






前言
AI最近十分火热,不管是GPT还是图像生成的MJ都非常的吸引大家的眼球,第二季intel 黑客松我选择了自由赛道,并使用Intel Distribution for Python实现了一个房价预测模型,但是因为参与的时间比较短,intel拓展的学习使用比较少,随着intel 黑客松第三季重磅来袭,接着这个机会,我将优化之前的程序,重新更新博客的内容。
一、学习目标
在房地产市场中,预测房价是一个非常重要的问题。许多因素影响着房价,例如位置、房屋大小、设施、年龄等等。使用机器学习算法可以帮助我们预测房价并做出更好的决策。在本次大赛中,我们将使用Intel® Distribution for Python、Intel® Extension for Scikit-learn编写一个机器学习模型,通过房屋的特征来预测房价。
intel Distribution for Python是一个基于Python的开源机器学习工具包,它包含了Intel的数学库和编译器,可以用于加速Python程序的执行。以下是所需的环境和搭建教程:
所需环境:
Python 3.5或更高版本
pip或者conda
Intel® Distribution for Python
Intel® Extension for Scikit-learn
Intel® Extension for Scikit-learn:
借助Intel® Extension for Scikit-learn,您可以加速您的 Scikit-learn 应用程序,并且不需修改 Scikit-Learn原有代码结构,可带来超过 10-100 倍的加速。
安装Python:首先,需要安装Python。您可以从Python官方网站下载和安装Python。
Intel® Extension for Scikit-learn可以通过intel官网去下载对应系统的版本。建议使用conda环境。方便后续使用。
在安装完上述软件后,我们将开始使用Intel® Extension for Scikit-learn实现一个预测房价的案例。
二、学习过程
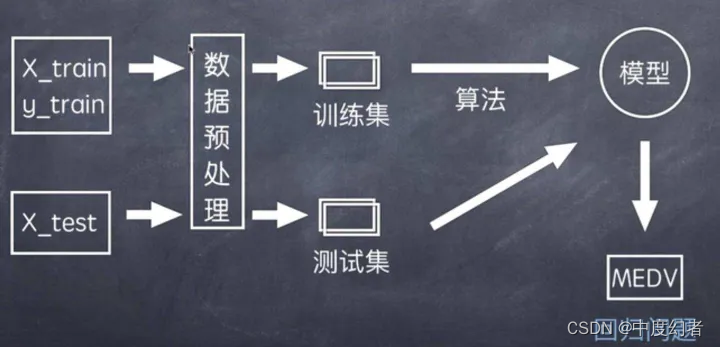
在开始任何机器学习任务之前,数据收集和预处理是非常重要的步骤。对于房价预测,我们需要收集有关房子特性的数据,例如房间数量、浴室数量、房屋类型、地理位置等。还需要收集房价数据,以了解房子的实际价格。在数据预处理阶段,我们需要对数据进行清洗、缺失值填充、特征编码等操作,以确保数据的质量和可用性。
1.输入数据集
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/test.csv')

训练样本
train和test分别是训练集和测试集,分别有 1460 个样本,80 个特征。
SalePrice列代表房价,是我们要预测的。
2.房价分布
因为我们任务是预测房价,所以在数据集中核心要关注的就是房价(SalePrice) 一列的取值分布。
def basic_cond(seq='SalePrice'):#打印出特征基本情况
print(train[seq].describe())#售价详情
print(train[seq].skew())#售价偏度
print(train[seq].kurt())#售价的峰度
print(train.shape)#表格数据计数
房价取值分布
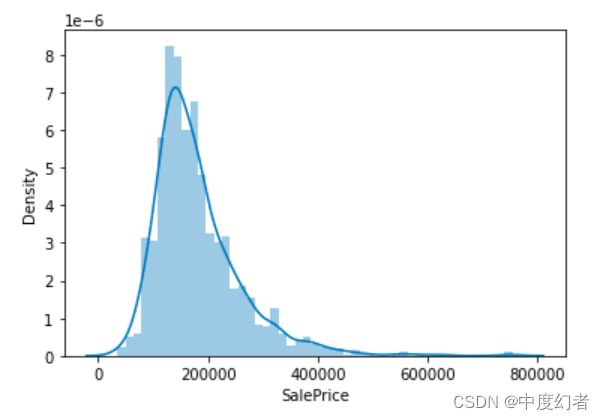
从图上可以看出,SalePrice列峰值比较陡,并且峰值向左偏。
也可以直接调用skew()和kurt()函数计算SalePrice具体的偏度和峰度值。
对于偏度和峰度都比较大的情况,建议对SalePrice列取log()进行平滑。
3.与房价相关的特征
在房价预测问题中,我们需要选择合适的特征来描述房子。一些常见的特征包括房间数量、浴室数量、房屋类型、地理位置等。我们还需要进行特征工程,以提取更有用的信息。例如,我们可以将房子特性转换为数值特征,并使用因子化方法来减少特征的维度,从而提高模型的性能。
了解完SalePrice的分布后,我们可以计算 80 个特征与SalePrice的相关关系。
重点关注与SalePrice相关性最强的 10 个特征。
def cor_mat(seq='SalePrice'):
corrmat = train.corr()#建立特征相关系数矩阵
k = 10 #矩阵维度 这里可以用8或者10
cols = corrmat.nlargest(k, seq)[seq].index#找到最大的K个和售价相关的
cm = np.corrcoef(train[cols].values.T)
hm = sns.heatmap(cm, annot=True,annot_kws={'size': k}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
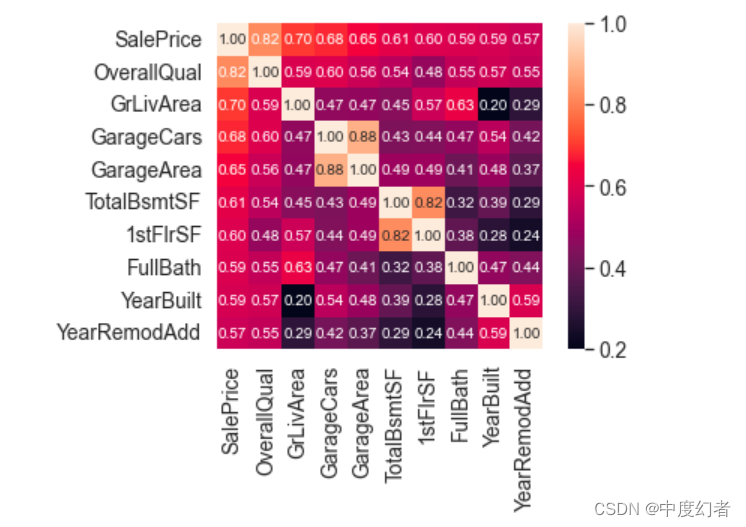
与SalePrice高度相关的特征
