







大量数据中具有"相似"特征的数据点或样本划分为一个类别。聚类分析提供了样本集在非监督模式下的类别划分。聚类的基本思想是"物以类聚、人以群分",将大量数据集中相似的数据样本区分出来,并发现不同类的特征。
聚类模型可以建立在无类标记的数据上,是一种非监督的学习算法。尽管全球每日新增数据量以PB或EB级别增长,但是大部分数据属于无标注甚至非结构化。所以相对于监督学习,不需要标注的无监督学习蕴含了巨大的潜力与价值。聚类根据数据自身的距离或相似度将他们划分为若干组,划分原则是组内样本最小化而组间距离最大化。
- 常用于数据探索或挖掘前期
- 没有先验经验做探索性分析
- 样本量较大时做预处理
- 解决问题
- 数据集可以分几类
- 每个类别有多少样本量
- 不同类别中各个变量的强弱关系如何
- 不同类型的典型特征是什么
- 应用场景
- 群类别间的差异性特征分析
- 群类别内的关键特征提取
- 图像压缩、分割、图像理解
- 异常检测
- 数据离散化
- 缺点
- 无法提供明确的行动指向
- 数据异常对结果有影响
本文将从算法原理、优化目标、sklearn聚类算法、算法优缺点、算法优化、算法重要参数、衡量指标以及案例等方面详细介绍KMeans算法。
KMeans
K 均值(KMeans)是聚类中最常用的方法之一,基于点与点之间的距离的相似度来计算最佳类别归属。
KMeans算法通过试着将样本分离到
被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的,当聚类完毕之后,我们就要分别去研究每个簇中的样本都有什么样的性质,从而根据业务需求制定不同的商业或者科技策略。常用于客户分群、用户画像、精确营销、基于聚类的推荐系统。
算法原理
- 从
个样本数据中随机选取
个质心作为初始的聚类中心。质心记为
- 定义优化目标
- 开始循环,计算每个样本点到那个质心到距离,样本离哪个近就将该样本分配到哪个质心,得到 K 个簇
- 对于每个簇,计算所有被分到该簇的样本点的平均距离作为新的质心
- 直到
收敛,即所有簇不再发生变化。
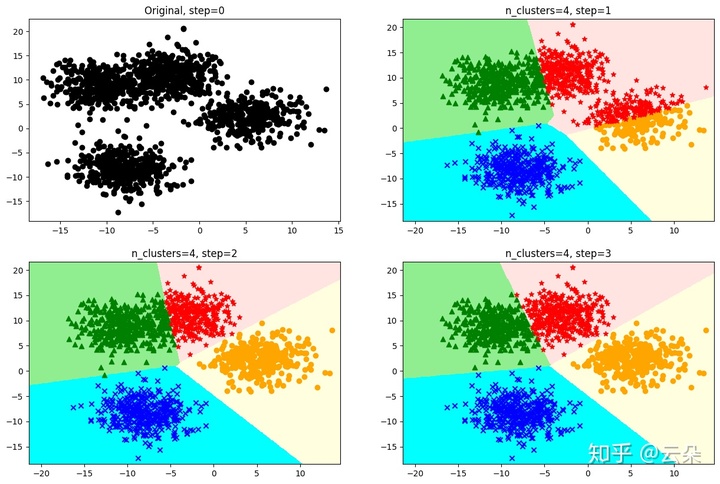
KMeans迭代示意图
优化目标
KMeans 在进行类别划分过程及最终结果,始终追求"簇内差异小,簇间差异大",其中差异由样本点到其所在簇的质心的距离衡量。在 KNN 算法学习中,我们学习到多种常见的距离 ---- 欧几里得距离、曼哈段距离、余弦距离。
在 sklearn 中的KMeans使用欧几里得距离:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









