






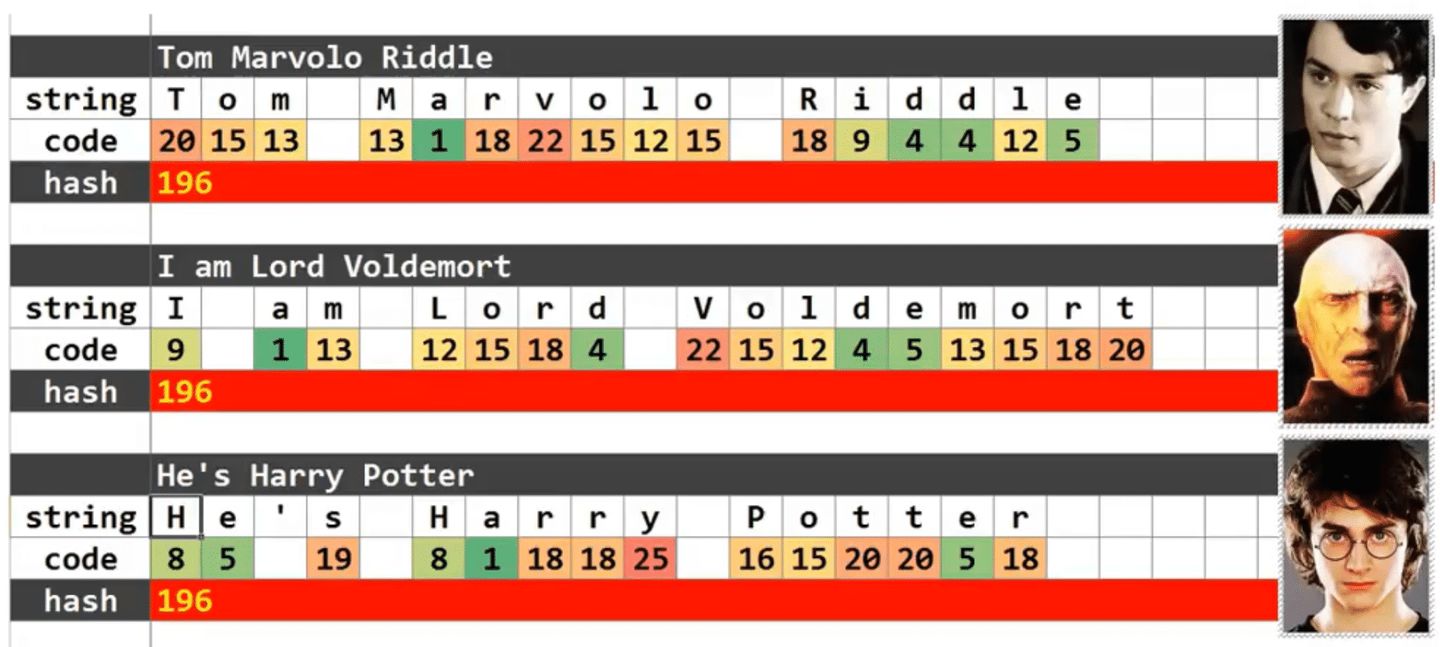
源于生活,抽象生活。
生活中的散列表
散列表讲的就是索引和内容的对应关系,当然这个索引可以是简单的0 1 2 3... 这种数字排序,也可以是排序好的关键字和内容之间的对应关系。
这就样想,例子即多了去了。

字典、电话簿、学号、工号,这不都是散列表吗?
