个BufferedReader对象。内部的FileReader对象是为了将File对象传递给BufferedReader对象,以便能够读取文件内容。执行
try代码块中的逻辑,即使用BufferedReader对象从文件中读取内容。可以使用reader.readLine()方法逐行读取文件内容,并对其进行处理。当代码块执行完毕或者发生异常时,会自动调用
BufferedReader和FileReader对象的close()方法。这样就会自动关闭文件读取流,确保文件资源得到正确释放。简而言之,
try-with-resources语句会在代码块执行完毕或发生异常时,自动关闭实现了AutoCloseable接口的资源。在你提供的代码中,BufferedReader和FileReader都实现了AutoCloseable接口,所以它们会在try代码块结束后自动关闭。这种语法结构的好处是,你不必手动编写关闭资源的代码,避免了因为忘记关闭资源导致的资源泄漏问题。同时,当有多个资源需要关闭时,它们会按照创建的顺序逆序地关闭,即先关闭
BufferedReader,再关闭FileReader。
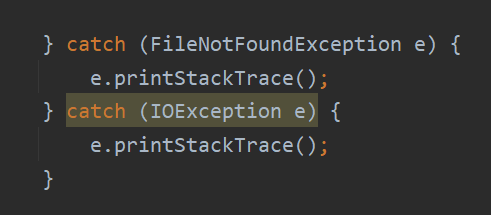
这段代码是 Java 中的异常处理代码块,用于捕获和处理可能出现的异常。在这个特定的代码块中,使用了两个
catch块来处理不同类型的异常。
第一个
catch块用于捕获并处理FileNotFoundException类型的异常。当在尝试打开文件时发生文件未找到的错误时,会抛出FileNotFoundException异常。在这个catch块中,使用e.printStackTrace()方法【打印堆栈跟踪】将异常信息输出到控制台以便进行调试和错误追踪。第二个
catch块用于捕获并处理IOException类型的异常,它是FileNotFoundException的父类。IOException是输入输出操作中可能发生的各种异常的通用基类。在这个catch块中同样使用了e.printStackTrace()方法来输出异常信息。
将会以逗号作为分隔符来拆分line字符串,并返回拆分后的字符串数组parts。
line.split(",")将会以逗号作为分隔符来拆分
line字符串,并返回拆分后的字符串数组parts。例如,如果
line的值为"apple,苹果"(wordbook.txt里的内容都是以"××,××"为格式),那么调用line.split(",")会将其拆分成一个包含两个元素的字符串数组:
parts[0]:"apple"parts[1]:"苹果"数组的索引从0开始,因此
parts[0]表示拆分后的第一个部分(即单词),parts[1]表示拆分后的第二个部分(即意思)。这样,通过使用逗号作为分隔符进行拆分,就可以将每行中的单词和对应的意思分别存储到
word和meaning变量中。
FileReader与FileWriter类似,都是用于文件的读写操作。但是它们的功能不同:
FileReader:用于从文件中读取字符数据,继承自InputStreamReader。可以通过read()方法一次读取一个字符或一个字符数组,并将其返回。FileWriter:用于向文件中写入字符数据,继承自Writer。可以通过write()方法一次写入一个字符、一个字符数组、一个字符串或字符串的一部分。总结而言,
FileReader用于读取文件数据,而FileWriter用于写入文件数据。
for (Map.Entry<String, String> entry : wordbook.entrySet()) {
这段代码使用了 for-each 循环来遍历
wordbook中的每个键值对(单词和意思)。让我们逐步解释一下代码的执行过程:(entry 条目;入口;entrySet 条目集合)
wordbook.entrySet():首先,通过entrySet()方法获取了wordbook的键值对集合。entrySet()方法返回一个包含Map.Entry对象的集合,其中每个Map.Entry对象表示一个键值对。
Map.Entry<String, String> entry:在 for-each 循环的声明部分,我们定义了一个类型为Map.Entry<String, String>的变量entry。Map.Entry是一个嵌套在Map接口中的键值对的静态内部类。Map.Entry包含了getKey()和getValue()方法,分别用于获取键和值。在这种情况下,String表示键和值的类型。
: wordbook.entrySet()::符号将entry与wordbook.entrySet()关联起来,表示我们将按顺序遍历wordbook.entrySet()中的每个元素,并将当前元素赋值给entry。
{}内的循环体:循环体内的代码将针对每个键值对进行迭代处理。在每次迭代期间,我们可以使用entry.getKey()获取当前键,使用entry.getValue()获取当前值,然后进行相应的操作。总结来说,使用
for (Map.Entry<String, String> entry : wordbook.entrySet())可以方便地遍历wordbook中的键值对,并在循环体内使用entry.getKey()和entry.getValue()对键值对进行操作。
for-each循环(也称作增强型for循环)是 Java 提供的一种简化迭代集合或数组的语法结构。它提供了一种更加方便和简洁的方式来遍历集合中的元素,而无需显式使用迭代器或索引。
for-each循环的基本语法如下:for (element_type element : collection) {
/ /循环体代码 }
其中,
element_type是集合元素的数据类型,element是表示当前迭代元素的变量名,collection是要遍历的集合或数组。
for-each循环的工作原理如下:
- 从集合或数组中获取迭代器(对于集合)或直接访问元素(对于数组)。
- 依次取出集合或数组中的每个元素,并将其赋值给
element变量。- 执行循环体内的代码,针对每个元素进行操作。
- 循环继续,直到遍历完集合或数组中的所有元素。
for-each循环适用于需要顺序遍历集合或数组中的元素,而不需要索引的场景。它提供了一种简洁、安全、避免了索引越界问题的方式来迭代处理元素。需要注意的是,
for-each循环不支持在循环体内修改集合或数组的结构,例如添加或删除元素。如果需要进行结构变更,请使用传统的for循环或迭代器。
TestFileManager.java
public class TestFileManager {
// 单词簿路径
private static final String FILE_PATH = "wordbook.txt";
// 测试文件路径是否正确
public static void main(String[] args) {
File file = new File(FILE_PATH);
