







 本文详细解读了代码结构,涉及数据处理、模型定义、评价指标、训练流程和搜索策略。重点讨论了知识蒸馏在GauGAN结构中的应用,以及如何结合NAS技术训练‘once-for-all’网络。代码组织结构清晰,包括configs、data、metrics等模块,适用于理解GauGAN的蒸馏和NAS实现。
本文详细解读了代码结构,涉及数据处理、模型定义、评价指标、训练流程和搜索策略。重点讨论了知识蒸馏在GauGAN结构中的应用,以及如何结合NAS技术训练‘once-for-all’网络。代码组织结构清晰,包括configs、data、metrics等模块,适用于理解GauGAN的蒸馏和NAS实现。

请务必先看原paper,可参考上篇解析:
科技猛兽:GAN Compression原理分析zhuanlan.zhihu.com
原作者的github项目链接:
https://github.com/mit-han-lab/gan-compressiongithub.com代码解读:
简要画了一下代码的调用关系:
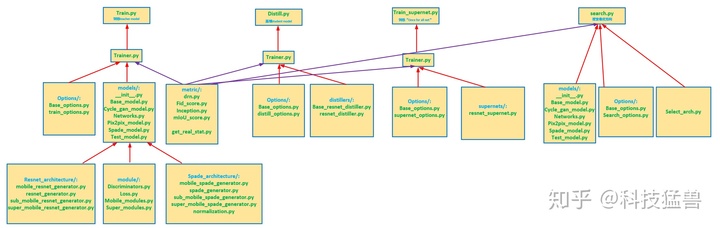
观察目录应该和上篇分析的GauGAN结构相似,多出了NAS和蒸馏的部分。我们首先看代码结构:
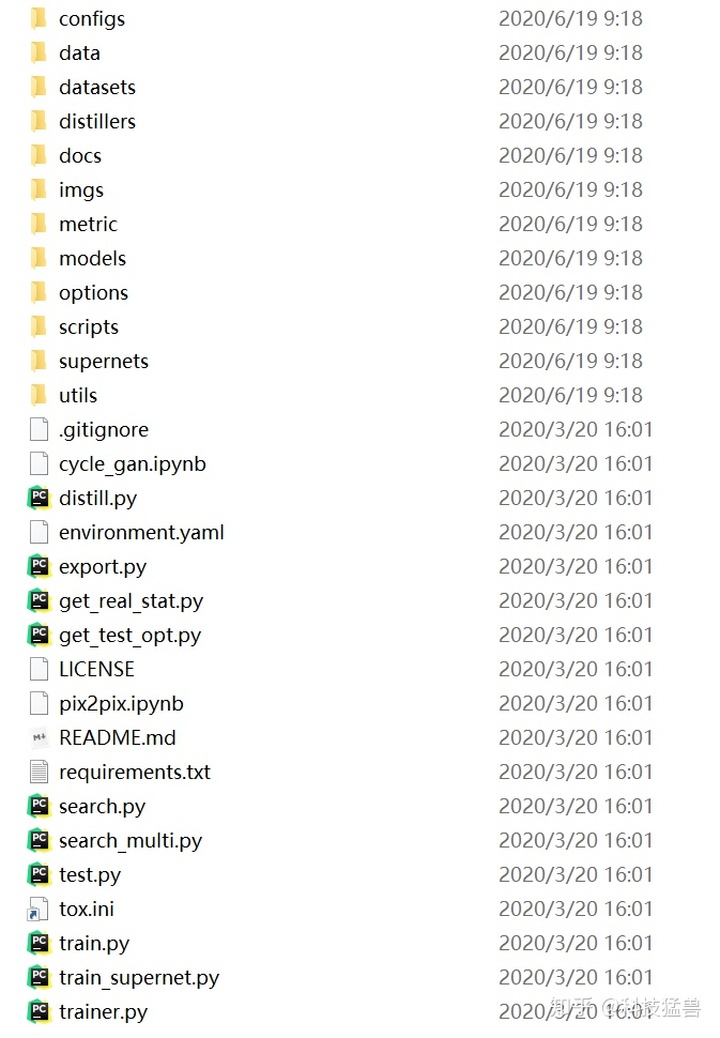
在这里简要说明每个package和module的功能以及实现方式:
configs/:

resnet_configs.py:
import random
class ResnetConfigs:
def __init__(self, n_channels):
self.attributes = ['n_channels']
self.n_channels = n_channels
def sample(self):
ret = {}
ret['channels'] = []
for n_channel in self.n_channels:
ret['channels'].append(random.choice(n_channel))
return ret
def largest(self):
ret = {}
ret['channels'] = []
for n_channel in self.n_channels:
ret['channels'].append(max(n_channel))
return ret
def smallest(self):
ret = {}
ret['channels'] = []
for n_channel in self.n_channels:
ret['channels'].append(min(n_channel))
return ret
def all_configs(self):
def yield_channels(i):
if i == len(self.n_channels):
yield []
return
for n in self.n_channels[i]:
for after_channels in yield_channels(i + 1):
yield [n] + after_channels
for channels in yield_channels(0):
yield {
'channels': channels}
def __call__(self, name):
assert name in ('largest', 'smallest')
if name == 'largest':
return self.largest()
elif name == 'smallest':
return self.smallest()
else:
raise NotImplementedError
def __str__(self):
ret = ''
for attr in self.attributes:
ret += 'attr: %sn' % str(getattr(self, attr))
