







参考书目:FIT9133 textbook from Alexandria, Monash University(AU)
目录章节
- 介绍与准备
2. python基础
3. 数据结构,数据存储类型,控制结构
1. 介绍与准备
1.1 介绍
Python是一门高级编程语言,其他比如C,C++,Java,Ruby,GO,Julia等等。
它的特点就是:
- 入门简单,
- external package全面,
- 而且还在不断更新,
- 运用范围广
非常适用数据分析,机器学习等当今众多热门计算机领域。
1.2 准备
在开始python的实际操作之前,我们先做一些准备工作,安装python的IDE
- Anaconda (Jupyter Notebook)
- 首先进入Anaconda下载页面,下载适合自己电脑的版本

-
- 安装之后,打开Anaconda Navigator,找到Jupyter Notebook,点击Launch
- 找到自己想要保存文件的地址,创建新文件即可使用
- Jupyter Notebook交互性很强,很适合新人进行练习和编写程序,如果大家感兴趣,可以自行学习Jupyter Notebook更加细节性的功能以及Markdown的使用,对大家未来的高效率编程,很有帮助
- Pycharm
- 进入Pycharm下载网址,下载自己的版本
-
- Pycharm安装比较简单,方便
- 它适合中大型项目编写程序
- 对于非常熟练的python程序员来说,是不可少的IDE
- 总结
- 这两个IDE大家可以多试一试,或者可以试试其他IDE,适合自己的才是最好的
2. python基础
2.1
概念:
print("Hello World")
a = 1在上面的code中,“Hello World”就是string的对象(object),1就是整数integer,int,的对象。a是变量(variable)
命名规则:
当自定义一个变量名的时候,我们有以下原则:
- 变量名只能含有a-z,A-Z,0-9,以及下划线( _ )
- Case sensitive并且不能以数字开头
- 没有长度限制
- 以下的关键词有特殊含义,不能用下面的关键词命名
and as assert break class continue
def del elif else except finally
for from global if import in
is lambda nonlocal not or pass
raise return try while with yield
False None True- 如果你用以上关键词作为变量名,系统会报错,加以修改,则可以使用
False_variable = False
True_123 = 123- 虽然可以用一个字母作为变量名,但是不推荐在写项目时候使用!请尽量使用有意义的变量名!
#不推荐
a = 1
b = 2
#推荐
first_var = 1
second_var = 2- 一般有两种命名风格:
- 两个单词中加入下划线
first_variable-
- camelCase style
firstVariable-
- 推荐在你的程序中,使用一种命名风格
2.2 核心数据类型
数字:
- 整数integer(int)
- 实数或者浮点数float (float)
first_number = 12 #integer
second_number = -123 #integer
pi = 3.1416 #float
gamma = 0.577215 #float
e_multiple_1000 = 2.718e3 #float布尔值 Booleans:
- 只有两种布尔对象值:True,False
yes = True
no = False
type(yes) # bool
type(no) # bool
yes == no # False
#在这里提及一下双等于,==,和等于,=,的区别,双等于代表判断前后两者是否等价,
#等于代表的是,对前面的变量进行赋值
12 < 123 # True字符串 strings:
- 字母,"a", 数字,"12", 符号,"!", 空格," ", tab, "t", 跨行线, "n"
- 单引号,'',和双引号,"", 都可以使用
- 字符串内置方法,常用的有
new_string = "Welcome"
len(new_string) # 7
new_string.upper() # WELCOME
new_string.lower() # welcome
new_string.count("e") # 22.3 运算与表达式
表达式基本格式:
result_variable = <operand> <operator> <operand>算术运算符:
1 + 8 # 9
8 - 1 # 7
1 * 8 # 8
9 / 3 # 3.0
9 // 3 # 3
2 ** 3 # 8
15 % 10 # 5
