







点击蓝色“力扣加加”关注我哟
加个“星标”,带你揭开算法的神秘面纱!
❝这是力扣加加第「37」篇原创文章
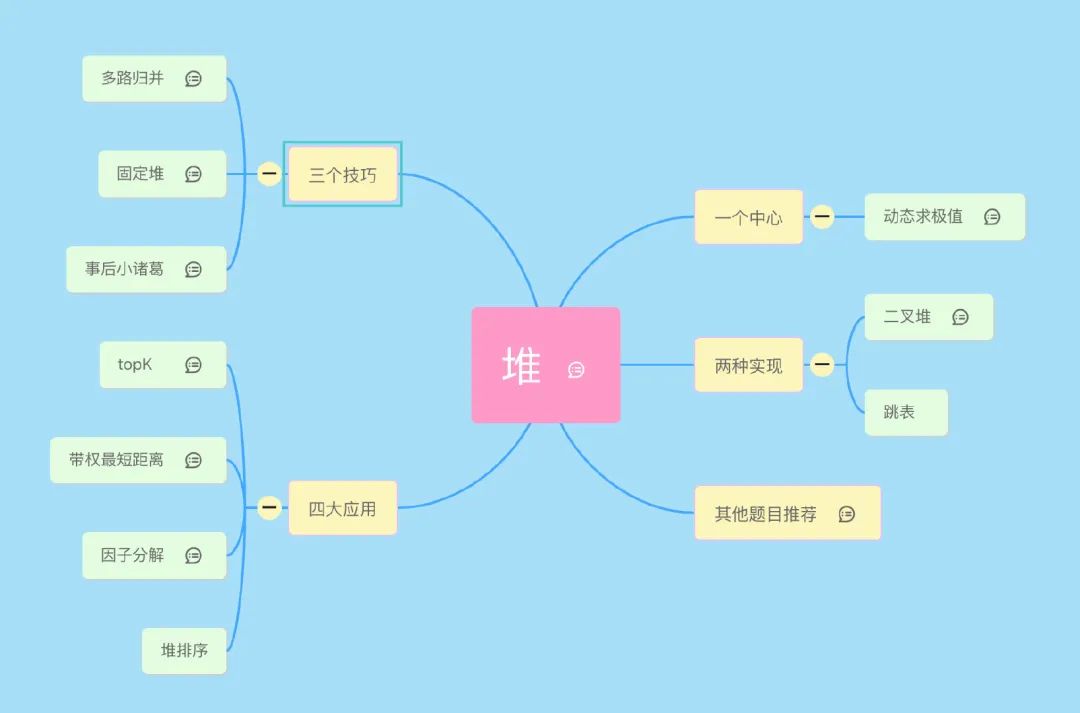
大家好,我是 lucifer。今天给大家带来的是《堆》专题。先上下本文的提纲,这个是我用 mindmap 画的一个脑图,之后我会继续完善,将其他专题逐步完善起来。
❝大家也可以使用 vscode blink-mind 打开源文件查看,里面有一些笔记可以点开查看。源文件可以去我的公众号《力扣加加》回复脑图获取,以后脑图也会持续更新更多内容。vscode 插件地址:https://marketplace.visualstudio.com/items?itemName=awehook.vscode-blink-mind
❞
本系列包含以下专题:
- 几乎刷完了力扣所有的链表题,我发现了这些东西。。。
- 几乎刷完了力扣所有的树题,我发现了这些东西。。。
- 几乎刷完了力扣所有的堆题,我发现了这些东西。。。(就是本文)
一点絮叨
堆标签[1]在 leetcode 一共有 「42 道题」。为了准备这个专题,我将 leetcode 几乎所有的堆题目都刷了一遍。
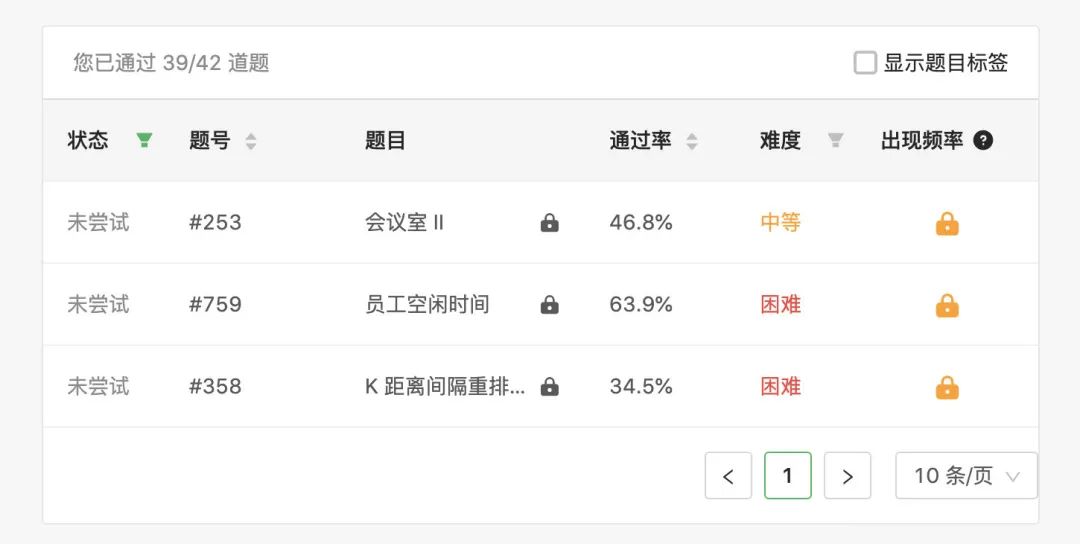
可以看出,除了 3 个上锁的,其他我都刷了一遍。通过集中刷这些题,我发现了一些有趣的信息,今天就分享给大家。
需要注意的是,本文不对堆和优先队列进行区分。因此本文提到的堆和优先队列大家可以认为是同一个东西。如果大家对两者的学术区别感兴趣,可以去查阅相关资料。
❝如果不做特殊说明,本文的堆均指的是小顶堆。
❞
堆的题难度几何?