return ret
def __len__(self):
ret = 1
for n_channel in self.n_channels:
ret *= len(n_channel)
def get_configs(config_name):
if config_name == 'channels-48':
return ResnetConfigs(n_channels=[[48, 32], [48, 32], [48, 40, 32],
[48, 40, 32], [48, 40, 32], [48, 40, 32],
[48, 32, 24, 16], [48, 32, 24, 16]])
elif config_name == 'channels-32':
return ResnetConfigs(n_channels=[[32, 24, 16], [32, 24, 16], [32, 24, 16],
[32, 24, 16], [32, 24, 16], [32, 24, 16],
[32, 24, 16], [32, 24, 16]])
elif config_name == 'test':
return ResnetConfigs(n_channels=[[8], [6, 8], [6, 8],
[8], [8], [8],
[8], [8]])
else:
raise NotImplementedError('Unknown configuration [%s]!!!' % config_name)配置了一些层的channel数,largest,smallest等函数应该是选择这一层channel数的大小。
data/:
这个文件夹下的代码定义的是dataset类,只不过分了好多种:
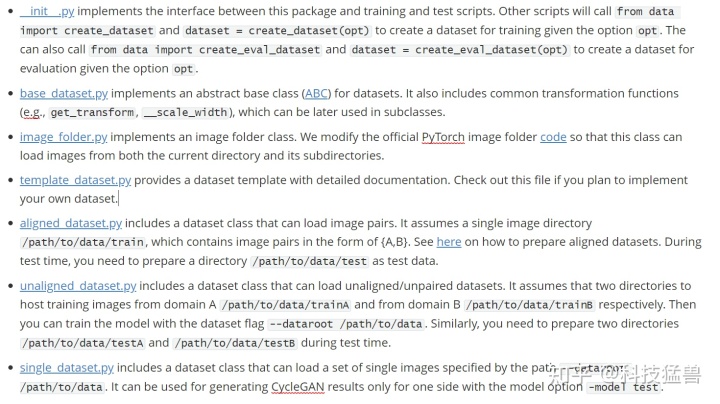
base_dataset.py:
BaseDataset继承PyTorch的data.Dataset类,overwrite了__init__(),__len__(),__getitem__()函数,modify_commandline_options写得和GauGan里面的极其相似,这里推荐阅读这篇文章:
学习python的正确姿势:Python 各种下划线都是啥意思_、_xx、xx_、__xx、__xx__、_classname_zhuanlan.zhihu.com
__scale_width()为调整图片的宽和高,保持相同的比例。__crop()裁剪图片的尺寸。__flip()为翻转图片,get_transform()利用以上函数定义预处理操作,返回值为transforms.Compose(transform_list)。其他dataset.py文件都继承了BaseDataset(), get_transform()函数。
定义dataset类的一般方法是:
Step 1: get a random image path: e.g., path = self.image_paths[index] Step 2: load your data from the disk: e.g., image = Image.open(path).convert('RGB'). Step 3: convert your data to a PyTorch tensor. You can use helpder functions such as self.transform. e.g., data = self.transform(image) Step 4: return a data point as a dictionary.
single_dataset.py:继承BaseDataset类定义最简单的dataset类。
class SingleDataset(BaseDataset):
"""This dataset class can load a set of images specified by the path --dataroot /path/to/data.