# 符号中的运算优先级
# * / 高于 + -
# 括号的优先级很高关系运算符:
a < b
a > b
a <= b
a >= b
a == b
a != b # 判断两者是否不等于
12 < 123 # True
"ab" < "abc" # True
"a" < "b" # True, 按照字典序比较
123 == "123" # False
123 < "123" # 这个会报错,integer和string不能进行比较,这不是同一个数据类型
1 + 2 >= 2 + 1 # True
4 // 2 == 2 // 4 # False逻辑运算符:
a = 4
b = 2
a % 2 == 0 and a > 0 # True
a < 10 and a < b # False
a < 10 or a < b # True2.4 Statements 和 赋值 Assignments(请原谅我实在找不到适合的中文名词)
多个statements组成了一个python程序
message = "Welcome to world"
# 这是个赋值除了赋值,调取函数也是另一种statement,例如:
message = "Welcome to world"
print(message) # "Welcome to world"
# 在这里,message作为一个argument,放在print()函数里面,去展示变量message的值如果一个statement太长,你可以使用 把它分开成几段,不影响statement里面的运行内容
boolean_result = counting_value > 0
and
counting_value < 100注意在python之中,每行的字数限制建议在79之内,详情参见
PEP 8 -- Style Guide for Python Codewww.python.org
Block statement:
在python中,有一些特殊的控制结构可以使几行代码变成一个整体,那几行代码仅仅在这一个block中运行。
counter = 5
while counter >= 0:
print(counter)
counter -= 1 #这是counter = counter - 1的简写,代表counter自身的值减1
print("OK")
if counter = -1:
print("Negative")
# 在这while循环语句中,counter >= 0是执行条件,满足该条件,while循环语句才会循环下去,
# 冒号":"之后,代表这个while循环语句的block的起始,每行代码前会有缩进(indentation),相同缩进的
# 代码代表仍然处于同一个block,直到缩进结束。
# 例如 print("OK")前面没有缩进,代表这行代码没有在while的block之中,并且while的block已经结束。
# if开始了新的block
# 在执行这些block的时候,只有当while,if它们的条件不再满足的时候,block停止执行2.5 标准输入和输出
标准输入
a = int(input("Enter the first number: "))
b = int(input("Enter the second number: "))
print("The addition of a and b is ", a + b)
print("The addition of a and b is " + str(a+b))
#字符串之间也有加法运算,但必须保证双方都是字符串类型,上面的例子中,a+b的结果是整数类型,
#所以,我们用str()将整数类型转换成字符串类型input() 是python内置函数,用于调取外部数据,例如上面代码,python会让用户分别输入a的输入值,和b的输入值,然后再将a,b进行加法计算,然后在用print()函数显示出计算结果。
标准输出
在上面代码中,print()就是输出需要展示的内容,字符串,运算都可以作为print()的argument。
特殊用法
pi = 3.14159
print("The value of pi is %5.4f" % pi) # The value of pi is 3.1416
# 任何变量名处于双引号或者单引号之中,都会变成字符串,所以使用%f能把变量的值输出出来。
print(pi) # 3.14159
print("pi") # pi
print("%.2f" % pi) # 3.15
# 这个用法在python编程之中还会出现,大家有兴趣可以在StackOverflow搜索更多的例子3. 数据结构,数据存储类型,控制结构
3.1 数据类型和数据结构
两种数据类型
- primitive data type
- 例子,integer(int),floating point number(float),Boolean values (bool)
- abstract data type(ADT)