堆确实是一个难度不低的专题。从官方的难度标签来看,堆的题目一共才 42 道,困难度将近 50%。没有对比就没有伤害,树专题困难度只有不到 10%。
从通过率来看,「一半以上」的题目平均通过率在 50% 以下。作为对比, 树的题目通过率在 50% 以下的只有「不到三分之一」。
不过大家不要太有压力。lucifer 给大家带来了一个口诀「一个中心,两种实现,三个技巧,四大应用」,我们不仅讲实现和原理,更讲问题的「背景以及套路和模板」。
❝文章里涉及的模板大家随时都可以从我的力扣刷题插件 leetcode-cheatsheet[2] 中获取。
❞
堆的使用场景分析
堆其实就是一种数据结构,数据结构是为了算法服务的,那堆这种数据结构是为哪种算法服务的?它的适用场景是什么?这是每一个学习堆的人「第一个」需要解决的问题。在什么情况下我们会使用堆呢?堆的原理是什么?如何实现一个堆?别急,本文将一一为你揭秘。
在进入正文之前,给大家一个学习建议 - 「先不要纠结堆怎么实现的,咱先了解堆解决了什么问题」。当你了解了使用背景和解决的问题之后,然后「当一个调包侠」,直接用现成的堆的 api 解决问题。等你理解得差不多了,再去看堆的原理和实现。我就是这样学习堆的,因此这里就将这个学习经验分享给你。
为了对堆的使用场景进行说明,这里我虚拟了一个场景。
「下面这个例子很重要, 后面会反复和这个例子进行对比」。
一个挂号系统
问题描述
假如你是一个排队挂号系统的技术负责人。该系统需要给每一个前来排队的人发放一个排队码(入队),并根据「先来后到」的原则进行叫号(出队)。
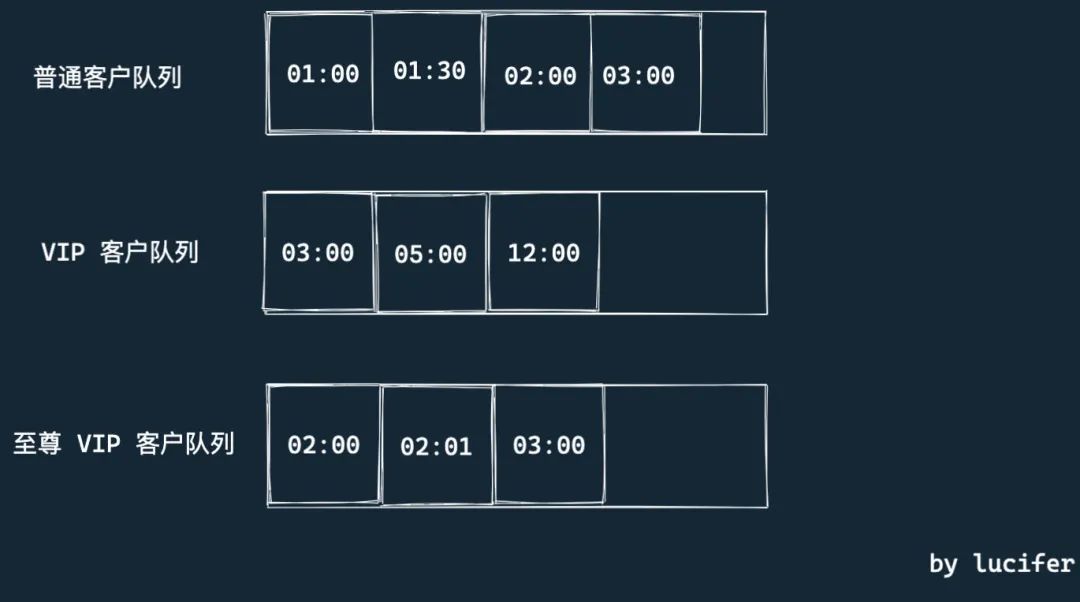
除此之外,我们还可以区分了几种客户类型, 分别是普通客户, VIP 客户 和 至尊 VIP 客户。