It can be used for generating CycleGAN results only for one side with the model option '-model test'.
"""
def __init__(self, opt):
"""Initialize this dataset class.
Parameters:
opt (Option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions
"""
BaseDataset.__init__(self, opt)
self.A_paths = sorted(make_dataset(opt.dataroot, opt.max_dataset_size))
input_nc = self.opt.output_nc if self.opt.direction == 'BtoA' else self.opt.input_nc
self.transform = get_transform(opt, grayscale=(input_nc == 1))
def __getitem__(self, index):
"""Return a data point and its metadata information.
Parameters:
index - - a random integer for data indexing
Returns a dictionary that contains A and A_paths
A(tensor) - - an image in one domain
A_paths(str) - - the path of the image
"""
A_path = self.A_paths[index]
A_img = Image.open(A_path).convert('RGB')
A = self.transform(A_img)
return {
'A': A, 'A_paths': A_path}
def __len__(self):
"""Return the total number of images in the dataset."""
if self.opt.max_dataset_size == -1:
return len(self.A_paths)
else:
return self.opt.max_dataset_sizemetrics/:
定义评价指标。
models/:

base_model.py:
最基本的model类,被其他model类继承。它定义了一些helper functions:保存/加载模型,更新优化器,计算当前损失等等。
cycle_gan_model.py:
定义CycleGANModel类,继承BaseModel。
class CycleGANModel(BaseModel):
"""
This class implements the CycleGAN model, for learning image-to-image translation without paired data.
The model training requires '--dataset_mode unaligned' dataset.
By default, it uses a '--netG resnet_9blocks' ResNet generator,
a '--netD basic' discriminator (PatchGAN introduced by pix2pix),
and a least-square GANs objective ('--gan_mode lsgan').
CycleGAN paper: https://arxiv.org/pdf/1703.10593.pdf
"""
@staticmethod
def modify_commandline_options(parser, is_train=True):
"""Add new dataset-specific options, and rewrite default values for existing options.
Parameters:
parser -- original option parser
is_train (bool) -- whether training phase or test phase. You can use this flag to add training-specific or test-specific options.
Returns:
the modified parser.
For CycleGAN, in addition to GAN losses, we introduce lambda_A, lambda_B, and lambda_identity for the following losses.
A (source domain), B (target domain).
Generators: G_A: A -> B; G_B: B -> A.
Discriminators: D_A: G_A(A) vs. B; D_B: G_B(B) vs. A.
Forward cycle loss: lambda_A * ||G_B(G_A(A)) - A|| (Eqn. (2) in the paper)
Backward cycle loss: lambda_B * ||G_A(G_B(B)) - B|| (Eqn. (2) in the paper)
Identity loss (optional): lambda_identity * (||G_A(B) - B|| * lambda_B + ||G_B(A) - A|| * lambda_A) (Sec 5.2 "Photo generation from paintings" in the paper)
Dropout is not used in the original CycleGAN paper.
"""
assert is_train
parser = super(CycleGANModel, CycleGANModel).modify_commandline_options(parser, is_train)
parser.add_argument('--restore_G_A_path', type=str, default=None,
help='the path to restore the generator G_A')
parser.add_argument('--restore_D_A_path', type=str, default=None,
help='the path to restore the discriminator D_A')
parser.add_argument('--restore_G_B_path', type=str, default=None,
help='the path to restore the generator G_B')
parser.add_argument('--restore_D_B_path', type=str, default=None,
help='the path to restore the discriminator D_B')
parser.add_argument('--lambda_A', type=float, default=10.0,
help='weight for cycle loss (A -> B -> A)')
parser.add_argument('--lambda_B', type=float, default=10.0,
help='weight for cycle loss (B -> A -> B)')
parser.add_argument('--lambda_identity', type=float, default=0.5,
help='use identity mapping. '
'Setting lambda_identity other than 0 has an effect of scaling the weight of the identity mapping loss. '
'For example, if the weight of the identity loss should be 10 times smaller than the weight of the reconstruction loss, please set lambda_identity = 0.1')
parser.add_argument('--real_stat_A_path', type& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