if (file.exists()) {
System.out.println("路径正确");
} else {
System.out.println("路径错误");
}
}
// 测试加载单词簿方法
@Test
public void testLoadWordBook() {
// 调用被测试方法
Map<String, String> wordBook = FileManager.loadWordBook();
int size = wordBook.size();
System.out.println(size);
wordBook.put("zoo", "动物园");
String s = wordBook.get("zoo");
System.out.println(s);
System.out.println(size);
}
// 测试保存单词簿到文件方法
@Test
public void testSavaWordBookToFile() {
Map<String, String> wordBook = FileManager.loadWordBook();
System.out.println(wordBook.size());
wordBook.put("sun", "太阳");
wordBook.put("moon", "月亮");
FileManager.savaWordBookToFile(wordBook);
System.out.println(wordBook.size());
}
}
InputHelper.java
public class InputHelper {
private static final Scanner scanner = new Scanner(System.in);
public static int getChoice() {
System.out.println("请选择操作:1.添加单词 2.修改单词 3.删除单词 4.查询单词 5.浏览单词簿 6.退出");
return scanner.nextInt();
}
public static void consumeNewLine() {
/* 消费掉多余的换行符
将输入从可用状态转移到不可用状态,以确保后续操作的正确执行。*/
scanner.nextLine();
}
public static String getWordInput() {
System.out.println("请输入要操作的单词:");
// 先消费掉多余的换行符
consumeNewLine();
// 再输出返回结果
return scanner.nextLine().trim();
}
public static String getMeaningInput() {
System.out.println("请输入该单词的中文解释:");
consumeNewLine();
return scanner.nextLine().trim();
}
}在代码中,
private static final Scanner scanner = new Scanner(System.in);中的private、static和final是对该变量进行修饰的关键词。
private:表示该变量被声明为私有的,只能在当前类内部被访问。私有变量的作用是封装数据,限制对其直接的访问和修改,使得只能通过类内部的方法来进行操作。
static:表示该变量被声明为静态的,它属于整个类而不是特定对象。静态变量在类加载时就会被初始化,并且可以在整个应用程序的生命周期内被访问和共享。在这个例子中,将scanner声明为静态变量是因为它需要在类的静态方法中使用。
final:表示该变量被声明为常量,一旦赋值后就不能再被修改。常量在程序运行过程中保持不变,使用它可以提高代码的可读性和安全性。在这个例子中,scanner被声明为final是因为我们希望在整个程序中都使用同一个Scanner对象,避免创建多个实例造成资源浪费或混乱。综上所述,
private static final Scanner scanner = new Scanner(System.in);的作用是创建一个私有、静态、常量的Scanner对象,该对象可以在当前类的静态方法中被访问,且一旦初始化后不能再被修改。
消费可以通过一个比喻来解释。想象一下你坐在餐厅里点菜的情景。
当你点完菜之后,服务员将菜单收走并记录你的点菜信息。这时,你已经消费了菜单上的信息,因为你已经使用它来选择你想要的菜品,并且没有进一步使用它的计划。
在这个比喻中,菜单就是输入,而点菜的过程就相当于消费输入。一旦你完成点菜,菜单的作用就结束了,它被移除或丢弃了,无法再次使用。这就是消费的概念。
在计算机编程中,消费的方式根据不同的输入类型而有所不同。以下是几个常见的消费输入的例子:
字符串:对于字符串输入,可以通过读取并存储字符串的值,将其从可用状态变为不可用状态。例如,通过调用
inputString = scanner.nextLine(),你将消费了输入中的一行字符串,因为它已经被存储到inputString变量中,并且无法再次使用。数字:对于数字输入,可以通过读取数字并进行计算或使用,将其从可用状态变为不可用状态。例如,通过调用
int number = scanner.nextInt(),你将消费了输入中的一个整数,因为它已经被存储到number变量中,并且无法再次使用。文件:对于文件输入,可以通过逐行读取文件内容,并将每一行进行处理或存储,将其从可用状态变为不可用状态。例如,你可以使用循环遍历文件的每一行,而每一行都被认为是已消费的。
总结来说,消费就是处理输入数据,将其从可用状态变为不可用状态的过程。消费的方式可以因输入类型的不同而有所不同,但核心思想是将输入从可用状态转移到不可用状态,以确保后续操作的正确执行。
TestInputHelper.java
public class TestInputHelper {
public static void main(String[] args) {
int choice = InputHelper.getChoice();
System.out.println("选择的操作序号为:" + choice);
System.out.println("");
String word = InputHelper.getWordInput();
System.out.println("输入的单词为:" + word);
System.out.println("");
String meaning = InputHelper.getMeaningInput();
System.out.println("输入的中文意思为:" + meaning);
System.out.println("");
}
}
WordBookManager.java
public class WordBookManager {