OverallQual(房子材料和装饰)、GrLivArea(地上居住面积)、GarageCars(车库容量)和 TotalBsmtSF(地下室面积)跟SalePrice有很强的相关性。
这些特征在后面做特征工程时也会重点关注。
4 .数据填充、清洗
由于数据集样本量很少,离群点不利于我们后面训练模型。
所以需要计算每个数值特性的离群点,剔除掉离群次数最多的样本。
并且对于缺失值进行填充。
def fill():
cols=["MasVnrArea", "BsmtUnfSF", "TotalBsmtSF", "GarageCars", "BsmtFinSF2", "BsmtFinSF1", "GarageArea"]
for col in cols:
combine[col].fillna(0, inplace=True)
cols1 = ["PoolQC" , "MiscFeature", "Alley", "Fence", "FireplaceQu", "GarageQual", "GarageCond", "GarageFinish", "GarageYrBlt", "GarageType", "BsmtExposure", "BsmtCond", "BsmtQual", "BsmtFinType2", "BsmtFinType1", "MasVnrType"]
for col in cols1:
combine[col].fillna("None", inplace=True)
cols2 = ["MSZoning", "BsmtFullBath", "BsmtHalfBath", "Utilities", "Functional", "Electrical", "KitchenQual", "SaleType","Exterior1st", "Exterior2nd"]
for col in cols2:
combine[col].fillna(combine[col].mode()[0], inplace=True)
combine.isnull().sum()[combine.isnull().sum()>0]
NumStr = ["MSSubClass","BsmtFullBath","BsmtHalfBath","HalfBath","BedroomAbvGr","KitchenAbvGr","MoSold","YrSold","YearBuilt","YearRemodAdd","LowQualFinSF","GarageYrBlt"]
for col in NumStr:
combine[col]=combine[col].astype(str)
def fill_area():#先按照频率分组然后用中位数填充
combine['LotAreaCut'] = pd.qcut(combine.LotArea,10)
combine['LotFrontage']=combine.groupby(['LotAreaCut'])['LotFrontage'].transform(lambda x: x.fillna(x.median()))
# 获取数值型特征
numeric_features = train.dtypes[train.dtypes != 'object'].index
# 计算每个特征的离群样本
for feature in numeric_features:
outs = detect_outliers(train[feature], train['SalePrice'],top=5, plot=False)
all_outliers.extend(outs)
# 输出离群次数最多的样本
print(Counter(all_outliers).most_common())
# 剔除离群样本
train = train.drop(train.index[outliers])
detect_outliers()是自定义函数,用sklearn库的LocalOutlierFactor算法计算离群点。
到这里, EDA 就完成了。最后,将训练集和测试集合并,进行下面的特征工程。
5 .特征工程
MSSubClass(房屋类型)、YrSold(销售年份)和MoSold(销售月份)是离散型特征,接下来实现离散类型的数值化,创建新的数值化特征,增加了22个。
def map_values():#进行数值化映射
combine["oMSSubClass"] = combine.MSSubClass.map({'180':1,
'30':2, '45':2,
'190':3, '50':3, '90':3,
'85':4, '40':4, '160':4,
'70':5, '20':5, '75':5, '80':5, '150':5,
'120': 6, '60':6})
combine["oMSZoning"] = combine.MSZoning.map({'C (all)':1, 'RH':2, 'RM':2, 'RL':3, 'FV':4})
......
