






直达原文:【可观测系列】传统企业可观测建设之路
数字化转型与可观测的关系
在数字化转型的浪潮中,我们面临着将“线下业务线上化”及实现“业务快速创新迭代”的迫切需求,这也进而要求支撑业务的应用系统更加敏捷、可扩展性更高。
因而,分布式、云原生是企业应用架构的发展方向。
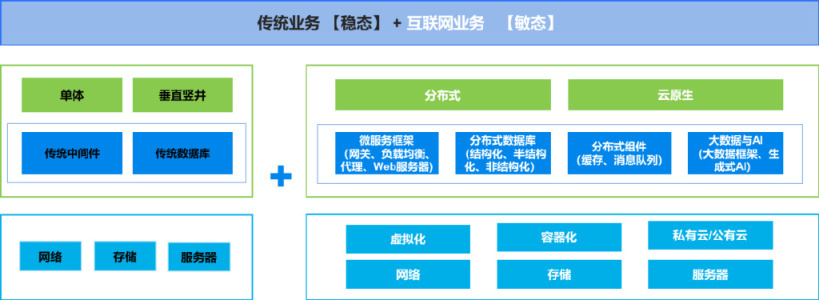
分布式架构下,各种 IT 对象如消息队列、缓存、分布式数据库等层出不穷,并且组件间的调用关系错综复杂。

此时,传统 IT 监控只能提供资源层面的状态警告,无法提供分布式应用故障诊断所需的更多有效信息,因此,一个面向应用面向故障的全栈可观测方案越来越成为企业 IT 运维的迫切需求。
30 年过去,终迎来第二代监控——可观测
IT 监控作为 IT 运维之眼,是 IT 运维第一个建设的工具,追溯 IT 监控工具历史,已有 30 年之久。传统 IT 监控的发展,主要是在监控对象以及在监控能力(如指标、Log、Trace)的不断扩展,发展至今,已形成众多从 IaaS 到 SaaS 层的监控工具。据 Gartner 市场调研数据显示,超过 70%的中大型企业拥有 10 个以上的 IT 监控工具,以满足各种 IT 监控需求。

监控工具越来越多,但每个监控工具却只能揭示业务和应用的部分问题,且工具能力重合、工具数据互为烟囱,这导致用户难以联动整合所有监控,面向整个业务和应用进行全面的故障诊断。
传统工具发展的这些瓶颈和问题在可观测体系中得到了完美解决。
传统监控与可观测的主要区别如下:
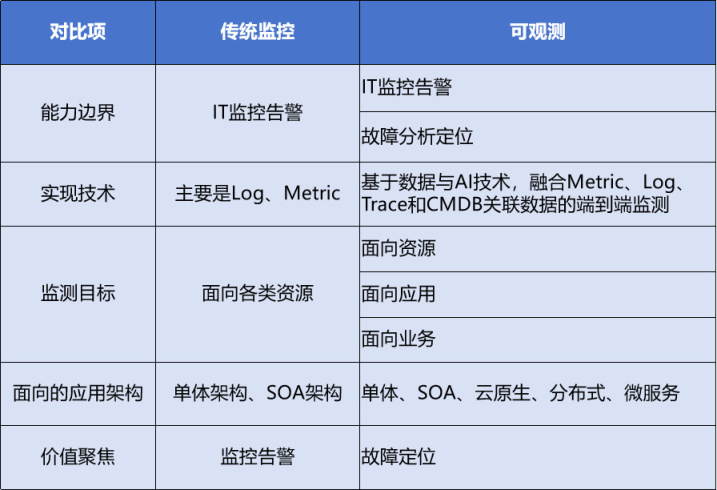
简单来讲,监控主要聚焦在感知,可观测还聚焦于问题出现之后诊断分析和隐患发现。
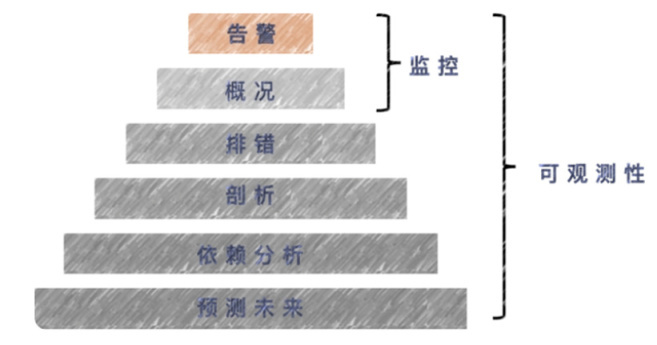
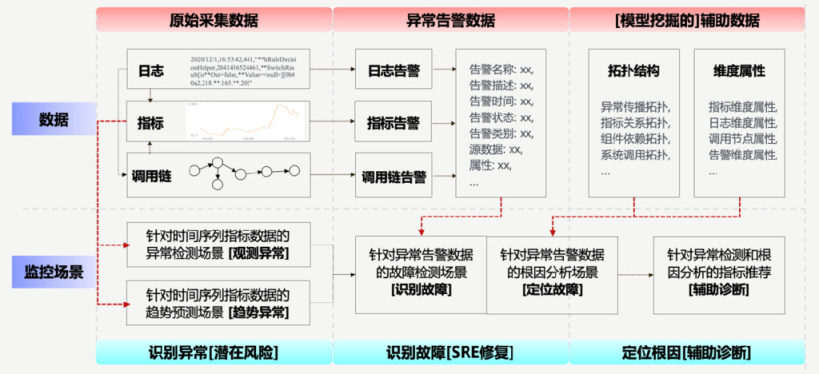
基于四大支柱数据设计可观测体系
要做到面向应用、面向故障的可观测,我们需要为整个应用系统的生产运行拓扑进行建模,并将应用所有相关组件的各种观测数据进行有机聚合,因此,可观测体系设计的核心理念在于对 Metirc、Log、Trace、Topology 这四大支柱数据进行统一采集、统一治理和有机聚合。
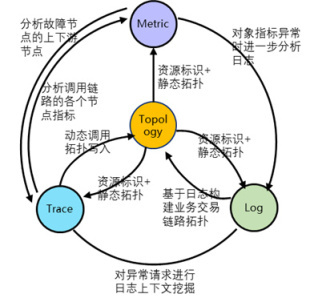
这几个数据之间的关系如下:
- Topology 描述了一个应用包含多少个微服务、一个微服务包含多少个实例,实例运行在哪些 Pod 上,Pod 又运行在哪些虚拟机上, 虚拟机连接了哪些存储,服务或实例间存在什么样的调用关系等资源配置和关联关系数据。
- Topology 提供了观测的元数据(资源及拓扑),作为 Metric、Log、Trace 的资源主体。但在某些场景下,Trace 中发现的应用调用关系、Log 中采集和发现的一些业务交易拓扑关系,也可以成为 Topology 中的数据来源。
- 当一个 IT 对象的指标(Metric)存在告警时,我们需要基于 Trace 向上分析故障影响,向下追溯根因,也需要获取该对象的 Log 信息进行进一步的故障诊断。