- 例子,binary tree,queue,stack,hash table,heap等等(这里写的这些ADT都是非常重要的,大家在处理数据类的任务中会遇到)
两种数据结构
- Array-based structure
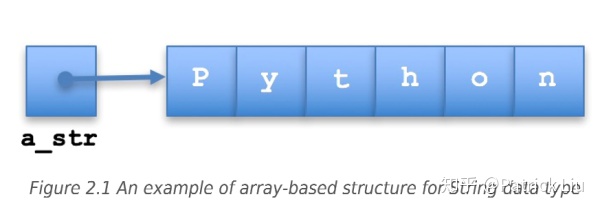
-
- array占的记忆储存更小
- 在程序运行最开始的时候,所有的元素(例如p,y,t,h,o,n)都需要提前准备好,这时候优先考虑array-based structure
2. Linked-based structure
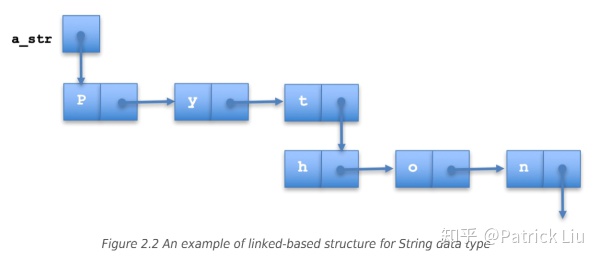
在随机添加新的元素,或者删掉已存在的元素(例如我们想添加n,删除h),优先考虑使用Linked-based structure。(我们随机使用任一元素时,array-based structure更快一些)
3.2 数据存储类型(建议记住英文名词)
字符串(Strings)
当我们想展示字符串类型的数据时候,print()是不错python内置函数
a_string = "Hello World"
print(a_string) # Hello World在以前的章节提到,str()是可以将其他数据类型的数据转换成字符串数据类型
a_number = 5
type(a_number) # int
# type()这个函数是用于显示这个数据的类型
type(str(a_number)) # str
# 函数里面嵌套函数,先运行里面的str()函数,然后再运行外面的type()函数前面也提及,字符串之间也是存在加法运算的,但是两个运算对象必须都得是字符串类型
number = 5
print(str(number) + " is a number") # 5 is a number
print(number + " is a number") # !!!会报错!!!"".join() (.join()的用法介绍)会在后面的列表介绍
索引和切片
我们知道,python索引是从0开始,也就是第一个元素的索引是0,记住!!!一个空格也算一个元素
a_string = "Hello World"
print(a_string[0]) # H
print(a_string[0:2]) # He
print(a_string[0:4]) # Hell
# 0:4代表选择索引为0到索引为3的字符串元素
len(a_string) # 11
#多少个元素
print(a_string[0:12:2]) # HloWrd
# 从索引0开始,选择间隔为2的元素,直到索引11的元素,
print(a_string[12:0:-1]) # dlrow olle
# 输出倒序字符串,除了第一个
print(a_string[:]) # Hello World
# 复制以前所有字符串数据,并且显示全部字符串
print(a_string[::-1]) # dlroW olleH
# 输出倒序全部串你可以读取任意位置的元素,但是不能改变单一的字母,因为字符串是immutable,那些又能mutable我会在后面继续讲解
下面是非常有用的string内置方法
a_string = "Hello"
a_string.split("e") # ["H","llo"]
a_string.split("l") # ["He","","o"]
a_string.upper() # HELLO
a_string.lower() # hello
a_string.isalpha() # True
"5".isdigit() # True
a_string.replace("H", "U") # Uello
"00000Wow00000".strip("0") # Wow数据存储类型的通用知识点
"in" statements (可适用于其他的数据存储类型,大家可以在编程的时候多试试)
用于两者之间是否有从属关系,A是否被B包含,结果返回布尔值 (Booleans-True, False)
a = 1
c = "1"
b = [1,2,3]
if a in b:
print("a is in b")
else:
print("not in")
# a is in b
if c in b:
print("c is in b")
else:
print("not in")
# not in索引和切片
原理和字符串的是一样的,第一个元素的索引是0,切片的时候,[0:6],代表选择索引为0,到索引为5的元素。
a = ["a","b","c","d","e","f"]
a[0:3] # ["a","b","c"]
a[1:3] # ["b","c"]
a[0:5:2] # ["a","c","e"]分析方法
寻找最大数和最小数
a = [1,2,5,7,9]
max(a) # 9
min(a) # 1数据储存长度
a = [1,3,5]
len(a) # 3数据存储的搜索
a = ["p", "p", "o", "u"]
