






前言:
近期因为工作需要梳理了一些网上流传比较广的MySQL经典面试练习题,按照自己的理解从头写了一遍解法。有些特殊问题着重标记了思路和所涉及到的函数或语法点。共享给正在学习SQL或正在刷面试题的小伙伴们。
若对小伙伴们起到了帮助,欢迎点赞+收藏+转发~若具体到某个题目有更好的解题方法也欢迎大家留言或私信一起学习交流~
一 . 新建数据库及数据表
1:新建数据库 test。
语句:
create database test; 2:按照如下字段数据库中新建对应表,并按照如下数据填充表格数据。
2.1:新建学生表student,包含sid 学生id,sname 学生姓名,sage 学生出生年月,ssex 学生性别4个字段。
数据:

语句:
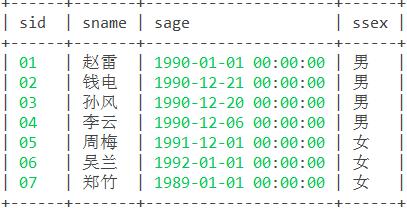
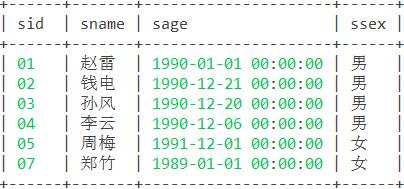
create table student(sid varchar(10),sname varchar(10),sage datetime,ssex varchar(10)); insert into student values('01' , '赵雷' , '1990-01-01' , '男'); insert into Student values('02' , '钱电' , '1990-12-21' , '男'); insert into Student values('03' , '孙风' , '1990-12-20' , '男'); insert into Student values('04' , '李云' , '1990-12-06' , '男'); insert into Student values('05' , '周梅' , '1991-12-01' , '女'); insert into Student values('06' , '吴兰' , '1992-01-01' , '女'); insert into Student values('07' , '郑竹' , '1989-01-01' , '女'); insert into Student values('09' , '张三' , '2017-12-20' , '女'); insert into Student values('10' , '李四' , '2017-12-25' , '女'); insert into Student values('11' , '李四' , '2012-06-06' , '女'); insert into Student values('12' , '赵六' , '2013-06-13' , '女'); insert into Student values('13' , '孙七' , '2014-06-01' , '女'); 2.2:新建成绩表sc,包含sid 学生编号,cid 课程编号,score 分数 3个字段。
数据:
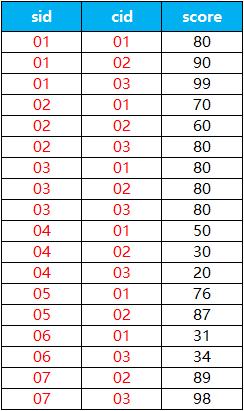
语句:
create table sc(sid varchar(10),cid varchar(10),score decimal(3,1)); insert into SC values('01' , '01' , 80); insert into SC values('01' , '02' , 90); insert into SC values('01' , '03' , 99); insert into SC values('02' , '01' , 70); insert into SC values('02' , '02' , 60); insert into SC values('02' , '03' , 80); insert into SC values('03' , '01' , 80); insert into SC values('03' , '02' , 80); insert into SC values('03' , '03' , 80); insert into SC values('04' , '01' , 50); insert into SC values('04' , '02' , 30); insert into SC values('04' , '03' , 20); insert into SC values('05' , '01' , 76); insert into SC values('05' , '02' , 87); insert into SC values('06' , '01' , 31); insert into SC values('06' , '03' , 34); insert into SC values('07' , '02' , 89); insert into SC values('07' , '03' , 98); 2.3:新建课程表course,包含cid 课程编号,cname 课程名称,tid教师编号3个字段。
数据:
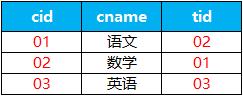
语句:
create table course(cid varchar(10),cname varchar(10),tid varchar(10)); insert into course values('01' , '语文' , '02'); insert into course values('02' , '数学' , '01'); insert into course values('03' , '英语' , '03'); 2.4:新建教师表teacher,包含tid 教师编号,tname 教师姓名 2个字段。
数据:
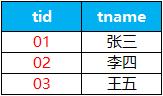
语句:
create table teacher(tid varchar(10),tname varchar(10)); insert into teacher values('01' , '张三'); insert into teacher values('02' , '李四'); insert into teacher values('03' , '王五'); 2.5:观察4张表之间的联结关系,加深印象,便于后面题目中使用。
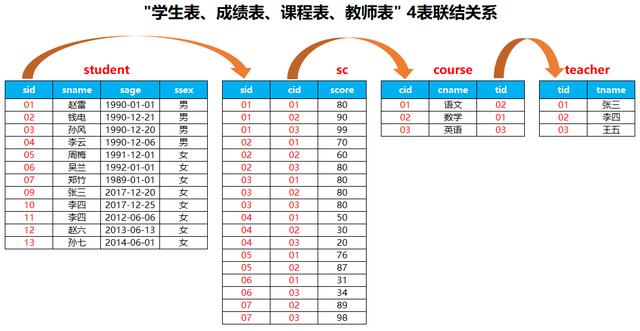
二. 题目
1.1. 查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数。
思路:
步骤1:分别查询课程01、02的学生及分数信息并视作临时表a、b;
步骤2:对2表联合查询学生及2课程分数信息,并限定条件“课程01成绩 > 课程02成绩”;
步骤3:将步骤2查询结果作临时表c,右联结至student表后查询所需信息,
函数:仅显示有数据的学生信息,故以student表为基础,右联结临时表c,需用到右联结函数right join
语句:
select * from student right join (select a.sid,score01,score02 from (select sid,score as score01 from sc where cid='01')a, (select sid,score as score02 from sc where cid='02')b where a.sid=b.sid and score01>score02)c on student.sid=c.sid; 结果:

1.2. 查询同时存在" 01 "课程和" 02 "课程的情况。
思路:分别查询学习了课程01、02的学生及课程分数信息,将2个查询结果分别视作2个临时表,并联表查询。
函数:inner join(),也可以用缩写join(),功能一样,都是取关联表的交集部分记录。
语句1:
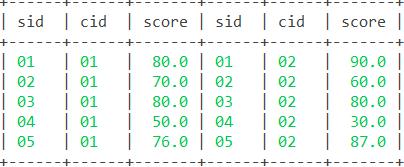
select * from (select * from sc where cid='01')a, (select * from sc where cid='02')b where a.sid=b.sid; 语句2:
select * from (select * from sc where cid='01')a inner join (select * from sc where cid='02')b on a.sid=b.sid; 结果:
1.3. 查询不存在" 01 "课程但存在" 02 "课程的情况。
思路:未选修了课程01但选修了课程02,在语法上无法直接写出。换个思路,选修了课程02但学生编号不在选修了课程01的学生编号集合中,一样的效果。
函数:不在某个集合中,涉及子集查询not in()
语句:
select * from sc where cid='02' and sid not in (select sid from sc where cid='01'); 结果:

2. 查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩。
思路:/
函数:avg()
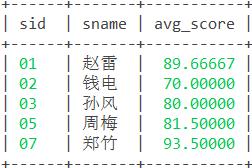
语句1:直接查询
select s.sid,s.sname,avg(sc.score) as avg_score from student s,sc where s.sid=sc.sid group by s.sid having avg(sc.score)>=60;语句2:嵌套查询
select s.sid,s.sname,avg_score from student s,(select sid,avg(sc.score) as avg_score from sc group by sid having avg(sc.score)>=60)t where s.sid=t.sid;结果:
3. 查询在 SC 表存在成绩的学生信息。
思路:直接对student、sc联表查询,联结条件sid;或查询student并限定sid在sc表中有记录;再或者查询student并限定sid在sc表与student表中有交集。
函数:/
语句1:联合查询
select distinct s.* from student s,sc where s.sid=sc.sid; 语句2:嵌套查询,引入in函数
select * from student where sid in(select sid from sc); 语句3:嵌套查询,引入exists函数
select * from student where exists (select sid from sc where sc.sid=student.sid); 结果:
4.1. 查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )。
思路:/
函数:计数函数count()、求和函数sum()
语句:
select s.*,count(cid) as'选课总数',sum(score) as'课程总成绩' from student s left join sc on s.sid=sc.sid group by sid; 结果:

提醒:题干要求“没成绩的显示NULL”,而此处若用where过滤相当于inner join取交集,则不会出现NULL情况。使用where的结果如下,可与上述结果对比差异。
错误语句:
select s.*,count(cid) as'选课总数',sum(score) as'课程总成绩' from student s,sc where s.sid=sc.sid group by sid;错误结果:

4.2. 查有成绩的学生信息。
思路:与题3一致
函数:/
语句1:联合查询
select distinct s.* from student s inner join sc on s.sid=sc.sid; 语句2:嵌套查询,引入in子集查询
select * from student where sid in (select sid from sc); 语句3:嵌套查询,引入exists函数
select * from student where exists (select sid from sc where sc.sid=student.sid); 结果:

5. 查询「李」姓老师的数量。
思路:/
函数:模糊查询,考察like以及通配符%的使用。
语句:
select count(tname) as '李姓老师数量' from teacher where tname like '李%'; 结果:

6. 查询过「张三」老师授课的同学的信息。
思路:student s,sc,course,teacher 四表联合查询
函数:/
语句:
select s.* from student s,sc,course c,teacher t where s.sid=sc.sid and sc.cid=c.cid and c.tid=t.tid and tname='张三'; 结果:
7. 查询没有学全所有课程的同学的信息。
思路:反向思考,先把学全了全部课程(所选课程数等于实际所有课程数3)的同学信息先查询出来,再把这部分人从全部同学信息中过滤掉。
函数:not in()
语句:
select * from student where sid not in (select sid from sc group by sid having count(cid)=(select count(cid) from course)); 结果:

8. 查询至少有一门课与学号为" 01 "的同学所学相同的同学的信息。
思路:反向查询,先查学号01学习的课程,再查询选修了这些课程的学号信息,再通过学号信息查询学生信息。
函数:/
语句:
select * from student where sid in (select sid from sc where cid in (select cid from sc where sid='01')); 结果:
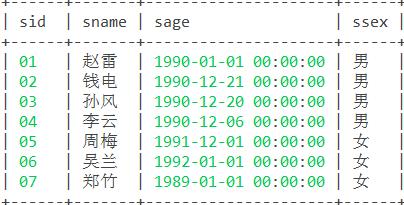
9. 查询和" 01 "号的同学学习的课程完全相同的其他同学的信息。
思路:反向查询,先查询学号01学习的课程编号,在查询选修了这些课程的学号信息,加入过滤条件学号不等于01以及课程编号计数与01相等(或课程编号求和与01相等)。
函数:/
语句1:
select * from student where sid in (select sid from sc where cid in (select cid from sc where sid='01') and sid!='01' group by sid having sum(cid)=(select sum(cid) from sc where sid='01')); 语句2:
select * from student where sid in (select sid from sc where cid in (select cid from sc where sid='01') and sid!='01' group by sid having count(cid)=(select count(cid) from sc where sid='01')); 结果:
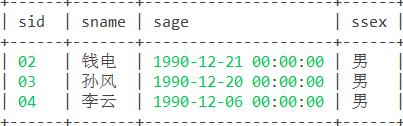
10. 查询没学过"张三"老师讲授的任一门课程的学生姓名。
思路:反向思维,先查询"张三"老师教过哪些课;再查出学过这些课的学生;反向查询不在这些学生中的其他学生,就是没学过"张三"老师课的学生。
函数:not in()
语句1:
select * from student where sid not in (select sid from sc where cid in (select cid from course where tid in (select tid from teacher where tname='张三'))); 语句2:
select * from student where sid not in select s.sid from student s,sc,course,teacher where s.sid=sc.sid and sc.cid=course.cid and course.tid=teacher.tid and teacher.tname='张三'); 结果:
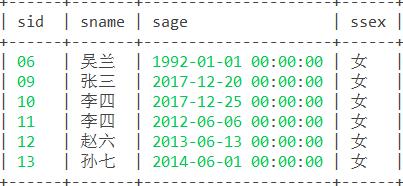
11. 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩。
思路:/
函数:avg()、sum()
语句:
select s.sid,s.sname,avg(score) as avgscore from student s,sc where s.sid=sc.sid and score<60 group by s.sid having count(score)>=2; 结果:

12. 检索" 01 "课程分数小于 60,按分数降序排列的学生信息。
思路:/
函数:/
语句:
select student.*,score from student,sc where student.sid=sc.sid and cid='01' and score<60 order by score desc; 结果:

13. 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩。
思路1:从sc分别查询sid、3科的成绩、平均成绩分5列呈现到1个临时表,将student与此临时表进行关联查询出学生信息、成绩信息,关联条件sid,并按平均成绩降序排序;
函数:'sum()'、'case when'
语句:
select s.*,score01,score02,score03,avg_score from student s, (select sid, sum(case when cid='01' then score else null end) as score01, sum(case when cid='02' then score else null end) as score02, sum(case when cid='03' then score else null end) as score03, avg(score) as avg_score from sc group by sid)t where s.sid=t.sid order by avg_score desc; 结果:

语句2:将student与学生的成绩表、平均成绩表(需单独创建临时表)联结后查询,语法内容较上述查询少,但呈现结果不如上述查询直观,不推荐。
函数:left join
语句:
select * from student s left join sc on s.sid=sc.sid left join (select sid,avg(score) as avg_score from sc group by sid) t on s.sid=t.sid order by t.avg_score desc; 结果:

14. 查询各科成绩最高分、最低分、平均分、及格率、中等率、优良率、优秀率,要求如下:
(1)及格:分数>=60,中等:80>分数≥70,优良:90>分数≥80,优秀:分数>=90;
(2)显示:课程编号、课程名、选修人数,查询结果按人数降序排列,若人数相同则按课程号升序排列。
思路:计算及格/中等/优良/优秀4个率时,先统计分子即符合各个区间的分数数量,再除以分母即总记录数,即为对应分数段比率。
函数:分数若符合某个区间要求则拟定返回1否则0,所有的返回值累加即为符合该区间的分数数量,此处引入'sum()'函数,'case when'函数。
语句:
select sc.cid as '课程编号', c.cname as '课程名', count(sc.cid) as '选修人数', max(score) as '最高分', min(score) as '最低分', avg(score) as '平均分', sum(case when score>=60 then 1 else 0 end)/count(*) as '及格率', sum(case when score>=70 and score<80 then 1 else 0 end)/count(*) as '中等率', sum(case when score>=80 and score<90 then 1 else 0 end)/count(*) as '优良率', sum(case when score>=90 then 1 else 0 end)/count(*) as '优秀率' from sc,course c where sc.cid=c.cid group by sc.cid order by sc.cid; 结果:

15. 查询出只选修两门课程的学生学号和姓名。
思路:
函数:计数函数count()
语句:
select s.sid,s.sname,count(sc.cid) as cid_num from student s,sc where s.sid=sc.sid group by s.sid having count(sc.cid)=2; 结果:

16.1 按各科成绩进行排序,并显示排名, Score 重复时保留名次空缺。
思路:查询课程01、02、03、04成绩排名;将查询结果分别视作临时表t123,将student分别与之左联结后查询显示学生信息及各科排名信息,联结条件sid。
函数:涉及排序且题干要求重复时“保留名次空缺”,此处引入dense_rank() over (partition by 分区列 order by 排序列)。
语句:
select s.*,rank_cid01,rank_cid02,rank_cid03 from student s left join (select sid,dense_rank() over(partition by cid order by score) as rank_cid01 from sc where cid='01')t1 on s.sid=t1.sid left join (select sid,dense_rank() over(partition by cid order by score) as rank_cid02 from sc where cid='02')t2 on s.sid=t2.sid left join (select sid,dense_rank() over(partition by cid order by score) as rank_cid03 from sc where cid='03')t3 on s.sid=t3.sid group by s.sid order by s.sid; 结果:

16.2 查询学生的总成绩,并进行排名,总分重复时不保留名次空缺。
思路:直接查询,查询科目总成绩,并对总成绩进行排序。
函数:涉及排序且题干要求重复时“不保留名次空缺”,此处引入rank() over (partition by 分区列 order by 排序列),可与15.1对比dense_rank区别。
select s.*,sum(score) as '总成绩',rank() over(partition by cid order by score) as '总成绩排名' from student s,sc where s.sid=sc.sid group by s.sid; 结果:

16.3 按平均成绩进行排序,显示总排名和各科排名,Score 重复时保留名次空缺。
思路:与16.1一致,嵌套查询,分别查询各科目单独排名、科目总排名后合并显示。
函数:与16.1一致,涉及排序且题干要求重复时“保留名次空缺”,使用dense_rank() over (partition by 分区列 order by 排序列)。
语句:将上述查询分别视作临时表t1134,用student分别进行左联结后显示学生信息、各科排名及总排名,联结条件为sid,并以总排名排序。
select s.*,rank_cid01,rank_cid02,rank_cid03,rank_all from student s left join (select sid,dense_rank() over(partition by cid order by score) as rank_cid01 from sc where cid='01')t1 on s.sid=t1.sid left join (select sid,dense_rank() over(partition by cid order by score) as rank_cid02 from sc where cid='02')t2 on s.sid=t2.sid left join (select sid,dense_rank() over(partition by cid order by score) as rank_cid03 from sc where cid='03')t3 on s.sid=t3.sid left join (select sid,dense_rank() over(order by avg(score) desc) as rank_all from sc group by sid)t4 on s.sid=t4.sid group by s.sid order by rank_all; 结果:

17. 统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[60-0] 及所占百分比。
思路:统计出各个分数段人数,再使用各个分数段人数除以选课总人数即所占百分比;
函数:sum()、case when
语句:
select sc.cid as '课程编号',c.cname as '课程名称', sum(case when score>=85 then 1 else 0 end) as '[100-85]人数', sum(case when score>=85 then 1 else 0 end)/count(score) as '[100-85]占比', sum(case when score>=70 and score<85 then 1 else 0 end) as '[85-70]人数', sum(case when score>=70 and score<85 then 1 else 0 end)/count(score) as '[85-70]占比', sum(case when score>=60 and score<70 then 1 else 0 end) as '[70-60]人数', sum(case when score>=60 and score<70 then 1 else 0 end)/count(score) as '[70-60]占比', sum(case when score<60 then 1 else 0 end) as '[60-0]人数', sum(case when score<60 then 1 else 0 end)/count(score) as '[60-0]占比' from sc,course c where sc.cid=c.cid group by sc.cid; 结果:

18. 查询各科成绩前3名的记录。
思路:因为涉及对成绩排序,且排序前需根据课程编号限定排序分区,此处引入rank() over (partition by 分区列 order by 排序列)函数。
函数:rank() over()
语句:
select * from (select *,rank() over(partition by cid order by score desc) as rank_score from sc)t where rank_score<=3; 结果:

19. 查询每门课程被选修的学生数。
思路:/
函数:/
语句:
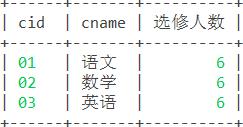
select c.cid,c.cname,count(sc.cid) as '选修人数' from course c,sc where c.cid=sc.cid group by c.cid; 结果:
20. 查询出只选修两门课程的学生学号和姓名。
思路:/
函数:/
语句:
select s.sid,s.sname,count(cid) as '选修课程数' from student s,sc where s.sid=sc.sid group by s.sid having count(cid)=2; 结果:

21. 查询男生、女生人数。
思路:/
函数:计数函数count()
语句:
select ssex,count(ssex) as '人数' from student group by ssex; 结果:

22. 查询名字中含有「风」字的学生信息。
思路:/
函数:模糊查询,考察like和通配符'%'的用法。
语句:
select * from student where sname like '%风%'; 结果:
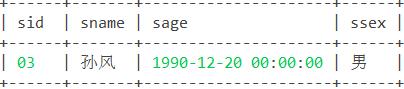
23. 查询同名同性学生名单,并统计同名人数。
思路:以学生姓名进行分组,并对姓名进行计数;筛选此查询结果中“姓名计数”>1(或≥2)的数据,即同名同姓的数据。
函数:计数函数count()
语句:
select sname,count(sname) as '姓名计数' from student group by sname having count(sname)>1; 结果:

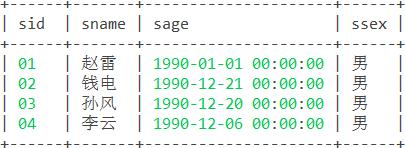
24. 查询 1990 年出生的学生名单。
思路:同第5题,考察模糊查询语句 like以及通配符%的使用。
函数:/
语句:
select * from student where sage like '1990%'; 结果:
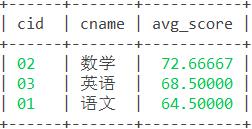
25. 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列。
思路:/
函数:avg()
语句:
select sc.cid,cname,avg(score) as avg_score from sc,course c where sc.cid=c.cid group by sc.cid order by avg(score) desc,sc.cid; 结果:
26. 查询平均成绩大于等于 85 的所有学生的学号、姓名和平均成绩。
思路1:嵌套查询。查询所有学生平均成绩;将结果视作临时表t,将student表与其联结后查询学生信息,并加入过滤条件平均分≥85;
函数:/
语句:
select s.*,avg_score from student s, (select sid,avg(score) as avg_score from sc group by sid)t where s.sid=t.sid and t.avg_score>=85; 结果:

思路2:直接查询
函数:/
语句:
select s.*,avg(score) as avg_score from student s,sc where s.sid=sc.sid group by s.sid having avg_score>=85; 结果:

27. 查询课程名称为 “数学”,且分数低于60的学生姓名和分数。
思路1:直接查询。直接对student、sc、course三遍联合查询,并加入科目为数学,分数小于60分条件过滤。
函数:/
语句:
select s.sname,c.cname,sc.score from student s,sc,course c where s.sid=sc.sid and sc.cid=c.cid and c.cname='数学' group by s.sname having sc.score<60; 结果:

思路2:嵌套查询。查询课程“数学”对应课程编号;反查选修了此编号的学生和分数信息;再与student进行联合查询,取学生姓名,分数信息,并加入过滤条件分数<60。
函数:/
语句:
select s.sname,t.cid,t.score from student s, (select sid,cid,score from sc where cid in(select cid from course where cname='数学'))t where s.sid=t.sid and t.score<60; 结果:

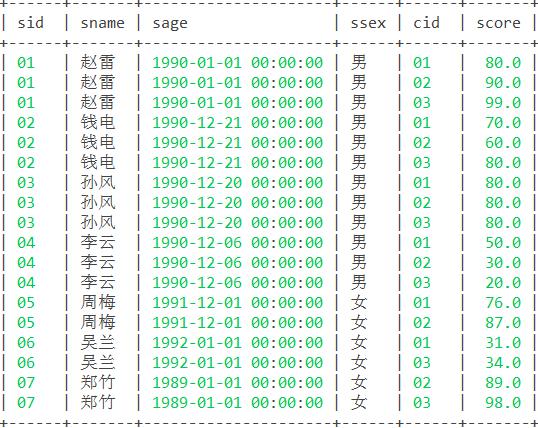
28. 查询所有学生的课程及分数情况(存在学生没成绩,没选课的情况)。
思路:按题目要求即得知需以student表左联结sc表,即以student为主匹配选课和分数,而未选课无分数的学生对应信息则默认为空值。
函数:左联结函数left join()
select s.*,sc.cid,sc.score from student s left join sc on s.sid=sc.sid; 结果:

提醒:有的同学会以student表右联结sc表,即以sc为主匹配student中有选课有分数的学生信息,这样的话未选课的学生信息不显示,则不符合题目要求“存在学生没成绩,没选课的情况”。
错误语句:
select s.*,sc.cid,sc.score from student s right join sc on s.sid=sc.sid; 错误结果:
29. 查询任何一门课程成绩在 70 分以上的姓名、课程名称和分数。
思路:任一课程>70,则平均成绩一定>70。先查询平均成绩>70的人;将查询结果与student、sc、course联合取姓名、课程信息、分数,并限定sid为平均成绩>70的人。
函数:in()、avg()
语句:
select s.sname,c.cname,sc.score from student s,sc,course c where s.sid=sc.sid and sc.cid=c.cid and s.sid in(select sid from sc group by sid having avg(score)>70); 结果:
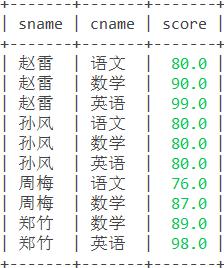
提醒:可能有些人会写成下属语句,看似正常实际结果错误,以下方“钱电”为例实际选修了3门课程:语文70,数学60,英语80,但只有英语>70其余均不符合,结果错误。
错误语句:
select s.sname,c.cname,sc.score from student s,sc,course c where s.sid=sc.sid and sc.cid=c.cid and sc.score>70; 错误结果:

30. 查询存在不及格的课程。
思路:查询分数小于60分的课程后对课程进行剔重;或查询分数小于60分的课程后对课程进行分组。
函数:/
语句1:
select distinct cid from sc where score<60; 语句2:
select cid from sc where score<60 group by cid; 结果:

31. 查询课程编号为 01 且课程成绩在 80 分及以上的学生的学号和姓名。
思路:/
函数:/
语句:
select s.sid,s.sname,sc.cid,sc.score from student s,sc where s.sid=sc.sid and sc.cid='01' and sc.score>=80; 结果:

32. 求每门课程的学生人数。
思路:/
函数:计数函数count()
语句:
select cid,count(sid) as '选课人数' from sc group by cid; 结果:

33. 成绩不重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩。
思路:student、sc、course、teacher四表联合查询,用max函数求最高成绩后过滤;若不了解max函数,也可以将联合查询结果以分数降序排序后截取第1条数据,即最大值数据。
函数:最大值函数max()、limit极限函数(可用于截取限定记录)
语句:
语句1:
select s.*,sc.score,c.cid,c.cname,t.tname from student s,sc,course c,teacher t where s.sid=sc.sid and sc.cid=c.cid and c.tid=t.tid and t.tname='张三' having(max(sc.score)); 语句2:
select s.*,sc.score,c.cid,c.cname,t.tname from student s,sc,course c,teacher t where s.sid=sc.sid and sc.cid=c.cid and c.tid=t.tid and t.tname='张三' order by sc.score desc limit 1; 结果:

34. 成绩有重复的情况下,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩。
思路:通过查看原始表可得知没有成绩重复的情况,所以结果与33题一致,只有1条
函数:/
语句:
select s.*,sc.score,c.cid,c.cname,t.tname from student s,sc,course c,teacher t where s.sid=sc.sid and sc.cid=c.cid and c.tid=t.tid and t.tname='张三' and sc.score in (select max(sc.score) from student s,sc,course c,teacher t where s.sid=sc.sid and sc.cid=c.cid and c.tid=t.tid and t.tname='张三' and sc.score); 结果:

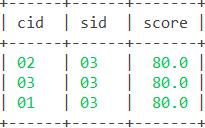
35. 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩。
思路:
函数:inner join,也可直接用其缩写join,效果一样。
语句:
select a.cid,a.sid,a.score from sc as a inner join sc on a.sid=sc.sid and a.cid<>sc.cid and a.score=sc.score group by a.sid,a.cid; 结果:
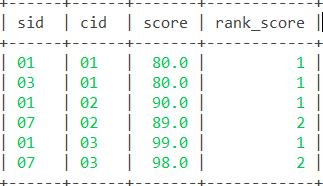
36. 查询每门功成绩最好的前两名。
思路:对每门功课排名,并取排名≤2的记录即可。
函数:排序函数rank() over()
语句:
select * from (select *,rank() over(partition by cid order by score desc) as rank_score from sc)t where rank_score<=2; 结果:
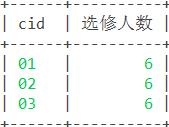
37. 统计每门课程的学生选修人数(超过 5 人的课程才统计)。
思路:/
函数:计数函数count()
语句:
select cid,count(sid) as '选修人数' from sc group by cid having count(sid)>=5; 结果:
38. 检索至少选修两门课程的学生学号。
思路:/
函数:计数函数count()
语句:
select sid,count(cid) as '选修课程数' from sc group by sid having count(cid)>=2; 结果:

39. 查询选修了全部课程的学生信息。
思路:/
函数:计数函数count()
语句:
select s.*,count(cid) as '选修课程数' from student s,sc where s.sid=sc.sid group by sid having count(cid)=(select count(cid) from course); 结果:
40. 查询各学生的年龄,只按年份来算。
思路:/
函数:考察时间差函数,可以用timestampdiff,也可以用timestampdiff,思路都是计算当前时间与出生年月日的天数差,再换算为年数,区别见下方语句。
语句1:
select *,timestampdiff(year,sage,curdate()) as age from student; 结果:

语句2:
select *,datediff(curdate(),sage)/365 as age from student; 结果:

注:上述2个语句本质上均可,区别在于查询1结果是整数,查询2结果带小数点更精确,但限于日常表述年龄一般都是整数,所以个人推荐查询1。
41. 按照出生日期来算,当前月日 < 出生年月的月日则,年龄减一。
思路:/
函数:case when()
语句:
select *,case when month(curdate())结果:

提醒:网上有的答案是按照如下语句写的,并未体现“当前月日 < 出生年月的月日则,年龄减一”的要求。
以‘钱电’为例,当前月日(笔者梳理时间2020/7/11)7月小于其出生月份12月,当前日11日小于其出生日21日,故原始年龄29-1后是28,下方结果不对。
错误语句:
select *,timestampdiff(year,sage,curdate()) as age from student; 错误结果:

42. 查询本周过生日的学生。
思路:
函数:now()、week()
语句:
select * from student where week(sage)=week(now()); 结果:Empty set (0.00 sec)
43. 查询下周过生日的学生。
思路:下周即为本周周数+1
函数:now()、week()
语句:
select * from student where week(sage)=(week(now())+1); 结果:Empty set (0.00 sec)
44. 查询本月过生日的学生。
思路:
函数:now()、month()
语句:
select * from student where month(sage)=month(now()); 结果:Empty set (0.00 sec)
45. 查询下月过生日的学生。
思路:下月即为本月月份+1
函数:now()、month()
语句:
select * from student where month(sage)=(month(now())+1); 结果:Empty set (0.00 sec)
注:42~45涉及考察日期转换函数,如week-将日期转换为当年所在周数、month-将日期转换为所在月数。另关于当前时间获取:
(1)既可以用now(),既获取年月日还获取时分秒,对应格式'2020-08-08 12:00:00';
(2)也可以用curdate(),仅获取当前日期即年月日,对应格式'2020-08-08'。














 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