- 当一个微服务的调用(Trace)延迟或失败时,我们可以基于 Metric 和 Log 进一步分析相关对象的关键健康指标和日志上下文信息。
基于上述理念,可抽象可观测的数据模型如下:
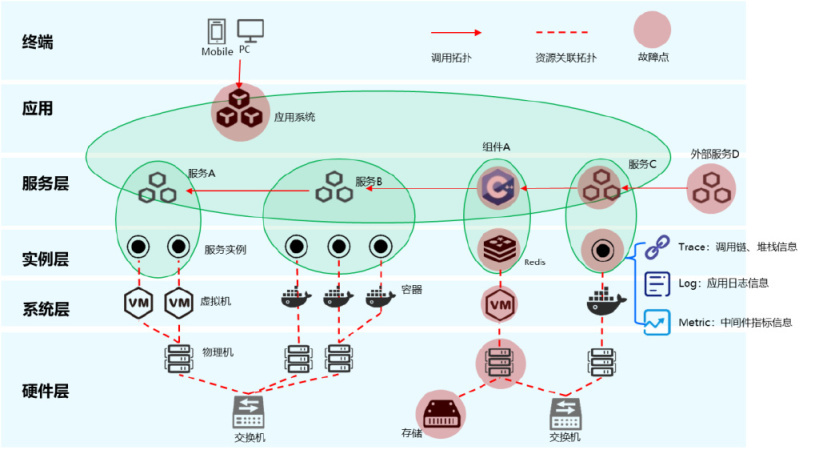
- 面向应用系统部署情况构建从上到下(应用、微服务、实例、系统与虚拟化、硬件)的纵向分层对象模型关系;
- 基于 APM 调用关系构建横向的服务间调用和实例调用关系;
- 每一个实例的状态信息,可通过各种采集手段获取相关的 Metrix、Log、Trace 监测数据。
- 当系统出现故障时,通过横纵向的关系和 Metric/Log/Trace 的告警聚合信息,实现自动化告警收敛和故障诊断,从而给出相关的根因推荐。
基于此设计,我们可以自动构建应用横纵向全景拓扑,感知应用故障点。
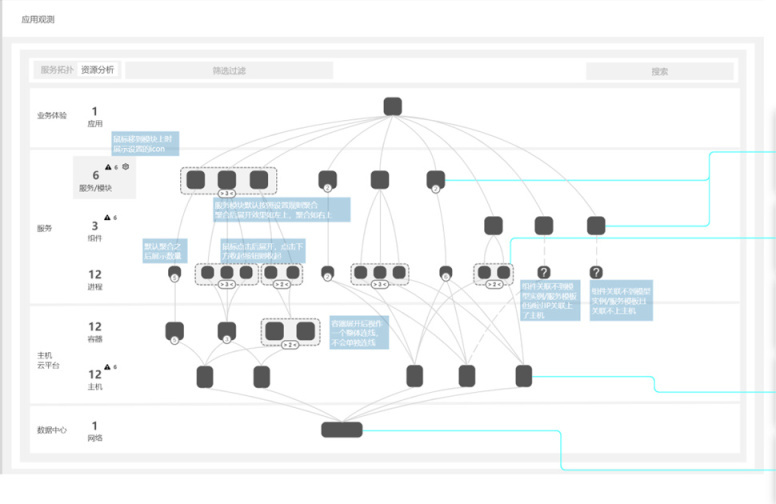
根据故障点实现上游故障影响分析和下游故障根因溯源。
可观测成熟度模型
可观测既包含了传统监控的技术,又包含了基于数据和 AI 的统一数据治理与智能根因分析以实现端到端的监控与分析的能力。可观测体系的建设不是一蹴而就的,也不是将传统监控体系推倒重来,而是一个基于科学建设路径和方法逐步演进的过程。
可观测成熟度模型如下:
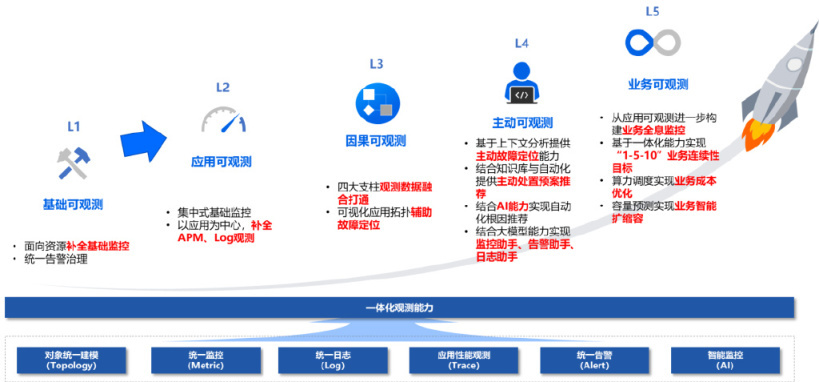
L1【基础可观测】
补全基础监控,以满足分布式时代各类云、容器、分布式组件等的监控要求;
