






 本文是AI实操系列的第三篇,主要介绍数据获取——爬虫技术,包括如何使用requests和lxml获取与解析网页内容,以及简单爬虫的基本组成。文章以豆瓣电影和故宫壁纸为例,讲解了爬取网页数据、解析HTML和存储数据的基本步骤,旨在帮助读者入门爬虫知识。
本文是AI实操系列的第三篇,主要介绍数据获取——爬虫技术,包括如何使用requests和lxml获取与解析网页内容,以及简单爬虫的基本组成。文章以豆瓣电影和故宫壁纸为例,讲解了爬取网页数据、解析HTML和存储数据的基本步骤,旨在帮助读者入门爬虫知识。

嘿,我又来啦!

小伙伴们是不是都等不及要动手实践了呢?
来吧来吧,咱们一起开始吧!
按照惯例,本攻又双叒来带着大家回顾一下问题吧!
为了让你们更便捷地学习
(内心:别嫌弃我逻辑混乱呀!)
本攻也是操碎了心呐!

问题一、分析什么数据以及目的是什么?
问题二、如何获取这些数据?
问题三、用什么工具分析数据?
问题四、如何分析这些数据?
前面的两篇已经带领大家解决了问题一和三(点击下方标题查看往期文章)
AI实操|数据分析之环境部署篇
AI实操|数据分析之工程创建篇
这两个问题虽然很枯燥无味但也是后面问题的基础
大家一定要明确目标
以及学会如何使用Python与IDE(Pycharm)等工具哦!

别说了别说了,快开始吧!

那还不买票上车,我们要开始收拾问题二啦!

这一篇的内容非常地有趣哦!
本攻将讲述一种很潮的技术——爬虫。
. . .
这里的爬虫不是动物哦!
爬虫在计算机领域说的是一类程序,
用来完成特定内容访问与存储的功能,
因此可以通过爬虫轻松获取并归总我们感兴趣的内容。
但是小伙伴们一定要谨慎对待这项技术,
因为恶意的爬虫行为是违法的。

记住最重要的一点
爬虫是在获取公开的信息!
因此在爬虫之前
我们要谨慎地考虑
将进行爬取的信息是否侵犯隐私
以及是否公开
(其实,以本攻的功力,隐私信息和非公开数据我也爬不到,哈哈哈)

还有些注意事项这里就不展开说明了
总而言之,应用爬虫要谨而慎之
. . .
也许大家都认为“爬虫”技术离我们很远吧,
其实,我们每天都在用这个工具,也就是搜索引擎比如某度和某歌。
搜索引擎就是通过爬虫技术来索引互联网内容的。
接下来,本攻将分别举例介绍简单爬虫的组成部分!
本攻今天主要带领大家完成三项任务
第一:如何爬取页面数据;
第二:如何解析爬取的页面得到感兴趣的内容;
第三:如何存储爬取的数据;
爬虫爬取的到底是什么呢?
这位同学问的好。首先本攻先说明一下网页的组成~
浏览器中看到的网页
实质上是由HTML代码构成的
在浏览器页面通过鼠标右键
可以看到网页源代码选项
然后就能看到HTML代码啦!
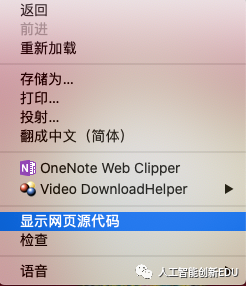
爬虫所获取的内容便是显示的网页源代码
然后通过分析和过滤这些内容
最后获取我们需要的图片或者文字资源
. . .
实际上爬虫涉及的知识还是蛮多的,包括了HTTP协议、HTML语言、正则表达式(用于筛选数据,本篇介绍了更便捷的xpath工具筛选数据)、数据库(存储数据)等等等等。。。
想要深入了解的同学还需要坚持学习呀!
这里本攻只是带大家入门了解,
相关的代码也只是实现最基础的功能。
想要更多需求的小伙伴可以了解相关的爬虫框架scrapy。