a.index("p") # 0
a.index("o") # 2
# 寻找第一个出现的元素,并且返还它的索引,例如上面,第一个"p"的索引是0
a.count("p") # 2
# 显示该元素出现的次数,"p"出现了两次列表(Lists)
创建列表
first_list = [] # 创建空列表
second_list = [1,"u",3]
third_list = [1] * 6 # 创建一个含重复元素的列表
print(third_list) # [1,1,1,1,1,1]列表加新元素
char_list = []
char_list.append("a")
print(char_list) # ["a"]
char_list.append("b")
print(char_list) # ["a","b"]
# 注意,char_list.append()是将新的元素加入到最后面的位置
char_list.insert(1,"c")
print(char_list) # ["a","c","b"]
# char_list.insert()需要提供两个arguments,第一个是你想放入的位置,第二个是你想放入的元素列表移除元素
num_list = [3,5,6,7,3,0]
num_list.pop() # 0
# 此时num_list还剩下 [3,5,6,7,3]
num_list.pop(2) # 6
# 此时num_list还剩下 [3,5,7,3],我们移除了索引为2的元素
new_list = [6,2,4,1,6,1]
new_list.remove(1)
# 此时new_list还剩下 [6,2,4,6,1],移除了列表里面的第一个1列表的纂改
another_list = [2,5,4,1,3]
another_list.sort()
print(another_list) # [1,2,3,4,5]
another_List.reverse()
print(another_list) # [5,4,3,2,1]元组(Tuples)
创建元组
new_tuple = () # 创建空的元组
a_tuple = (1,) # 创建只含一个元素的元组,必须要接一个逗号!!!
boy_tuple = (1,2,3,4,5,)
girl_tuple = (1,2,3,4,5) # 两者都是正确的形式
a_list = [1,2,3]
change_to_tuple = tuple(a_list)
print(change_to_tuple) # (1,2,3)
# 这个非常有用,列表(list)是mutable,而元组(tuple)是immutable元组和列表的区别(为什么要使用元组?)
- 元组不能改变,这个能防止一些恒定且重要信息被强行改写
- 读取元组要比读取列表快上很多,当处理特别大的数据时候,元组和列表的处理速度就会体现出来
- 元组会经常用来创建词典(Dictionaries)数据存储类型
集合(Sets)
集合特性:元素独一性,无序性
创建集合
empty_set = set()
a_list = [1,2,3]
change_to_set = set(a_list) # list变set 可以用set()
a_set = {1,2,3}集合的比较
不相交(Difference): 如果两个集合没有相同元素,那么返还True
a_set = {1,2}
b_set = {3,4}
a_set.isdisjoint(b_set) # True子集(Subset): 如果一个集合的全部元素都存在另一个集合,那么返回True
a_set = {1,2}
b_set = {1,2,3}
c_set = {1,2,3}
a_set.issubset(b_set) # True
c_set.issubset(b_set) # True
a_set <= b_set # True
c_set <= b_set # True
# 两种形式的比较,
# a_set.issubset(b_set)是method,
# a_set <= b_set是operator真子集(Pure subset): 如果一个集合的全部元素都存在另一个集合,并且两个集合不相等,那么返回True
a_set = {1,2}
b_set = {1,2,3}
a_set < b_set # True超集(Superset): 子集的反向关系
a_set = {1,2,3}
b_set = {1,2}
a_set.issuperset(b_set) # True
a_set >= b_set # True真超集(Pure Superset): 真子集的反向关系
a_set = {1,2,3}
b_set = {1,2}
a_set > b_set # True集合的合并
并集(Union): 返还一个包含两个集合所有元素的新集合
a_set = {1,2,3}
b_set = {3,4,5}
a_set.union(b_set) # {1,2,3,4,5}
