







摘要
在很多机器学习场景中,需要我们对数据进行预处理,sklean提供的pipeline接口方便我们将数据预处理与模型训练等工作进行整合,方便对训练集、验证集、测试集做相同的转换操作,极大的提高了工作效率。但是在不同场景下往往预处理的方法会出现多样性,然而sklearn所提供的预处理接口(Transformers)数量有限,有的时候往往需要我们自己编写函数对数据进行预处理。为了让我们自定义的数据预处理函数能够放入sklearn的pipeline中,我们想到了自定义Transformer的方法,本文也将围绕自定义Transformer的具体步骤进行展开。
目录
创建项目
使用编译器:pycharm
创建一个空项目,记得选择好相应的python解释器
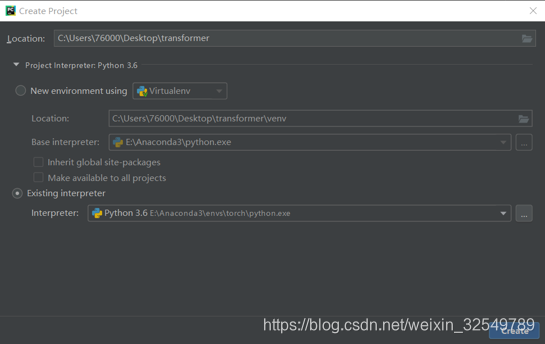
点击create后创建新项目完成,在空项目文件夹下创建一个python package和一个setup.py文件,python package创建之后会自带一个叫__init__.py的空文件,我们之后会对它进行编写,创建好这些之后整个项目目录会变成下面这样:
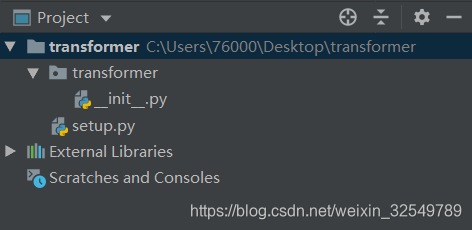
请注意,我们所创建的这个python package的名字将会作为我们调用这个第三方包时的名字,在这个例子中将是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