计算机中的散列表
散列表
散列表是Hash翻译,它在计算机中还有一个音译的名字。哈希表。
其实在好多解释性语言中,早就存在了类似的数据结构,比如Python中的Dictionary。
d = {key1 : value1, key2 : value2 }我们可以理解,把这种用法引入到C++中,就是散列表的实现。
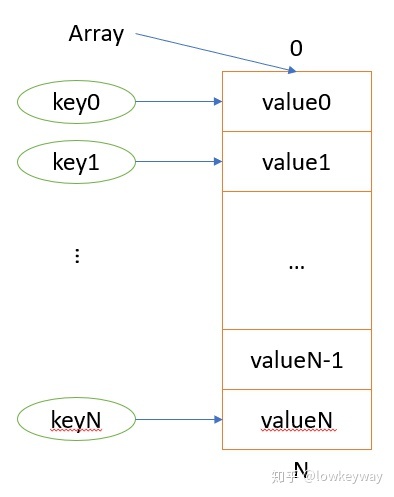
完美。下面我们来解决这个历史性难题。
散列函数
遇到的第一个问题就是,数组是一种次序排列的空间接口,只识别头地址和下标(偏移量),我们需要想个办法把key值转换后才能这个数组大小范围内(<N)的下标值。
这个转换的过程,就是散列函数的实现过程。
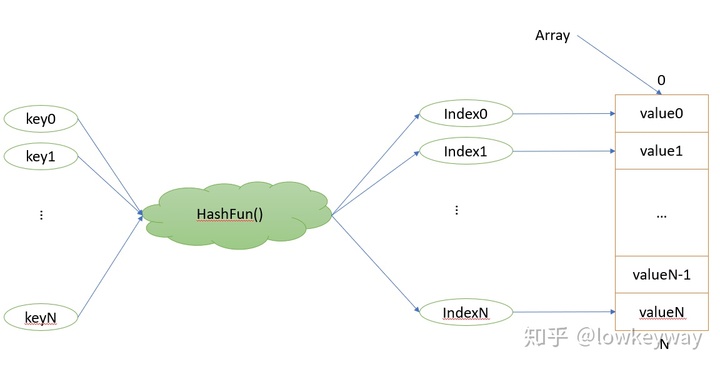
构造散列函数的思路就是要把字符串(可以认为是一个大数)转换成数组大小范围内的数的过程。那么很容易就想到了用求余(%)的方法,一般来说说,我们采用MAD的办法

为什么会是这个公式呢?这就要引入key转index的一些要求:
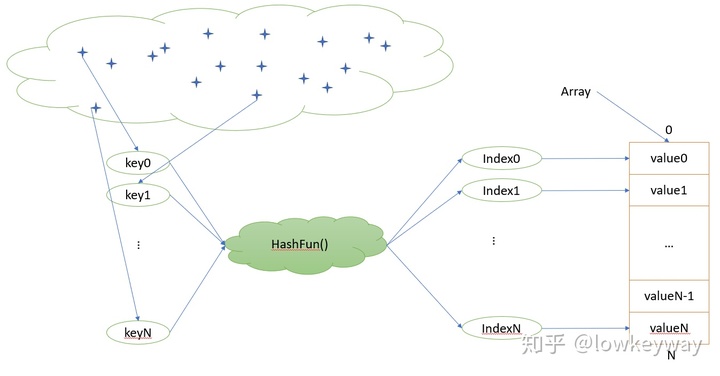
如果要把跨越较大范围的key映射到有限的index中,满足如下条件的哈希函数是被优先考虑的:
- 确定性:即有key一定要有对应的index与之对应,不能越界。
- 快速性:key对index的转换,以及对index的寻址应该尽可能的快。
- 满射性:尽可能的让index对应的value填满数组
- 均匀性:如果没有办法保证重复映射,value应该尽可能的均匀分布在array中。
这样对照看来,公式中求模可以保证确定性;线性运算保证快速性;系数a和b的取值尽量做到满射和偏移;N取值为素数包可以尽可能保证均匀性。
关于N要取值为素数(质数)的原因是输入k肯可能是按照一定规律递增的,比如间隔s。那么s应该尽量与N有尽可能少的最小公约数,这样可以避免求余的时候回按照最小公约数的步长填值。
哈希冲突
按照我们上面的求余公式,在key到index(散列地址)的对应关系中难以避免的是不同的key回对应到同一个index中。解决这个问题的方法就是解决冲突的过程。
一般来说,解决冲突有链表发和开放存址发。
链表法很容易理解,就是如果不同的K映射成一个index的时候,只要用链表在后面传承一串就可以了。
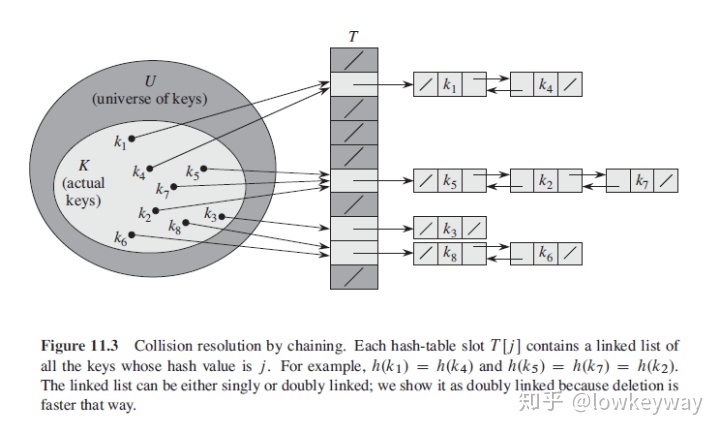
开放寻址法的方法有非常多,简单的理解就是如果第二个K值对应的index已经被占用了,那么就按照一定的规则向后查找没有被占用的index即可。
了解了这么多概念,一块写个代码实现它把。
需要注意的是:
1. 获取比输入大的最小质数只要判断输入的平方根即可。
2. 单向链表中,如果不用递归,插入和删除需要原地址或者指针的指针。
hashTable.h
#ifndef __HASH_TABLE_H__
#define __HASH_TABLE_H__
#include <iostream>
#include <string>
#include <vector>
#include <cmath>
using namespace std;
#define ull unsigned long long
#define uint unsigned int
#define STRING_TO_HASHNUM 131
#define HASH_MODULO 101
#define P_A 3
#define P_B 7
typedef struct node
{
string key;
string value;
struct node* pNext;
}Node;
inline ull stringHashKey(string s)
{
ull sum = 0;
for (int i = 0; i < s.size(); i++)
{
sum = sum * STRING_TO_HASHNUM + (ull)s[i];
}
return sum;
}
inline void __geValue(Node* pN, string &_value)
{
if (NULL == pN)
{
return;
}
_value += pN->value;
if (NULL == pN->pNext)
{
return;
}
_value = _value + ", ";
__geValue(pN->pNext, _value);
return;
}
inline uint findMinPrime(int _key)
{
uint temp;
uint indexMax;
temp = (uint)_key;
bool isPrime = true;
while (true)
{
isPrime = true;
indexMax = (uint)sqrt(temp);
for (uint i = 2; i <= indexMax; i++)
{
if (0 == temp % i)
{
isPrime = false;
temp++;
break;
}
}
if (true == isPrime)
{
return temp;
}
}
}
class hashTable
{
public:
hashTable(int size = HASH_MODULO);
~hashTable() {};
bool add(string _key, string _value);
bool add(Node* pN);
Node* get(string _key, string &_value);
bool del(string _key);
bool del(string _key, string _value);
