






该工作既可以做经典的instance, semantic, panoptic segmentation,又可以分割出从未见过的物体类别,还可以基于检测框分割出从未见过的物体并给出正确的类别。基于box prompts分割一切
https://github.com/IDEA-Research/OpenSeeD
论文链接:https://arxiv.org/pdf/2303.08131.pdf
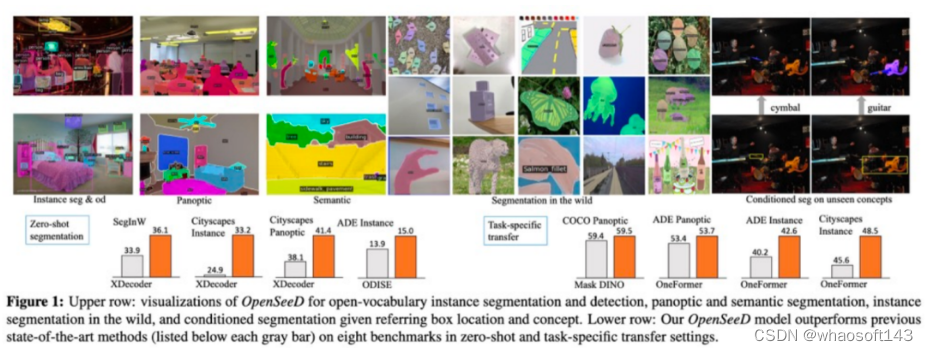
图中是我们模型的输出效果,我们既可以做经典的instance, semantic, panoptic segmentation,又可以分割出从未见过的物体类别,还可以基于检测框分割出从未见过的物体并给出正确的类别,这种基于box prompts分割一切的能力我们是第一个做到的,早于SAM。
OpenSeeD是一个简单而有效的开放词表图像分割的框架,也可以理解为MaskDINO扩展到开放词表的版本。除此以外,为了扩展语义的丰富程度,我们引入O365(365类)检测数据和COCO分割(133类)一起训练(不同于MaskDINO使用O365预训练)。为了能使两个任务和词表兼容,我们解决了data gap以及task gap。最终,我们的方法在多个开放词表任务上取得了与当前sota方法x-decoder comparable甚至更好的效果,相比x-decoder用了4M人工标注的image captioning数据,我们用了0.57M的detection数据,另外我们发现,即使只用5k的o365数据也可以在开放词表任务上达到类似的效果。这说明我们的模型需要的是丰富的视觉概念(类别数),而不一定是很大的数据量。
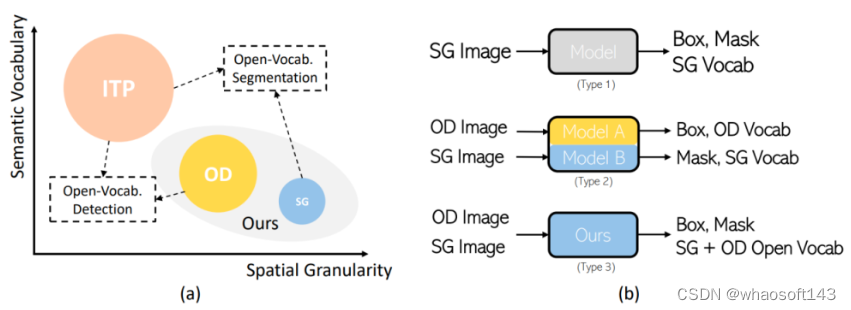