a_set | b_set # {1,2,3,4,5}交集(Intersection): 两个集合的相同元素组成一个新的集合
a_set = {1,2,3}
b_set = {3,4,5}
a_set.intersection(b_set) # {3}
a_set & b_set # {3}差集(Difference): 一个集合的元素减去另一个集合的相同元素,前一个集合剩下的元素组成一个新的集合
a_set = {1,2,3}
b_set = {3,4,5}
a_set.difference(b_set) # {1,2}
a_set - b_set # {1,2}对称集(Symmetry): 两个集合不同的元素,共同组成一个新的集合
a_set = {1,2,3}
b_set = {3,4,5}
a_set.symmetric_difference(b_set) # {1,2,4,5}
a_set ^ b_set # {1,2,4,5}
# 上面.symmetric_difference()输入时候很长,你可以先输入.sym,然后按一下tab,就会
# 预测后面你想输入的内容,对于变量名也是适用的集合的纂改
a_set = {1,2,3}
a_set.add(99) # {1,2,3,99}
a_set.remove(99) # {1,2,3}
a_set.clear()
print(a_set) # set()
# 返还一个空set
# set is empty词典(Dictionaries)
创建词典
empty_dict = {} # 建立空的词典
a_dict = {"A":"80 to 100", "B": "70 to 79", "C": "60 to 69"}
# 上面的元素,基本结构是"key:value"
grade = ["A", "B", "C"]
mark = ["80 to 100", "70 to 79", "60 to 69"]
zipped = zip(grade, mark)
final_result = list(zipped) # [("A", "80 to 100"), ("B", "70 to 79"), ("C", "60 to 69")]
# final_result本质是一个列表(list),里面嵌套了元组(tuple)
final_dictionary = dict(final_result) # {"A":"80 to 100", "B": "70 to 79", "C": "60 to 69"}编辑词典
如果key不存在于词典里面,那么就会添加新的key
a_dict = {"A":"80 to 100", "B": "70 to 79", "C": "60 to 69"}
a_dict["D"] = "less than 60"
print(a_dict) # {"A":"80 to 100", "B": "70 to 79", "C": "60 to 69", "D": "less than 60"}如果key存在与词典里面,新的value就会覆盖以前的value
a_dict = {"A":"80 to 100", "B": "70 to 79", "C": "60 to 69"}
a_dict["C"] = "less than 70"
print(a_dict) # {"A":"80 to 100", "B": "70 to 79", "C": "less than 70"}删除一个key和它的value
a_dict = {"A":"80 to 100", "B": "70 to 79", "C": "60 to 69"}
del a_dict["A"]
print(a_dict) # {"B": "70 to 79", "C": "60 to 69"}3.3 控制结构
逻辑表达式
x < y
x > y
x == y
x != y
x <= y
x >= y
x < y and y > 20
x < y or y > 20
# 结果返还True或者False选择结构(if,elif,else)
if this statement is True:
do this code
elif another statement is True:
do this code
else:
do this code instead
# 例子
if a == 0:
print("The result is zero")
elif a == 1:
print("The result is one")
else:
print("Whatever the result is")循环 (Iteration) 结构:
while循环:
while this statement is True:
do this code
# while循环语句,会不断运行它下方的代码,直到不满足
i = 0
sample = [1,2,3,4,5]
sum_1 = 0
while i < 5:
sum_1 += sample[i]
