






作者:George Novack
翻译:Bach(才云)
校对:星空下的文仔(才云)、bot(才云)
K8sMeetup
为什么要使用机器学习流水线
现在,**机器学习流水线(Machine Learning Pipeline)**被大家给予了极大的关注,它旨在自动化和协调训练机器学习模型所涉及的各个步骤,但是,很多人也不清楚将机器学习工作流程建模为自动流水线到底有什么好处。
当训练新的 ML 模型时,大多数据科学家和 ML 工程师会开发一些新的 Python 脚本或 interactive notebook,以进行数据提取和预处理,来构建用于训练模型的数据集;然后创建几个其他脚本或 notebook 来尝试不同类型的模型或机器学习框架;最后收集、调试指标,评估每个模型在测试数据集上的运行情况,来确定要部署到生产中的模型。
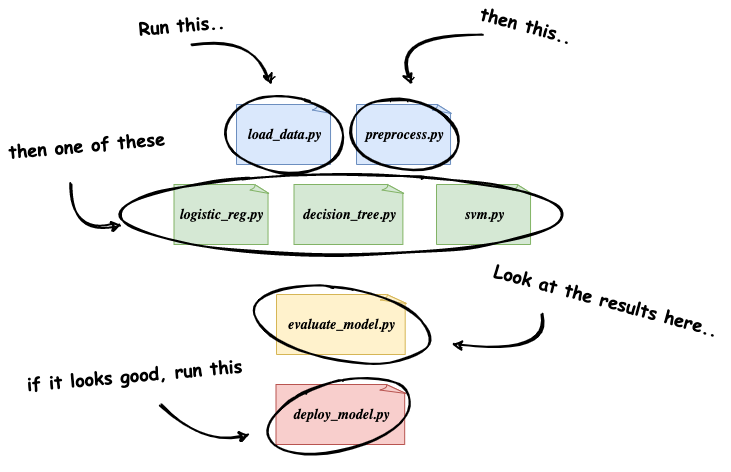
手动机器学习工作流程
显然,这是对真正机器学习工作流程的过度简化,而且这种通用方法需要大量的人工参与,并且除了最初开发该方法的工程师之外,其他人都无法轻易重复使用。
由此,我们使用机器学习流水线来解决这些问题。与其将数据准备、模型训练、模型验证和模型部署视为特定模型中的单一代码库,不如将其视为一系列独立的模块化步骤,让每个步骤都专注于具体任务。
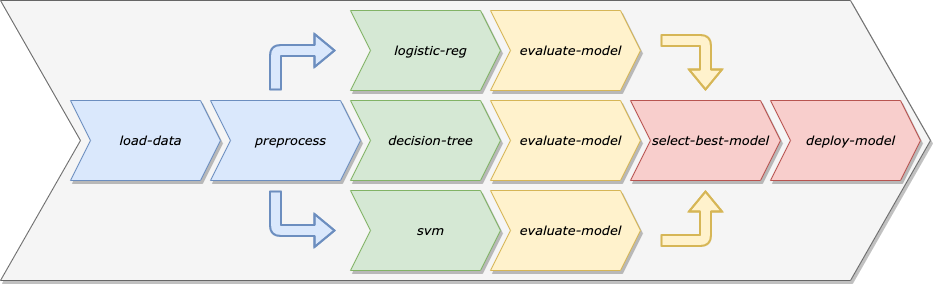
机器学习流水线
将机器学习工作流程建模为机器学习流水线有很多好处:
-
自动化:通过消除手动干预的需求,我们可以安排流水线按照需求重新训练模型,从而确保模型能够适应随时间变化的训练数据。
-
重复使用:由于流水线的步骤与流水线本身是分开的,所以我们可以轻松地在多个流水线中重复使用单个步骤。
-
重复性:任何数据科学家或工程师都可以通过手动工作流程重新运行流水线,这样就很清楚需要以什么顺序运行不同的脚本或 notebook。
-
环境解耦:通过保持机器学习流水线的步骤解耦,我们可以在不同类型的环境中运行不同的步骤。例如,某些数据准备步骤可能需要在大型计算机集群上运行,而模型部署步骤则可能在单个计算机上运行。
K8sMeetup
什么是 Kubeflow
**Kubeflow 是一个基于 Kubernetes 的开源平台,旨在简化机器学习系统的开发和部署。**Kubeflow 在官方文档中被称为 “Kubernetes 机器学习工具包<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