正片开始!
首先我们准备好制作爬虫的材料(工具):
一、requests功能包(用于获取页面)
二、lxml功能包用于解析(筛选)HTML文件内容
三、pandas与faker功能包(生成假数据并存储数据到表格文件)
其中lxml、requests、faker与pandas功能包需要额外安装,学习过上篇内容的同学对于这件小事应该不在话下了。
注意:以下所有代码都是Python3.6及以上版本支持。
一、 首先利用requests功能包来获取到网页的内容(HTML)
这里我只涉及两种类型的页面:
一种不需要登录的页面内容获取。
一种则是需要用户名和密码登录(不需要验证码)的页面内容获取。
现在很多需要登录的页面都是需要提供验证码输入,目的就是为了反爬虫,这里就不多介绍这部分内容了,感兴趣的小伙伴自行搜索相关技术哦!
我们利用requests库获取无需登录的页面内容,
这里本攻以豆瓣电影(https://movie.douban.com/)的页面作为案例。
import requests
sess = requests.Session() # 建立会话
# http协议请求头
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
url_movie = 'https://movie.douban.com/'
# get方法获取页面信息
html_movie = sess.get(url_movie, headers=headers).text
print(html_movie)
之后我们登录豆瓣账号之后获取个人信息的页面内容。
import requests
sess = requests.Session()
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'}
url = 'https://accounts.douban.com/j/mobile/login/basic' #这是登录填写表单的地址
data = {
'ck': '',
'name': '*********', # 账号
'password': '**********', # 密码
'remember': 'false',
'ticket': '',
}
# 使用post方法填写表单登录信息
html_login = sess.post(url, headers=headers, data=data)
url_info = 'https://www.douban.com/people/54363998/'
html_info = sess.get(url_info, headers=headers).text
print(html_info)
二、 接下来,开始解析获取到的页面信息啦!
本攻就以下面的HTML代码作为例子,介绍常用的解析工具和方法
(这里就不抓取具体网站的页面了,原理都是相同的,感兴趣的同学可以尝试去抓取平时浏览的网页吧!)
这里本攻推荐一个lxml功能包中的xpath工具用来解析页面。
本攻先以下面的HTML代码介绍一下其结构,这样大家就能相对容易的理解下面xpath相关的语法功能了。
测试页面科大讯飞
人工智能改变世界
AI创新教育
遇见AI,预见未来
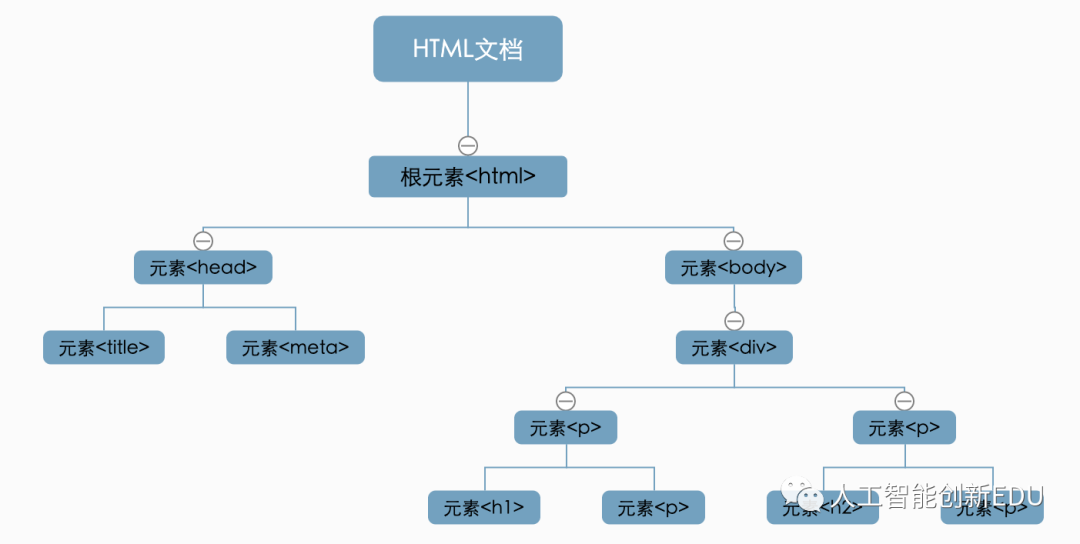
节点之间的关系如下:
父节点(Parent):HTML是body和head节点的父节点;
子节点(Child):head和body是HTML的子节点;
兄弟节点(Sibling):拥有相同的父节点,head和body就是兄弟节点。title和div不是兄弟,因为他们不是同一个父节点;
祖先节点(Ancestor):body是p|h1|h2的祖先节点,爷爷辈及以上;
后代节点(Descendant):p|h1|h2是HTML 的后代节点,孙子辈及以下。
下面开始介绍xpath的常用语法与相关实例
常用语法:
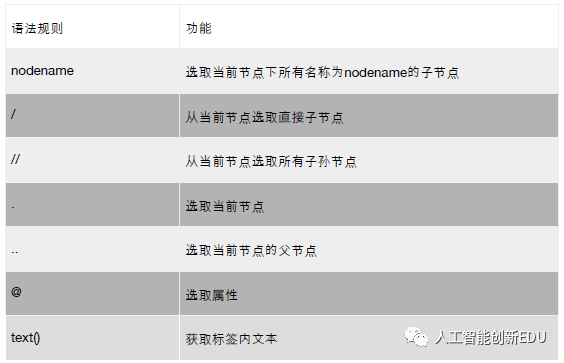
相关实例:
from lxml import etree
html= """
测试页面科大讯飞
人工智能改变世界
AI创新教育
遇见AI,预见未来
"""
html_parse = etree.HTML(html)
# nodename与//
html_extract = html_parse.xpath('//p')
print(html_extract)
# /
html_extract = html_parse.xpath('/html/head/title')
print(html_extract)
# .与..
html_extract = html_parse.xpath('//div/..')
print(html_extract)
# @
html_extract = html_parse.xpath('//h1//@lang')
print(html_extract)
# text()与|
html_extract = html_parse.xpath('//h1//text()|//h2//text()')
print(html_extract)
小伙伴们按照上面的代码可以很清晰地了解常用的规则
如果有更多需求的话
大家可以自行搜索相关文档哦~
互联网上有很多相关资源
这里本攻就不提供具体文档地址了
三、 最后存储爬取的数据,这里介绍存储两类数据(结构化数据与非结构化数据)的方式
结构化数据指的是以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的,一般存储在关系型数据库或者结构化存储在本地表格文件;
非结构化数据呢?就是没有固定结构的数据。各种文档、图片、视频/音频等都属于非结构化数据。对于这类数据,我们一般存储为二进制的数据格式。
本攻举两个栗子分别说明这两种情况