i += 1
print(sum_1) # 15
# 一点要确定循环能在不满足条件后,终止循环,否则,循环会一直运行下去!如果大家遇到很绕的循环语句,可以去python tutor,它会将你的程序运行步骤可视化,非常有助于初学者理解自己的代码,地址如下:
Visualize Python, Java, C, C++, JavaScript, TypeScript, and Ruby code executionwww.pythontutor.comfor 循环:
不同于while循环,for循环会从头到尾读完一个数据存储里面的每一个元素
sample = [1,2,3,4,5]
for item in sample:
print(item)
# 1
# 2
# 3
# 4
# 5
# 读取sample里面的每一个元素,直到读取完最后一个
# 注意!!!item这个名字,可以把它看作一个指针,指向每次读取的元素,
# 这个指针的名字不是固定的,你可以称它apple,each,element等等,看个人喜好
sample = [1,2,3,4,5]
for any_variable_name_you_like in sample:
print(any_variable_name_you_like)
# 1
# 2
# 3
# 4
# 5下面我们将上面代码运行,用python tutor可视化:
第一步:
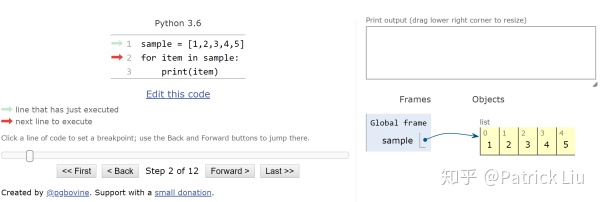
第二步:
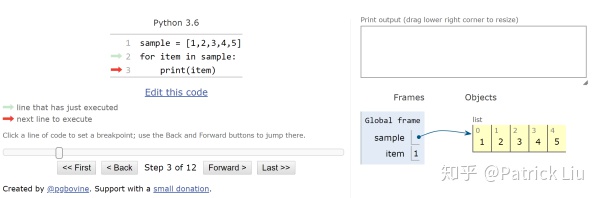
第三步:
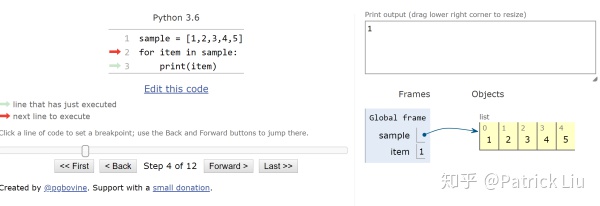
第四步:
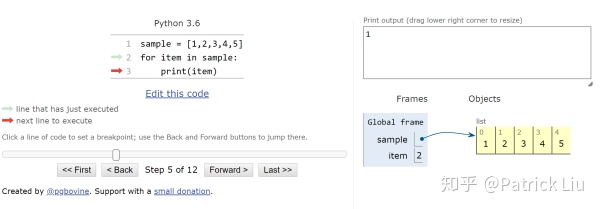
后面几步都是一样的原理,直到最后所有的元素被读取完:
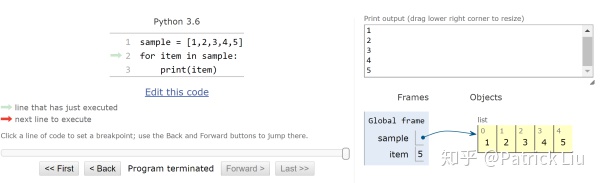
在以前提到词典(dictionary),for循环之中,词典有个特殊而且又方便的用法,能将key和value都能显示出来:
capitals = {"VIC": "Melbourne", "NSW": "Sydney", "QLD": "Brisbane"}
for key, value in capitals.items():
print(key, value)
# VIC Melbourne
# NSW Sydney
# QLD Brisbanerange() 方法:
factorial = 1
for i in range(1, 10):
factorial *= i
print(factorial) # 362880
# 1 * 2 * ... * 9
# range(1,10) 指的是从1到9的数字,不包括10本身
for i in range(5):
print(i)
# 0
# 1
# 2
# 3
# 4
# 如果range()之中只有一个数字5,那么循环从0开始,直到4,不包括5本身
# 利用range(),建立一个dictionary
a_list = ['a','b','c','d']
b_list = [1,2,3,4]
en_dict = {}
for i in range(len(a_list)):
en_dict[a_list[i]] = b_list[i]break的使用 (如何终止循环)
如下面的while循环,如果while一直无限循环,那么我需要一些if控制语句去判定终止的条件,然后再用break去终止这个while循环
i = 0
while True:
if i == 10:
break
else:
i += 1
# 换个写法
i = 0
while i < 10:
i += 13.4 列表解析式 (list comprehension)
a_list = []
for i in range(5):
a_list.append(i * i)
print(a_list) # [0,1,4,9,16]我们用列表解析式后
a_list = [i*i for i in range(10)]我们换一个更复杂的
b_list = []
for x in [2,3,4]:
for y in [5,6,4]:
if y != x:
b_list.append((x,y))
# 换写
b_list = [(x,y) for x in [2,3,4] for y in [5,6,4] if y != x]列表解析式的优点:
- 提高了效率,
- 减少了工作量和错误率,
- 还减少了代码行数,
- 增加了可读性
持续更新中。。。。。。大家有什么建议,不懂的地方,原文有错误的地方,都可以在评论中写出来,我会尽量回复。作者刚入Data Science不久,望各位大佬多多指教。















 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









