







今天在线上使用mysqldump将数据表从一个库导入到另外一个库,结果速度特别慢,印象中有个多线程的数据导入导出工具Mydumper,于是简单的调查和测试一下。
下午导数据的过程中,这个表是没有更新的,因此不需要确保多个数据之间的一致性,就简单的写个shell脚本启动多个mysqldumper来导数据,这样有几个问题:
需要处理表数据大小不均匀的问题,有的会很快结束,有的会比较慢。
如果需要保证多个导出之间的一致性时,则无法保证。
Mydumper是一个使用c语言编写的多线程导出导入工具,并且能够保证多个表之间的一致性。Mydumper已经好几篇blog在讨论:Mydumper性能测试,Mydumper使用和源码分析。通过stronghearted的测试,我们看到不是线程越多越好,6个线程的时候速度最快(这个肯定跟机器的配置等诸多因素有关,只能作为一个经验值而不是绝对值,机器好的时候,线程越多越好)。
一、原理
mydumper工作流程图
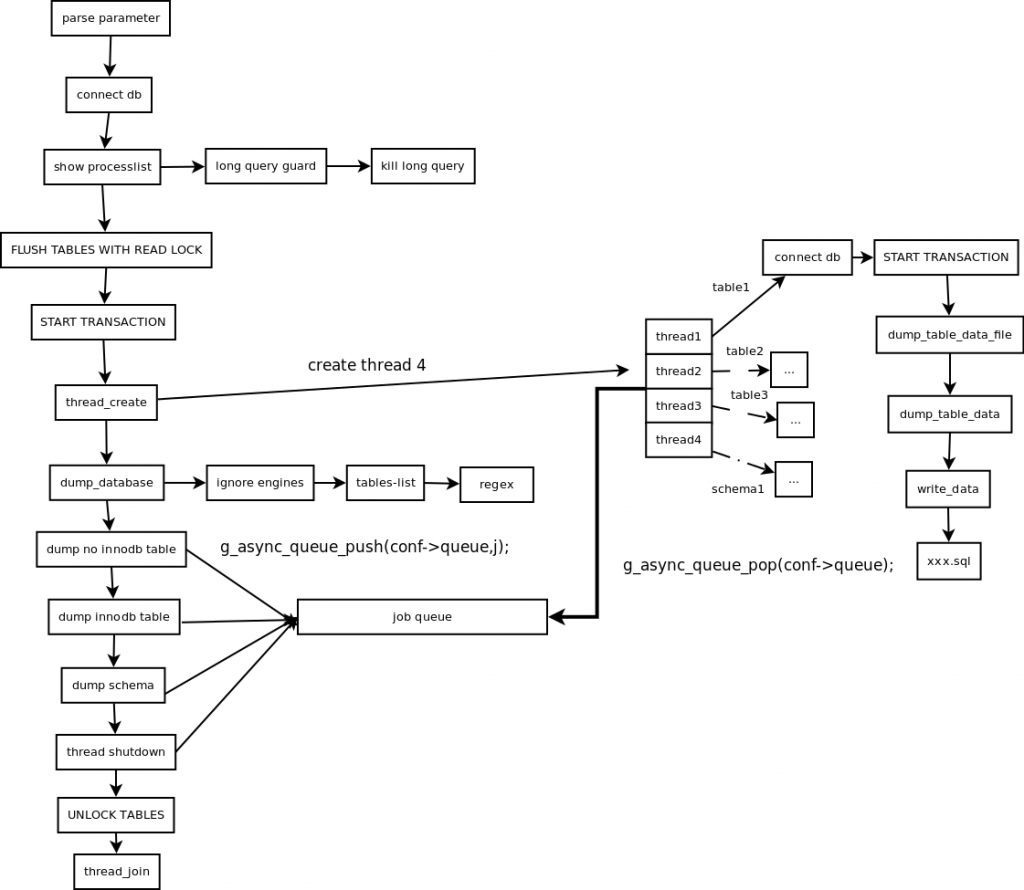
主要步骤概括
主线程 FLUSH TABLES WITH READ LOCK, 施加全局只读锁,以阻止DML语句写入,保证数据的一致性
读取当前时间点的二进制日志文件名和日志写入的位置并记录在metadata文件中,以供即使点恢复使用 N个(线程数可以指定,默认是4)
dump线程 START TRANSACTION WITH CONSISTENT SNAPSHOT; 开启读一致的事物
dump non-InnoDB tables, 首先导出非事物引擎的表
主线程 UNLOCK TABLES
非事物引擎备份完后,释放全局只读锁
dump InnoDB tables, 基于事物导出InnoDB表 事物结束
备份所生成的文件
所有的备份文件在一个目录中,目录可以自己指定 目录中包含一个metadata文件
记录了备份数据库在备份时间点的二进制日志文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2165
2165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









