







 001.HTTP报文结构是怎样的 ?于 TCP 而言,在传输的时候分为两个部分:TCP头和数据部分。而 HTTP 类似,也是header + body的结构,具体而言:起始行 + 头部 + 空行 + 实体由于 http 请求报文和响应报文是有一定区别,因此我们分开介绍。起始行:对于请求报文来说,起始行类似下面这样:GET /home HTTP/1.1复制代码也就是方法 + 路径 + http版本。...
001.HTTP报文结构是怎样的 ?于 TCP 而言,在传输的时候分为两个部分:TCP头和数据部分。而 HTTP 类似,也是header + body的结构,具体而言:起始行 + 头部 + 空行 + 实体由于 http 请求报文和响应报文是有一定区别,因此我们分开介绍。起始行:对于请求报文来说,起始行类似下面这样:GET /home HTTP/1.1复制代码也就是方法 + 路径 + http版本。...
001.HTTP报文结构是怎样的 ?
于 TCP 而言,在传输的时候分为两个部分:TCP头和数据部分。
而 HTTP 类似,也是header + body的结构,具体而言:
起始行 + 头部 + 空行 + 实体由于 http 请求报文和响应报文是有一定区别,因此我们分开介绍。
起始行:
对于请求报文来说,起始行类似下面这样:
GET /home HTTP/1.1复制代码也就是方法 + 路径 + http版本。
对于响应报文来说,起始行一般张这个样:
HTTP/1.1 200 OK复制代码响应报文的起始行也叫做状态行。由http版本、状态码和原因三部分组成。
值得注意的是,在起始行中,每两个部分之间用空格隔开,最后一个部分后面应该接一个换行,严格遵循ABNF语法规范。
头部:
展示一下请求头和响应头在报文中的位置:
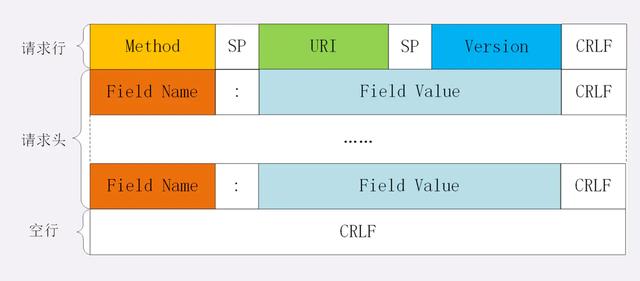

不管是请求头还是响应头,其中的字段是相当多的,而且牵扯到http非常多的特性,这里就不一一列举的,重点看看这些头部字段的格式:
- 字段名不区分大小写
- 字段名不允许出现空格,不可以出现下划线_
- 字段名后面必须紧接着:
空行:
很重要,用来区分开头部和实体。
问: 如果说在头部中间故意加一个空行会怎么样?
那么空行后的内容全部被视为实体。
实体:
就是具体的数据了,也就是 body 部分,请求报文对应 请求体,响应报文对应 响应体;
002.如何理解 HTTP 的请求方法 ?
有哪些请求方法 ?
http/1.1规定了以下请求方法(注意,都是大写):
- GET: 通常用来获取资源
- HEAD: 获取资源的元信息
- POST: 提交数据,即上传数据
- PUT: 修改数据
- DELETE: 删除资源(几乎用不到)
- CONNECT: 建立链接隧道,用于代理服务器
- OPTIONS: 列出可对资源实行的请求方法,用来跨域请求
- TRACE: 追踪请求-响应的传输路径
GET 和 POST 有什么区别 ?
首先最直观的是语义上的区别。
而后又有这样一些具体的差别:
- 从缓存的角度,GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。
- 从编码的角度,GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。
- 从参数的角度,GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。
- 从幂等性的角度,GET是幂等的,而POST不是。(幂等表示执行相同的操作,结果也是相同的)
- 从TCP的角度,GET 请求会把请求报文一次性发出去,而 POST 会分为两个 TCP 数据包,首先发 header 部分,如果服务器响应 100(continue), 然后发 body 部分。(火狐浏览器除外,它的 POST 请求只发一个 TCP 包)
003.如何理解 URL ?
URI, 全称为(Uniform Resource Identifier), 也就是统一资源标识符,它的作用很简单,就是区分互联网上不同的资源。
但是,它并不是我们常说的网址, 网址指的是URL, 实际上URI包含了URN和URL两个部分,由于 URL 过于普及,就默认将 URI 视为 URL 了。
URL 的结构
URI 真正最完整的结构是这样的。

可能你会有疑问,好像跟平时见到的不太一样啊!先别急,我们来一一拆解。
scheme 表示协议名,比如http, https, file等等。后面必须和://连在一起。
user:passwd@ 表示登录主机时的用户信息,不过很不安全,不
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