如图2所示,过去已经有不少工作结合大量的图像文本对实现开词表检测或者分割,而我们应该是第一个把物体检测数据和全景分割数据结合在一起联合训练的工作,并且证明是可行有效的,算是填补了这块空白。
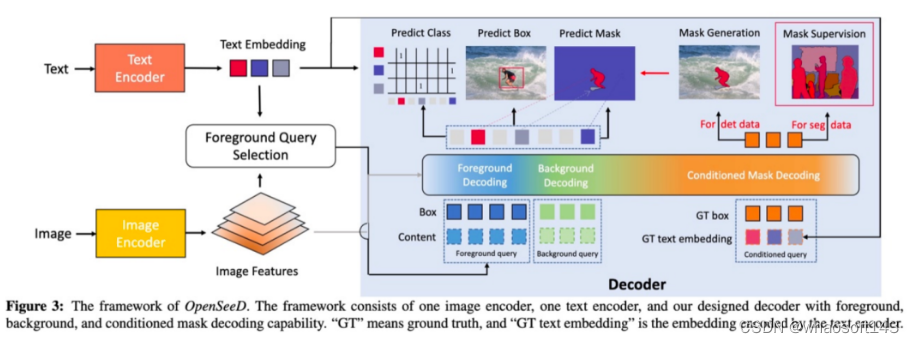
下图是模型的overview,左半部分做的是generic segmentation,为了解决task gap(O365只有前景,而COCO有前景和背景),我们把前景和背景的预测解耦开,右半部分是conditional prediction部分,可以通过GT box预测mask,为了解决data gap,我们可以通过右半部分为O365打标签。
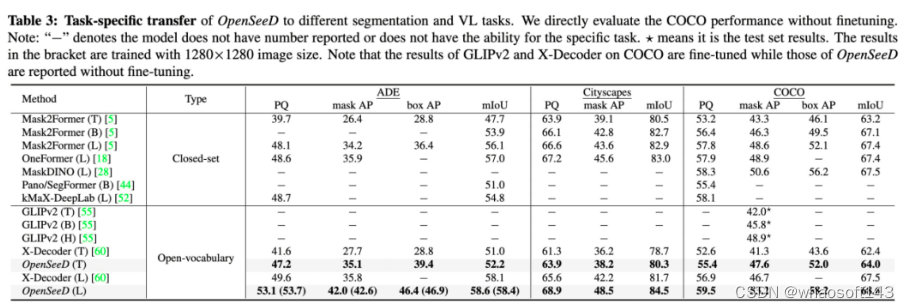
以下是我们的实验结果,我们用较少的检测数据(相比于其他sota方法),在多个zeroshot分割任务上达到或超越了sota方法X-Decoder,GLIPv2等,尤其在SeginW任务(大量没见过的类别)上取得了远超X-Decoder的效果。
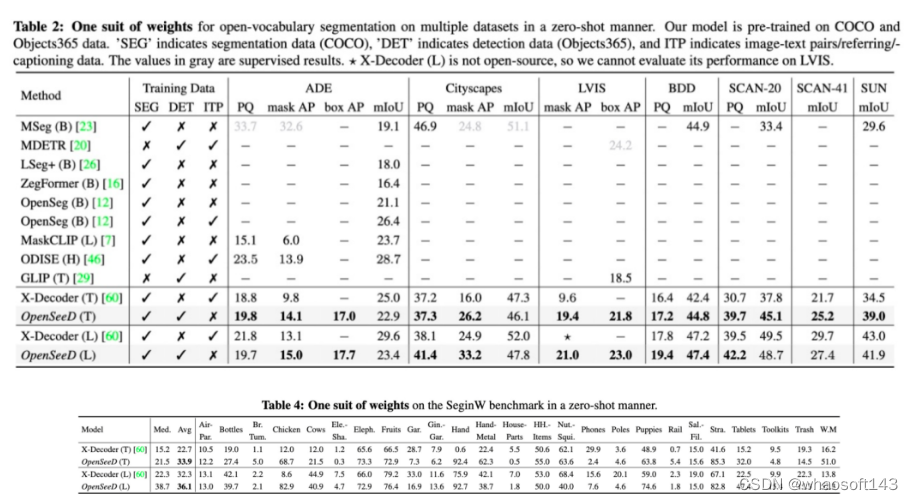
除此以外,当我们fintune到其他数据集时,都取得了远超baseline的性能,在COCO和ADE20K的全景分割以及ADE20K和Cityscapes的实例分割上取得了SOTA的表现。
总结一下,OpenSeeD作为一个强大的open-set segmentation方法,可以分割出大量从未见过的物体,在各项open-seth和close-set指标上都取得了SOTA。而且通过引入O365检测任务来提升open-set语义能力,训练代价相对其他open-set方法较小。















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