填充缺失值没有统一的标准,需要根据不同的特征来决定按照什么样的方式来填充。
对于几乎都是缺失值,或单一取值占比高(99.94%)的特征可以直接删除。
combine.drop("LotAreaCut",axis=1,inplace=True)#删除无用的变量
combine.drop(['SalePrice'],axis=1,inplace=True)#删除无用的变量
做完特征工程,需要从features中将训练集和测试集重新分离出来,构造最终的训练数据。
X = features.iloc[:len(y), :]
X_sub = features.iloc[len(y):, :]
X = np.array(X.copy())
y = np.array(y)
X_sub = np.array(X_sub.copy())
6 .模型训练
在选择模型时,我们需要考虑问题的特点和数据的性质。对于房价预测问题,我们可以选择使用线性回归、决策树、随机森林、神经网络等模型。在训练模型时,我们需要使用划分数据集的方法,将数据集分为训练集、验证集和测试集。通过调整模型的超参数和使用交叉验证等方法,可以提高模型的性能和泛化能力。
以岭回归(Ridge) 为例,定义一个含参的Ridge回归,使用Ridge进行训练模型。
ridge=Ridge(alpha=60)#定义一个含参的ridge回归
ridge.fit(X_scaled,y_log)#使用ridge进行训练模型
FI_lasso = pd.DataFrame({"Feature Importance":ridge.coef_}, index=data_pipe.columns)#对特征进行排序,按照其重要性
#show_important(FI_lasso)
pipe = Pipeline([
('labenc', labelenc()),#对于年代进行标准化
('add_feature', add_feature(additional=2)),#组合特征
('skew_dummies', skew_dummies(skew=1)),#对标签进行矩阵编码
])#构建一个新的流水线
7 .模型评估
在完成模型训练后,我们需要对模型进行评估和优化。可以使用一些评估指标,如均方误差(MSE)、平均绝对误差(MAE)和R平方值,来评估模型的性能。我们还可以使用交叉验证方法来评估模型的泛化能力。如果模型的性能不够好,我们可以尝试调整超参数和使用更复杂的模型,或者进行特征选择和特征工程,以提高模型的性能和泛化能力。
lasso = Lasso(alpha=0.0005,max_iter=10000)
ridge = Ridge(alpha=60)
svr = SVR(gamma= 0.0004,kernel='rbf',C=13,epsilon=0.009)
ker = KernelRidge(alpha=0.2 ,kernel='polynomial',degree=3 , coef0=0.8)
ela = ElasticNet(alpha=0.005,l1_ratio=0.08,max_iter=10000)
bay = BayesianRidge()
mod = [lasso,ridge,svr,ker,ela,bay]#设定了算法的参数
a = Imputer().fit_transform(X_scaled)#处理训练集的缺失值
b = Imputer().fit_transform(y_log.values.reshape(-1,1)).ravel()#标准化售价值
集成建模评估-权重法#
w1 = 0.02
w2 = 0.2
w3 = 0.25
w4 = 0.3
w5 = 0.03
w6 = 0.2
weight=[w1,w2,w3,w4,w5,w6]#设定了权重
weight_avg = AverageWeight(mod = [svr,ker],weight=[0.55,0.45])#根据权重获得模型
score = rmse_cv(weight_avg,X_scaled,y_log)#返回分数
# 训练模型
ridge.fit(X_scaled,y_log)#使用ridge进行训练模型
# 输出测试结果
weight_avg.fit(a,b)
pred = np.exp(weight_avg.predict(test_X_scaled))
result=pd.DataFrame({'Id':test.Id, 'SalePrice':pred})
result.to_csv("submission_weight.csv",index=False)
stack_model.fit(a,b)
pred = np.exp(stack_model.predict(test_X_scaled))
result=pd.DataFrame({'Id':test.Id, 'SalePrice':pred})
result.to_csv("submission_stacking.csv",index=False)
总结
通过patch_sklearn()开启和unpatch_sklearn()关闭Intel® Extension for Scikit-learn,可以看出不仅可以提升训练速度,Intel拓展还可以提升模型推理预测速度,在某些场景下甚至达到数千倍的性能提升
房价预测是一个经典的机器学习问题,需要充分考虑数据的特点和问题的特点,选择合适的模型和特征,并进行充分的训练和优化,才能得到一个高性能的预测模型。
通过学习intel 官网的案例,结合之前学习的房价预测算法,重新进行优化,我对于数据收集和预处理、特征选择和特征工程、模型选择和训练、模型评估和优化有了整体的认识,并使用Intel Distribution for Python实现了房价预测算法的实现。















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