01
结构化数据
首先存储结构化数据
结构化数据可以通过Faker功能包进行自动生成
然后利用pandas库处理并存储为csv格式文件
(Faker功能包文档地址:https://faker.readthedocs.io/en/master/index.html)
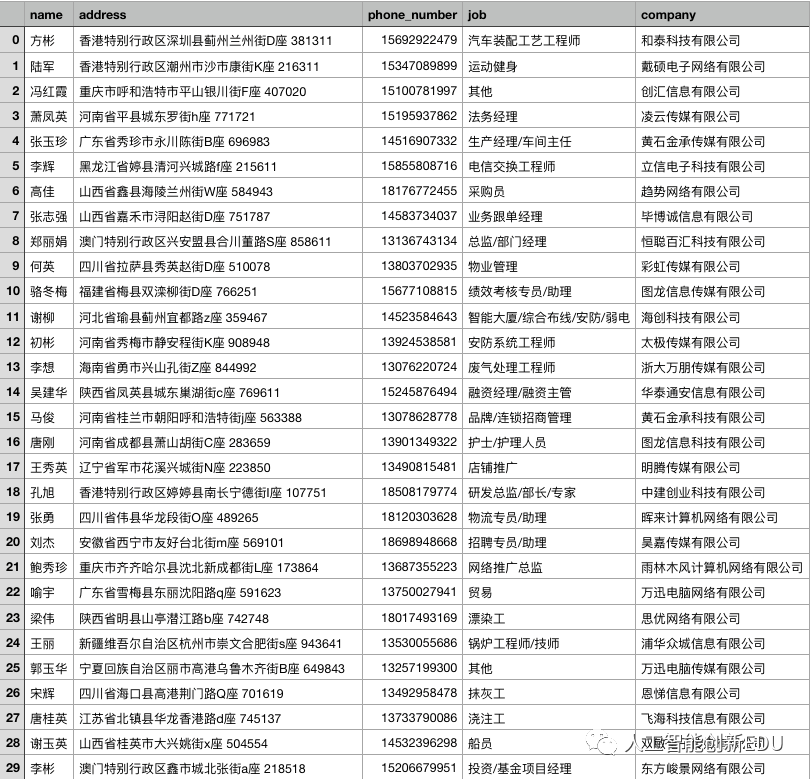
先贴一张处理得到的表格部分数据截图
里面的数据应该不是真实的吧
哈哈哈
都是Faker功能包自动生成的
当大家想获取某个网站中类似下图中的结构化数据,
而又不想一条一条的复制粘贴的时候,
爬虫技术你就值得拥有啦!
from faker import Faker
import pandas as pd
fake = Faker(locale='zh_CN') # 生成中文数据
names = []
addresses = []
phone_numbers = []
jobs = []
companys = []
for count in range(100):
name = fake.name() # 姓名
address = fake.address() # 地址和邮编
phone_number = fake.phone_number() # 手机号码
job = fake.job() # 工作
company = fake.company() # 公司
names.append(name)
addresses.append(address)
phone_numbers.append(phone_number)
jobs.append(job)
companys.append(company)
data = pd.DataFrame(
{'name': names, 'address': addresses, 'phone_number': phone_numbers, 'job': jobs, 'company': companys})
data.to_csv('info.csv') # 保存成csv表格格式
02
非结构化数据
接下来本攻带领大家存储非结构化图片类型的数据
比如故宫博物院网站超好看的古风壁纸!
让本攻仔细挑挑该下载哪些壁纸
太难选择了!
 都很好看啊!
都很好看啊!
既然这样,那都给下载咯!
可是一百多页的壁纸手动点击下载不得累死本攻啊!
这时本攻机智的小脑袋瓜想到了爬虫
下面的部分便是本攻之前批量下载
故宫博物院(https://www.dpm.org.cn/lights/royal/)网站的古风壁纸代码了
小伙伴们可别频繁的爬取以免加重网站的压力哦!
自己悄咪咪地下载一点点就好啦!
先贴一张好看的壁纸给你们康康!