private final Map<String, String> wordbook;
// 放在构造方法之中,确保能够正确的进行初始化
public WordBookManager() {
wordbook = FileManager.loadWordBook();
}
// 执行操作
private void run() {
boolean keepRunning = true;
while (keepRunning) {
int choice = InputHelper.getChoice();
switch (choice) {
case 1:
addWord();
break;
case 2:
deleteWord();
break;
case 3:
queryWord();
break;
case 4:
modifyWord();
break;
case 5:
displayWordBook();
break;
case 6:
keepRunning = false;
FileManager.savaWordBookToFile(wordbook);
break;
default:
System.out.println("无效的操作,请重新输入");
break;
}
}
}
// 增
public void addWord() {
String word = InputHelper.getWordInput();
// contains 包含
if (wordbook.containsKey(word)) {
System.out.println("单词已存在");
return;
}
String meaning = InputHelper.getMeaningInput();
wordbook.put(word, meaning);
System.out.println(word + " 已添加到单词簿");
}
// 删
public void deleteWord() {
String word = InputHelper.getWordInput();
if (!wordbook.containsKey(word)) {
System.out.println("单词不存在");
return;
}
wordbook.remove(word);
System.out.println(word + " 已从单词簿中删除");
}
// 查
public void queryWord() {
String word = InputHelper.getWordInput();
if (!wordbook.containsKey(word)) {
System.out.println("单词不存在");
return;
}
String meaning = wordbook.get(word);
System.out.println("该单词的中文意思为:" + meaning);
}
// 改
public void modifyWord() {
String word = InputHelper.getWordInput();
if (!wordbook.containsKey(word)) {
System.out.println("单词不存在");
return;
}
String meaning = InputHelper.getMeaningInput();
wordbook.put(word, meaning);
System.out.println(word + " 的中文解释已修改");
}
// 展示
public void displayWordBook() {
if (wordbook.isEmpty()) {
System.out.println("单词簿为空");
return;
}
System.out.println("单词\t中文翻译");
for (Map.Entry<String, String> entry : wordbook.entrySet()) {
System.out.println(entry.getKey() + "\t" + entry.getValue());
}
}
// 主函数
public static void main(String[] args) {
WordBookManager wordBookManager = new WordBookManager();
wordBookManager.run();
}
}在代码中,
public WordBookManager()方法是一个构造方法,用于在创建WordBookManager对象时初始化wordbook字段。这个构造方法会调用FileManager.loadWordBook()方法来加载保存的单词簿文件,并将返回的单词簿对象赋值给wordbook字段。为什么要将加载单词簿文件的逻辑放在构造方法中而不是直接在类体中赋值呢?
这是因为构造方法会在创建对象的时候自动调用,确保每次创建
WordBookManager对象时,wordbook字段都被正确地初始化。而将加载单词簿文件的逻辑放在类体中,则会导致在创建对象后才执行,可能会出现先访问wordbook字段而未加载文件内容的情况。因此,通过在构造方法中调用
FileManager.loadWordBook()方法,可以确保在创建WordBookManager对象时,wordbook字段被正确地初始化为保存的单词簿内容。这样,在调用其他方法时,就可以直接使用wordbook字段来进行单词簿的增删改查等操作了。
在这段代码中,
WordBookManager类有一个wordbook字段,用于存储单词和对应的中文解释。在类体中直接初始化wordbook字段的方式是这样的:private Map<String, String> wordbook = FileManager.loadWordBook();
这种方式会导致在创建
WordBookManager对象时,先执行字段初始化,然后再执行构造方法。在字段初始化时,会调用FileManager.loadWordBook()方法来加载保存的单词簿文件并将其赋值给wordbook字段。但问题是,如果加载文件的操作耗时较长,而且在创建对象时需要立即开始使用
wordbook字段进行其他操作,那么在字段初始化期间,wordbook字段可能还未被正确地初始化为文件内容,这可能导致错误或异常。为了避免这个问题,可以将加载文件的逻辑放在构造方法中,如下所示:
public WordBookManager() { wordbook = FileManager.loadWordBook(); }
通过将加载文件的操作放在构造方法中,确保了在创建
WordBookManager对象时,文件已经被正确地加载到wordbook字段中,从而避免了使用未正确初始化的数据的风险。















 3610
3610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