- 如果不同的客户使用不同的窗口的话,我该如何设计实现我的系统?(大家获得的服务不一样,比如 VIP 客户是专家级医生,普通客户是普通医生)
- 如果不同的客户都使用一个窗口的话,我该如何设计实现我的系统?(大家获得的服务都一样,但是优先级不一样。比如其他条件相同情况下(比如他们都是同时来挂号的),VIP 客户 优先级高于普通客户)
我该如何设计我的系统才能满足需求,并获得较好的扩展性?
初步的解决方案
如果不同的客户使用不同的窗口。那么我们可以设计三个队列,分别存放正在排队的三种人。这种设计满足了题目要求,也足够简单。
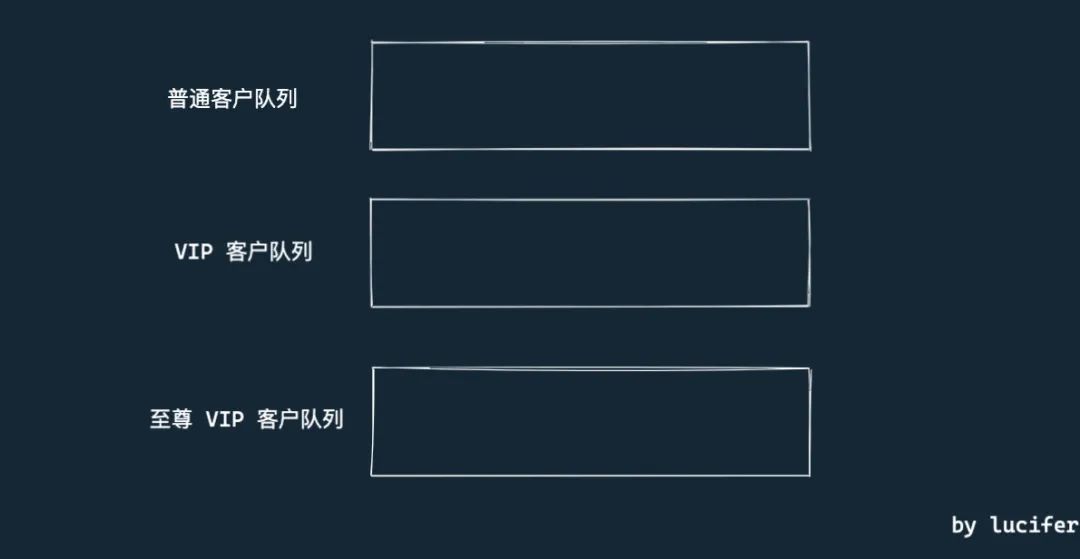
如果我们「只有一个窗口」,所有的病人需要使用同一个队列,并且同样的客户类型按照上面讲的「先到先服务原则」,但是不同客户类型之间可能会插队。
简单起见,我引入了「虚拟时间」这个概念。具体来说:
- 普通客户的虚拟时间就是真实时间。
- VIP 客户的虚拟时间按照实际到来时间减去一个小时。比如一个 VIP 客户是 14:00 到达的,我认为他是 13:00 到的。
- 至尊 VIP 客户的虚拟时间按照实际到来时间减去两个小时。比如一个 至尊 VIP 客户是 14:00 到达的,我认为他是 12:00 到的。
这样,我们只需要按照上面的”虚拟到达时间“进行「先到先服务」即可。
因此我们就可以继续使用刚才的三个队列的方式,只不过队列存储的不是真实时间,而是虚拟时间。每次开始叫号的时候,我们使用虚拟时间比较,虚拟时间较小的先服务即可。

❝不难看出,队列内部的时间都是有序。
❞
「而这里的虚拟时间,其实就是优先队列中的优先权重」,虚拟时间越小,权重越大。
可以插队怎么办?