private:
uint tableCap;
vector<Node*> hashList;
uint hashFun(ull stringKey);
};
#endif
hashTable.cpp
#include "hashTable.h"
hashTable::hashTable(int size)
{
if (size <= 0)
{
cout << "Please input correct number!" << endl;
return;
}
tableCap = findMinPrime(size);
hashList.resize(tableCap);
for (uint i = 0; i < tableCap; i++)
{
hashList[i] = NULL;
}
}
bool hashTable::add(string _key, string _value)
{
Node* pN = new Node;
pN->key = _key;
pN->value = _value;
pN->pNext = NULL;
add(pN);
return true;
}
bool hashTable::add(Node* pN)
{
ull hashKey = stringHashKey(pN->key);
uint _key = hashFun(hashKey);
pN->pNext = hashList[_key];
hashList[_key] = pN;
return true;
}
uint hashTable::hashFun(ull stringKey)
{
//return (uint)(stringKey % HASH_MODULO);
return (uint)((P_A * stringKey + P_B) % tableCap);
}
Node* hashTable::get(string _key, string &_value)
{
ull hashKey = stringHashKey(_key);
uint _hashKey = hashFun(hashKey);
_value.clear();
if (NULL == hashList[_hashKey])
{
cout << "There is no this key!" << endl;
return NULL;
}
__geValue(hashList[_hashKey], _value);
return hashList[_hashKey];
}
bool hashTable::del(string _key)
{
Node *pTemp;
ull hashKey = stringHashKey(_key);
uint _hashKey = hashFun(hashKey);
if (NULL == hashList[_hashKey])
{
cout << "There is no this key!" << endl;
return false;
}
do
{
pTemp = hashList[_hashKey];
hashList[_hashKey] = hashList[_hashKey]->pNext;
pTemp->pNext = NULL;
delete pTemp;
pTemp = NULL;
} while (NULL != hashList[_hashKey]);
return true;
}
bool hashTable::del(string _key, string _value)
{
Node *pDel;
Node **ppTemp;
ull hashKey = stringHashKey(_key);
uint _hashKey = hashFun(hashKey);
if (NULL == hashList[_hashKey])
{
cout << "There is no this key!" << endl;
return false;
}
pDel = hashList[_hashKey];
ppTemp = &hashList[_hashKey];
do
{
if (NULL == pDel)
{
cout << "Cannot find this value" << endl;
return false;
}
if (pDel->value == _value)
{
*ppTemp = pDel->pNext;
pDel->pNext = NULL;
delete pDel;
pDel = NULL;
cout << "Delete Success!" << endl;
return true;
}
pDel = pDel->pNext;
ppTemp = &((*ppTemp)->pNext);
} while (true);
}
demo.cpp
#include "hashTable.h"
int main()
{
string score;
hashTable h(200);
h.add("louis", "100");
h.add("Willis", "99");
h.add("John", "98");
h.add("John", "97");
h.get("John", score);
cout << score << endl;
h.del("John", "99");
h.get("John", score);
cout << score << endl;
system("pause");
return true;
}















 1777
1777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