对各个监控工具中的告警事件进行统一告警汇聚、告警丰富、告警收敛、告警分派、告警分析、告警处置、告警复盘的全生命周期管理。
L2【应用可观测】
基于数据平台思路建设集中监控,接入企业当前已有各类监控工具,实现统一对象管理、指标管理、策略及视图管理等;
补全 APM 能力实现应用性能监控。
L3【因果可观测】
将四大支柱数据融合打通,通过各种自动构建的排障拓扑提供故障辅助定位能力。
L4【主动可观测】
在 L3 之上,基于上下文分析能力和 AI 能力,实现故障的主动式定位和根因推荐;
基于知识库和大模型能力,实现故障处置预案推荐,并提供监控、告警、日志小助手与运维人员进行实现紧密协同。
L5【业务可观测】
基于行业特征,实现对关键业务交易活动和交易链路的监控,将业务监控与应用可观测无缝集成以进一步保障业务稳定运行;
联动 ITSM、自动化等实现端到端的故障预防、发现、定位、处置与复盘改进的“1-5-10”业务连续性管理能力;
基于算力调度能力实现业务智能扩缩容和成本优化。
可观测平台功能设计
可参考下图进行可观测平台的功能设计:
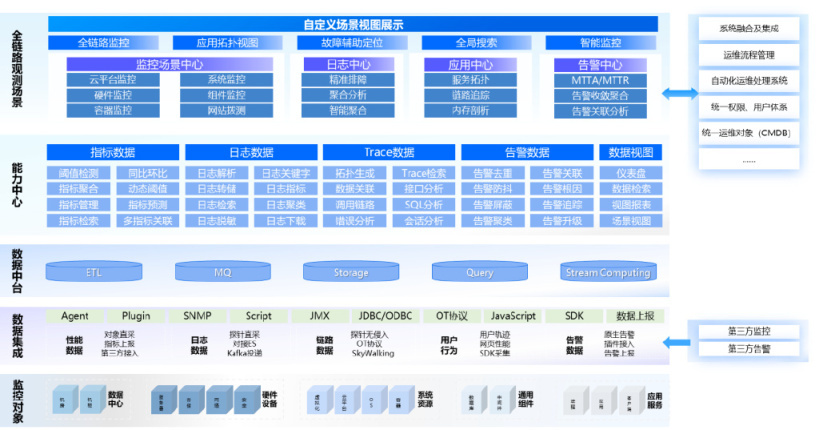
- 以数据中台思路建设底座,以满足各类数据的采集清洗和各类外部监控工具数据的接入;
- 建设统一观测能力中心,包含面向 Metric、Log、Trace 的各项观测基本能力;
- 构建统一观测场景,包含基础集中监控、日志和 APM、统一告警场景,也包含观测融合相关全链路监控、故障辅助定位等场景。
可观测平台建设过程