这种算法很好地完成了我们的需求,复杂度相当不错。不过事情还没有完结,这一次我们又碰到新的产品需求:
- 如果有别的门诊的病人转院到我们的诊所,则按照他之前的排队信息算,比如 ta 是 12:00 在别的院挂的号,那么转到本院仍然是按照 12:00 挂号算。
- 如果被叫到号三分钟没有应答,将其作废。但是如果后面病人重新来了,则认为他是当前时间减去一个小时的虚拟时间再次排队。比如 ta 是 13:00 被叫号,没有应答,13:30 又回来,则认为他是 12:30 排队的,重新进队列。
这样就有了”插队“的情况了。该怎么办呢?一个简单的做法是,将其插入到正确位置,并「重新调整后面所有人的排队位置」。
如下图是插入一个 1:30 开始排队的普通客户的情况。
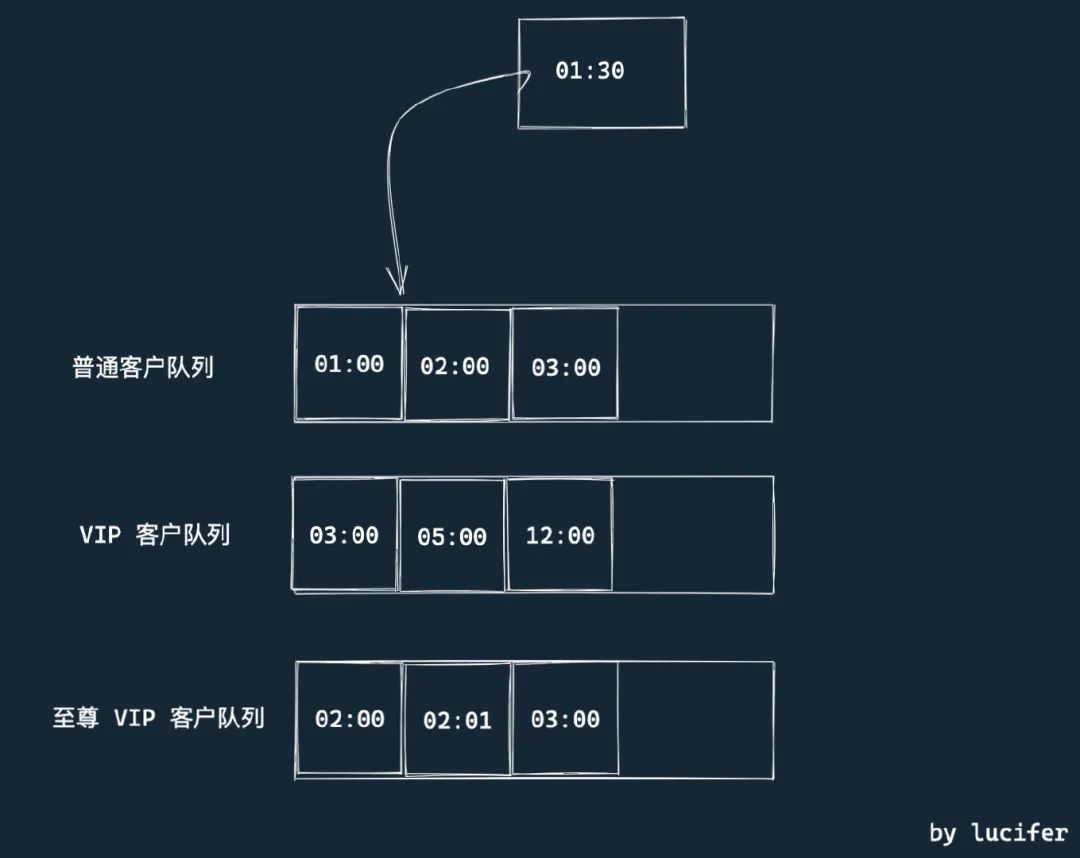 (查找插入位置)
(查找插入位置)
 (将其插入)
(将其插入)
如果队列使用数组实现, 上面插队过程的时间复杂度为 ,其中 为被插队的队伍长度。如果队伍很长,那么调整的次数明显增加。
