





Hello,大家好!我是你们的小米,今天又来给大家分享干货啦!最近很多小伙伴们都对排序算法产生了浓厚的兴趣,继上次分享了“手写快排”之后,今天我们再来搞搞堆排(Heap Sort),带大家一起动手手写堆排算法吧!
什么是堆排序?
堆排序是一种基于二叉堆(Binary Heap)这种数据结构的排序算法,属于选择排序的一种。堆排序的时间复杂度为 O(n log n),在最坏的情况下依然表现稳定。和快速排序相比,它没有快排那样的递归深度问题,因此适合用在对稳定性要求高且空间不允许递归的场景下。
堆排序主要有两个步骤:
- 构建大顶堆(或小顶堆):根据数组构建出一个大顶堆(父节点的值大于子节点),这样堆顶元素就是最大值。
- 交换堆顶元素与末尾元素并调整堆:将堆顶元素(最大值)与末尾元素交换,缩小堆的范围,重新调整堆。循环此过程,直到整个数组有序。
堆排序的原理
我们以大顶堆为例来讲解堆排序的核心原理。首先,我们将数组看成一棵完全二叉树,根节点为最大元素。通过堆调整(Heapify)操作,保持堆的结构特性。之后,我们将堆顶元素与最后一个元素交换,再对剩余元素重新调整成堆,最终完成排序。
堆排序的步骤
- 构建堆:将无序数组调整成大顶堆。
- 排序:依次将堆顶元素与末尾元素交换,缩小堆的范围,并重新调整堆。
手写堆排序代码
好啦,理论讲完了,接下来进入我们的实战环节。我们使用Java来手写一个堆排序算法吧!
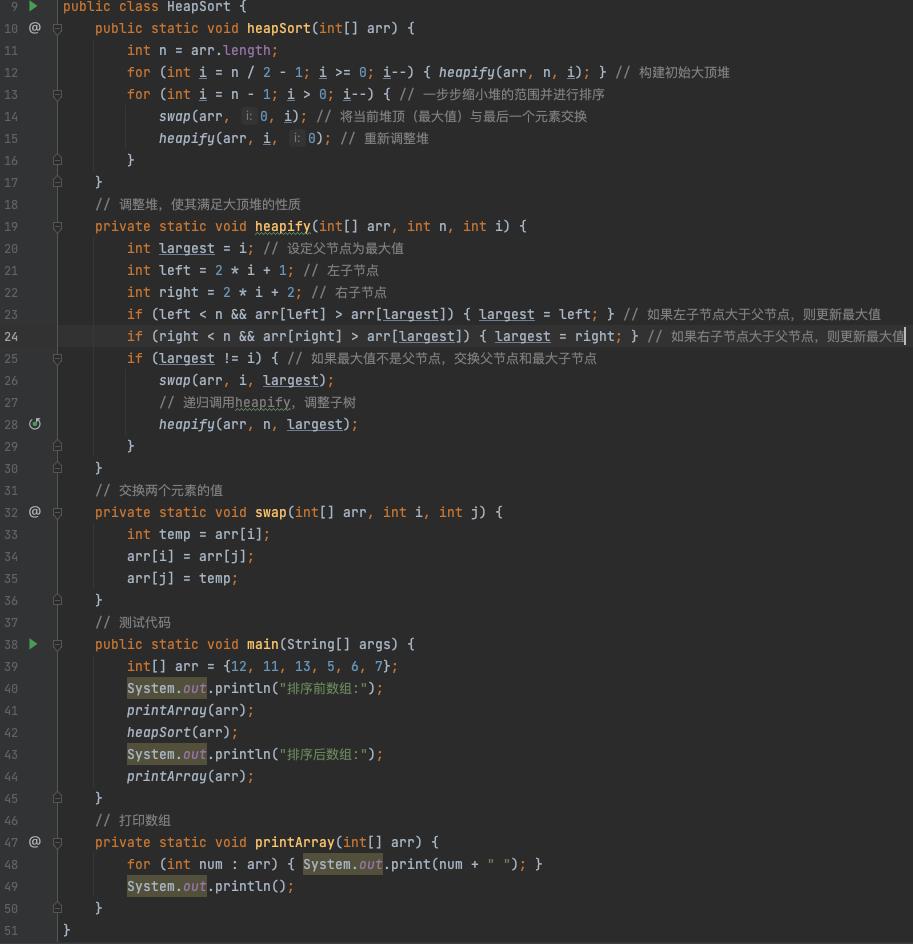
代码讲解
上面的代码实现了堆排序的核心步骤。下面我来一步步讲解:
- 构建初始大顶堆:我们从数组的中间位置开始向前遍历(for (int i = n / 2 - 1; i >= 0; i--)),因为数组的后一半是叶子节点,不需要调整堆。通过调用 heapify 函数,将每一个非叶子节点调整成大顶堆。
- 堆的调整(heapify):heapify 函数用于调整堆的结构。它接收三个参数:数组 arr、数组的长度 n 和当前节点的索引 i。该函数会比较当前节点、左子节点和右子节点的大小,确保父节点是最大值。如果发现子节点比父节点大,则交换节点,然后递归调用 heapify 函数对交换后的子树继续调整。
- 排序:构建好大顶堆后,开始排序。在每次循环中,将堆顶元素(最大值)与数组的最后一个元素交换,然后将剩余的元素重新调整为大顶堆。这个过程会一直进行到堆的范围缩小到只剩一个元素为止,整个数组最终有序。
堆排序的时间复杂度
堆排序的时间复杂度是 O(n log n),这里的 n 是数组的大小。构建大顶堆的时间复杂度为 O(n),每次调整堆的时间复杂度为 O(log n),总共需要调整 n-1 次,所以总的时间复杂度为 O(n log n)。
堆排序的空间复杂度
堆排序是原地排序算法,也就是说它只需要常数个额外的空间,空间复杂度为 O(1)。这一点相较于快排更为优越,快排在最坏情况下的空间复杂度可能会达到 O(n)(因为递归深度过深)。
堆排序的优缺点
优点:
- 时间复杂度稳定:不管输入数组的状态如何,堆排序的时间复杂度总是 O(n log n)。
- 空间复杂度低:堆排序是原地排序,空间复杂度为 O(1),比快排更节省空间。
缺点:
- 不稳定排序:堆排序是不稳定排序,相同元素的相对顺序可能会被改变。
- 不如快排快:尽管堆排序的时间复杂度和快排相同,但是堆排序的常数系数较大,实际运行速度往往比不上快排。
END
堆排序是一种比较实用的排序算法,特别适用于对稳定性要求高、递归深度限制较大、以及空间资源有限的场景。尽管它的实际表现可能不如快排,但它在一些特定情况下仍然是非常有价值的工具。
如果你是算法爱好者,推荐大家动手写一写堆排序,深入理解算法的原理!如果你有什么不懂的地方,欢迎在评论区留言哦,我会积极回复的!今天的分享就到这里啦,我们下次再见!
我是小米,一个喜欢分享技术的29岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号“软件求生”,获取更多技术干货!















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