建设重点 1——观测元数据建模治理【Topology】
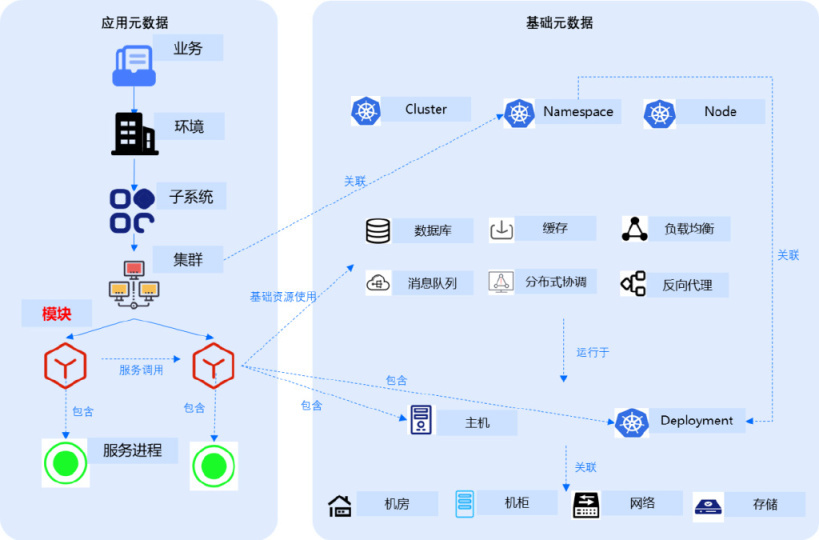
- 面向应用建立观测元数据模型,包括描述应用的生产和灾备环境,描述应用的可用区或分布式地域集群,描述组成应用的子系统或模块(微服务)。
- 模块(微服务)包含一组实例,实例则是运行于虚拟机或容器上。微服务之间存在调用关系,微服务也与消息队列、数据库等基础组件存在访问关联关系。
- 观测元数据建议使用企业统一的 CMDB 进行存储。一方面可以充分利用 CMDB 中自动采集 &手动维护的各类 IT 资源对象数据,另一方面基于统一对象配置数据与 ITSM、自动化等运维工具联动实现故障定位(如从 ITSM 获取该对象近期的变更审批信息,从自动化平台获取该对象近期的操作记录以作为辅助故障定位)和处置自动化。
建设重点 2——指标体系建模治理【Metric】
IT 资源对象种类多,IT 存量监控工具数量大,因此面向硬件、系统、云、OS、虚拟化、中间件、数据库等基础资源的集中监控能力是可观测体系建设的基础。
集中监控的关键前提是统一指标治理,包括对每种资源对象的指标定义、指标梳理和指标消费等。
集中监控的建设过程是扩展种类采集插件覆盖各种 IT 对象,或提供便利的数据接入能力接入其他监控工具的数据。
建设重点 3——统一日志管理【Log】
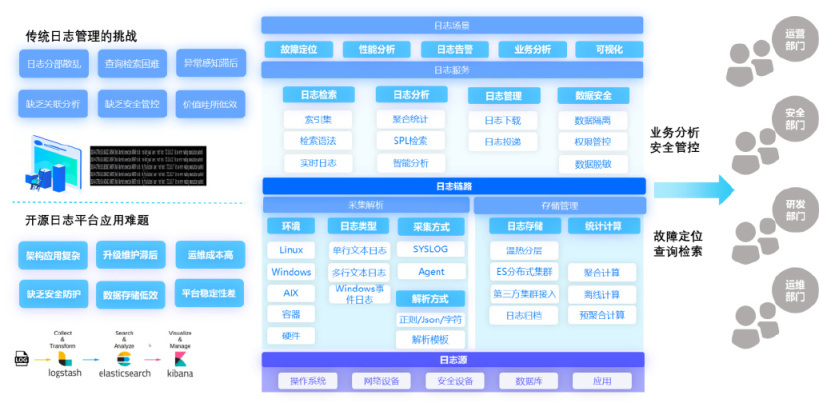
可观测平台需要提供统一的、丰富的日志采集、清洗、检索与展示能力以覆盖各类设备日志管理需求。
