







项目背景
大家好,我是J哥。
新房数据,对于房地产置业者来说是买房的重要参考依据,对于房地产开发商来说,也是分析竞争对手项目的绝佳途径,对于房地产代理来说,是踩盘前的重要准备。
今天J哥以「惠民之家」为例,手把手教你利用Python将惠州市新房数据批量抓取下来,共采集到近千个楼盘,包含楼盘名称、销售价格、主力户型、开盘时间、容积率、绿化率等「41个字段」。数据预览如下:
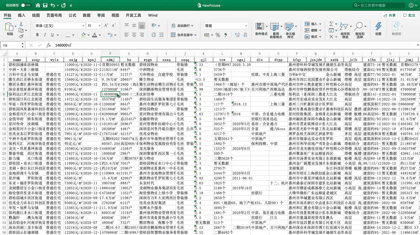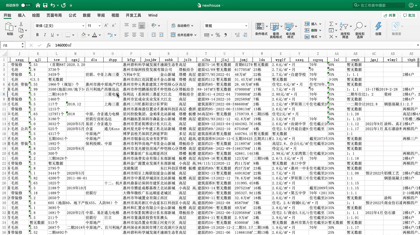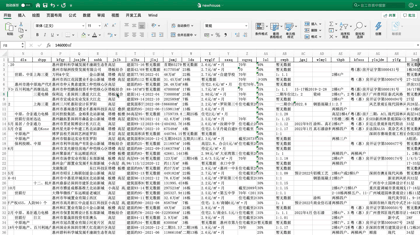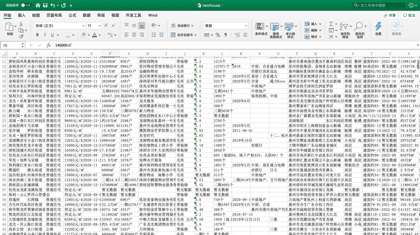
后台回复「新房」二字,可领取本文代码。
项目目标
惠民之家首页网址:
http://www.fz0752.com/
新房列表网址:
http://www.fz0752.com/project/list.shtml
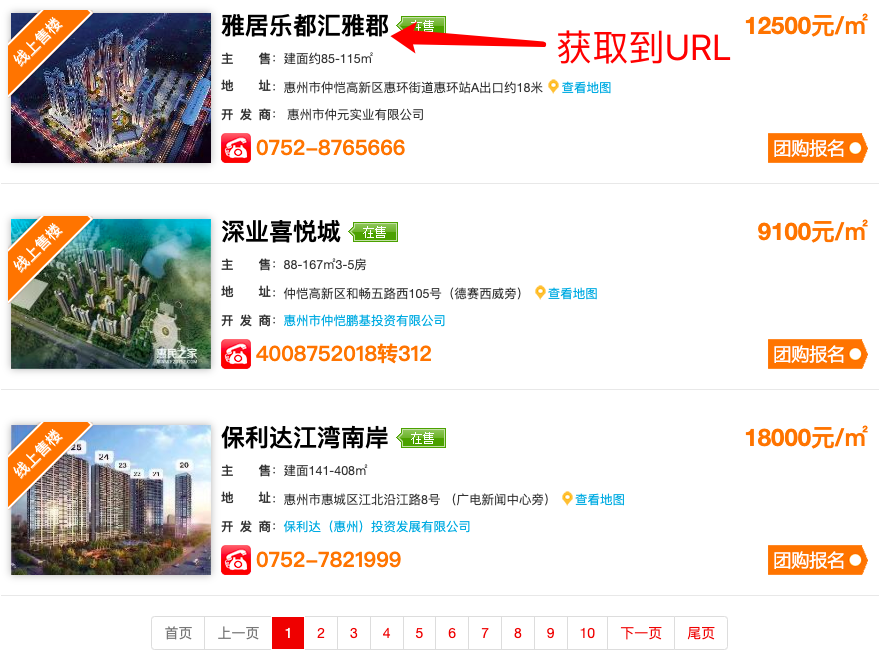
选择一个新房并点击「详情信息」即可找到目标字段:

项目准备
软件:Pycharm
第三方库:requests,fake_useragent,lxml
网站地址:http://www.fz0752.com/
网页分析
列表页分析
打开新房列表网页,点击「下一页」后,网址变成:
http://www.fz0752.com/project/list.shtml?state=&key=&qy=&area=&danjia=&func=&fea=&type=&kp=&mj=&sort=&pageNO=2
很显然,这是静态网页,翻页参数为「pageNO」,区域参数为「qy」,其余参数也很好理解,点击对应筛选项即可发现网页链接变化。
 咱们可以通过遍历区域和页码,将新房列表的房源URL提取下来,再遍历这些URL,抓取到每个房源的详情信息。
咱们可以通过遍历区域和页码,将新房列表的房源URL提取下来,再遍历这些URL,抓取到每个房源的详情信息。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1214
1214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









