







 本文介绍了关联规则挖掘中的Apriori算法,并提供了Java核心代码实现,用于找出数据集中的频繁项集。算法通过合并与修剪过程,基于最小支持度条件挖掘频繁模式。
本文介绍了关联规则挖掘中的Apriori算法,并提供了Java核心代码实现,用于找出数据集中的频繁项集。算法通过合并与修剪过程,基于最小支持度条件挖掘频繁模式。
[ 关联规则挖掘用于寻找给定数据集中项之间的有趣的关联或相关关系。 关联规则揭示了数据项间的未知的依赖关系,根据所挖掘的关联关系,可以从� ...]
2013年11月19日注:以下算法中,combine算法实现不正确,应该是从已有的频繁中来产生。需要进一步修改
=================================================================================
Apriori算法原理:
如果某个项集是频繁的,那么它所有的子集也是频繁的。如果一个项集是非频繁的,那么它所有的超集也是非频繁的。
示意图
图一:[频繁模式是频繁地出现在数据集中的模式(如项集、子序列或者子结构)。例如,频繁地同时出现在交易数据集中的商品(如牛奶和面包)的集合是频繁项集。]
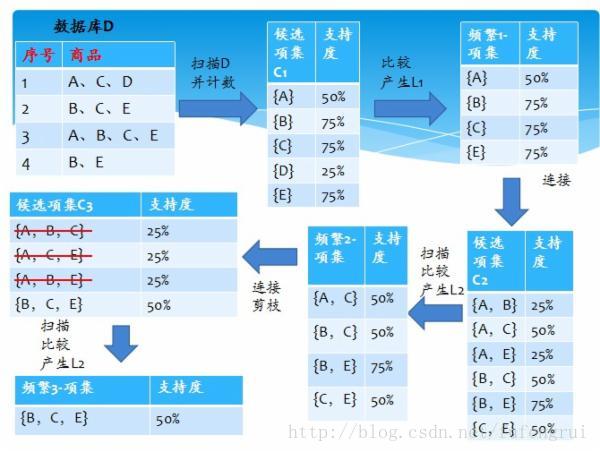
图二:
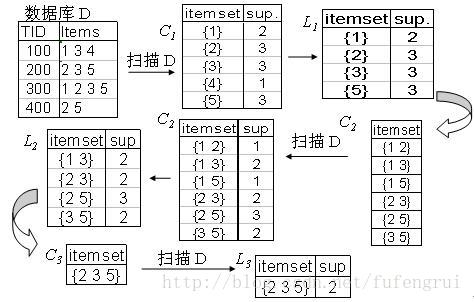
package cn.ffr.frequent.apriori;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
/**
* Apriori的核心代码实现
* @author neu_fufengrui@163.com
*/
public class Apriori {
public static final String STRING_SPLIT = ",";
/**
* 主要的计算方法
* @param data 数据集
* @param minSupport 最小支持度
* @param maxLoop 最大执行次数,设NULL为获取最终结果
* @param containSet 结果中必须包含的子集
* @return
*/
public Map compute(List data, Double minSupport, Integer maxLoop, String[] containSet){
//校验
if(data == null || data.size() <= 0){
return null;
}
//初始化
Map result
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