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@author: Liu yang
@contact:liuyang@iflytek.com
@version: 1.0.0
@license: Apache Licence
@file: crawler.py
@time: 2020/4/6 21:09
"""
import os
from threading import Thread
import datetime
import requests
from lxml import etree
class Spider(object):
def __init__(self, file_path, nums):
self.name = {}
self.nums = nums
if not os.path.exists(file_path):
os.mkdir(file_path)
self.file_path = file_path
self.header = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
def timer(func):
def time_count(*args):
start_time = datetime.datetime.now()
func(*args)
end_time = datetime.datetime.now()
times = (end_time - start_time).seconds
hour = times / 3600
h = times % 3600
minute = h / 60
m = h % 60
second = m
print("爬取完成")
print(f"一共用时:{hour:2.0f}时{minute:2.0f}分{second}秒")
return time_count
def get_link(self):
pages = []
for i in range(1, self.nums + 1):
pic_links = []
page = 'https://www.dpm.org.cn/lights/royal/p/' + str(i) + '.html'
html = requests.get(page, self.header).text
html_node = etree.HTML(html)
elements_links = html_node.xpath(
'//div[@]//a[@target="_blank"]//@href')
elements_name = html_node.xpath('//a[@target="_blank"]//img//@alt')
for elements_link in elements_links:
pic_page_html = requests.get(f'https://www.dpm.org.cn{elements_link}', headers=self.header)
pic_html_node = etree.HTML(pic_page_html.text)
pic_link = str(pic_html_node.xpath('//img[@style]//@src')[0])
if pic_link.startswith('https'):
pass
else:
pic_link = 'https://www.dpm.org.cn' + pic_link
pic_links.append(pic_link)
print(f'\r获取第{i}页内容:{pic_links}', end='')
pages.append(zip(pic_links, elements_name))
return pages
def download(self, link):
count = 0
try_times = 0
if link[1] not in self.name.keys():
filename = f'{link[1]}.jpg'
self.name[link[1]] = count + 1
else:
filename = f'{link[1]}({self.name[link[1]]}).jpg'
self.name[link[1]] = self.name[link[1]] + 1
link_full = link[0]
try:
while True:
if try_times == 5:
break
pic = requests.get(link_full, headers=self.header)
if pic.status_code == 200:
with open(os.path.join(self.file_path) + os.sep + filename, 'wb') as fp:
fp.write(pic.content)
fp.close()
if int(pic.headers['content-length']) != len(pic.content):
print(f"{filename}下载失败,重新下载")
try_times += 1
else:
print(f"{filename}下载成功")
break
except Exception as e:
print(e)
@timer
def run_main(self):
threads = []
pages = self.get_link()
for links in pages:
for link in links:
t = Thread(target=self.download, args=[link, ])
t.start()
threads.append(t)
for t in threads:
t.join()
if __name__ == '__main__':
file_path = './wallpaper'
spider = Spider(file_path, 10) # 10为下载页面数量,默认从第一页开始
spider.run_main()
以上的代码以及相关内容都是仅供参考,
本攻可能没有顾及到部分细节问题,
有什么疑问还请小伙伴们指出来,
本攻一定改!

小伙伴们,完成了上面的三个任务之后,
是不是对数据爬虫有了一定的了解呢?
完成这阶段之后,只剩最后一个问题啦!
胜利就在眼前啦!
冲冲冲!
照旧,本攻预告一下下期内容
之后一期的内容将会是本系列最后一篇
并且也是最精彩、最炫酷和最重要的一部分了,
期待么?
下期将分成两部分:
1、使用pandas功能包进行数据清洗
(包括缺失值处理、格式一致化以及调整数据类型等)
2、使用seaborn功能包进行数据可视化,进而分析数据分布并得出结论。

The End
更多关注:科大讯飞 人工智能创新教育
作者:杨柳
审核:王雨蒙
编辑:段云侠 蒋小庆 王聪
(文中部分图源网络,侵删)

扫码关注我们
点一下你会更好看耶
















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