不过我们发现,本质上我们就是在维护一个「有序列表」,而使用数组方式去维护有序列表的好处是可以随机访问,但是很明显这个需求并不需要这个特性。如果使用链表去实现,那么时间复杂度理论上是 ,但是如何定位到需要插入的位置呢?朴素的思维是遍历查找,但是这样的时间复杂度又退化到了 。有没有时间复杂度更好的做法呢?答案就是本文的主角「优先队列」。
上面说了链表的实现核心在于查找也需要 ,我们可以优化这个过程吗?实际上这就是优先级队列的链表实现,由于是有序的,我们可以用跳表加速查找,时间复杂度可以优化到 。
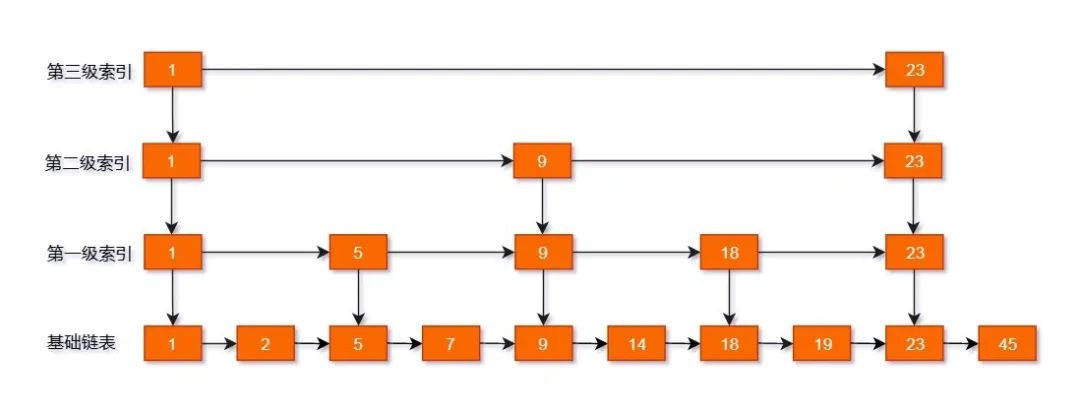
其实算法界有很多类似的问题。比如建立数据库索引的算法,如果给某一个有序的列添加索引,不能每次插入一条数据都去调整所有的数据吧(上面的数组实现)?因此我们可以用平衡树来实现,这样每次插入可以最多调整 。优先队列的另外一种实现 - 二叉堆就是这个思想,时间复杂度也可以优化到
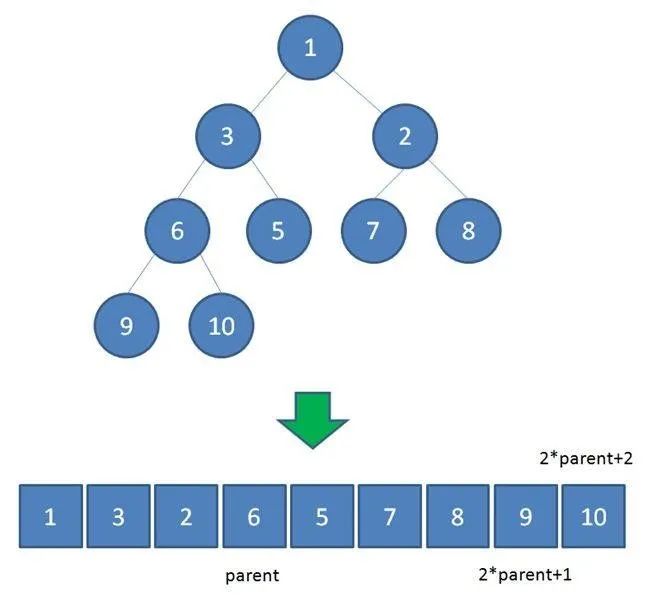
本文只讲解常见的二叉堆实现,对于跳表和红黑树不再这里讲。关于优先队列的二叉堆实现,我们会在后面给大家详细介绍。这里大家只有明白优先队列解决的问题是什么就可以了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