建设重点 4——APM 实现故障追踪【Trace】
APM 是分布式系统的关键监控能力,通过 APM 可以对应用的四个黄金指标进行监控,可以对服务件、服务与组件间的调用状态进行监控,还可以实现对服务接口级、方法级的故障发现与诊断分析。
建设重点 5——实现告警的全生命周期治理【Alert】
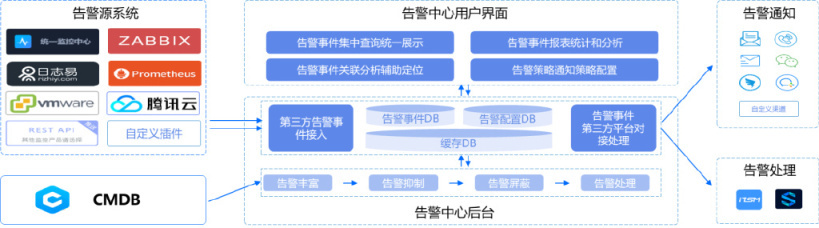
- 告警接入:通过可扩展的告警源插件完成各类告警事件的接入;
- 告警丰富:联动 CMDB 完成告警丰富,包括运维人员、告警对象配置信息等;
- 告警抑制:基于多种灵活的告警收敛方法实现告警收敛,避免告警风暴;
- 告警分派:将告警事件自动分派或手动分派给相应的运维人员进行处置;
- 告警分析:基于告警对象的 Log、Trace、Metric,基于告警对象的上下游关联对象的状态信息,基于告警对象的近期变更或运维信息进行展示分析;
- 告警处置:联动自动化平台进行告警的处置。
基于统一告警中心的建设,实现一条告警的全生命周期流转闭环管控。
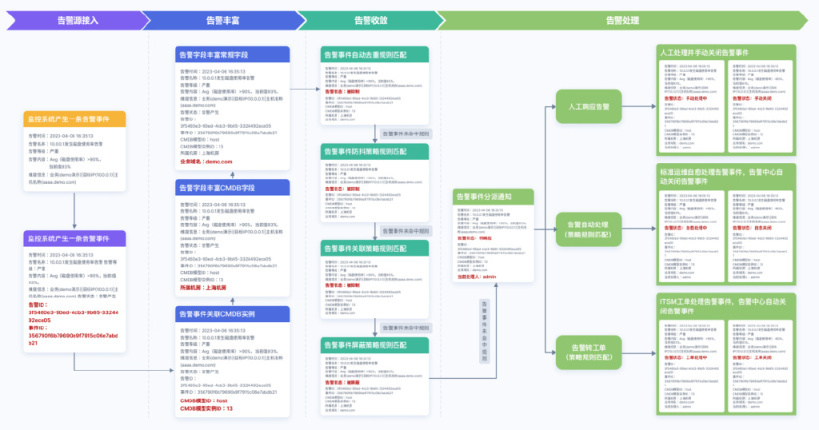
建设重点 6——基于 AI 与 LLM 的智能可观测【AI】
通过集成 AI 能力实现动态阈值、告警聚合收敛、时序预测、日志聚类分析、多维下钻与根因定位等智能可观测能力。
基于 LLM 可以构建可观测智能小助手,如展示告警详情:
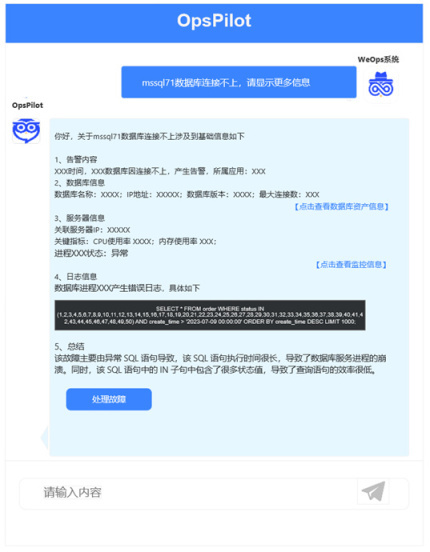
挖掘告警相关故障信息:
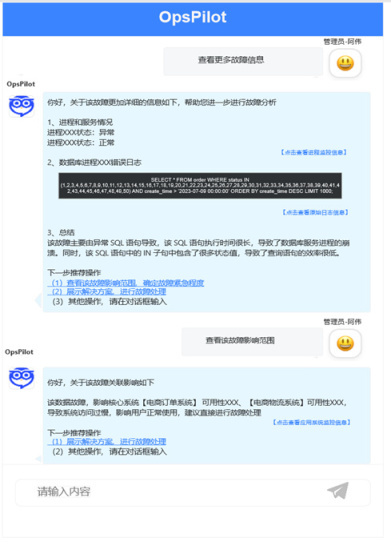
获取故障推荐和交互式故障自动化处理:
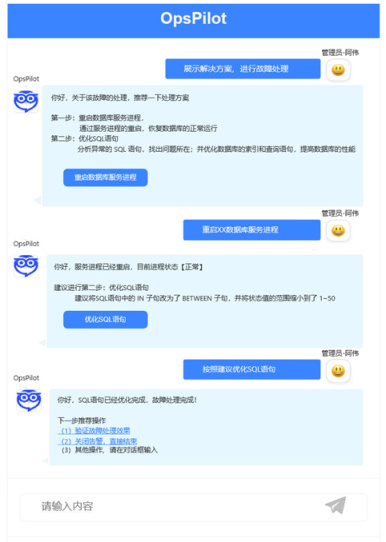
建设重点 7——基于应用可观测向上构建业务可观测【Business】
在数字化时代,业务的稳定生产运行都会反馈到应用系统的各项运行指标上,运维的最核心目标也是保障业务的稳定生产运行。
当我们实现了应用可观测后,基于应用可观测能力去构建面向上层各类业务活动、业务场景的可观测,就会水到渠成且事半功倍。
业务观测领域中,最重要的是对各类业务交易场景以及各个应用系统的业务黄金指标进行监控,例如银行,有各种支付、转账、查额、还款等场景,这些交易的交易链路如何自动构建,如何监测每一笔交易的效率和质量,如何在交易异常的情况下迅速找到问题点并进行解决,是业务可观测的重点建设内容。
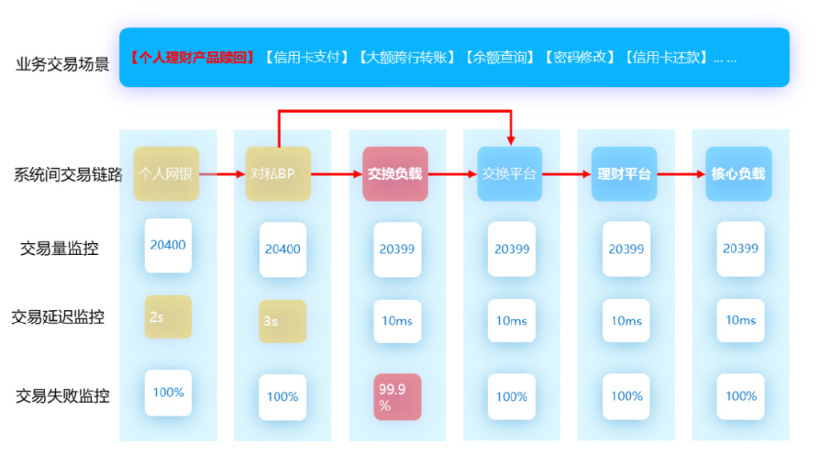
业界基于业务监控的有三大技术:APM 的交易链路自动构建与黄金指标监测、应用标准化日志的交易链路自动构建与黄金指标监测、网络流量镜像分析的交易链路自动构建与黄金指标监测。
三者各有优劣点,如基于 APM 的技术面临着全量采集给应用带来的性能压力、基于日志则需要应用进行标准化日志输出的改造、基于网络流量则面临着网络丢包、数据量巨大和云原生 SDN 架构下的流量采集技术壁垒等问题。企业需要根据自己的实际情况选择合适的技术。
最后,业务可观测的技术还需要能够联动应用可观测,从而实现从业务指标到具体问题资源对象联动起来的根因定位。
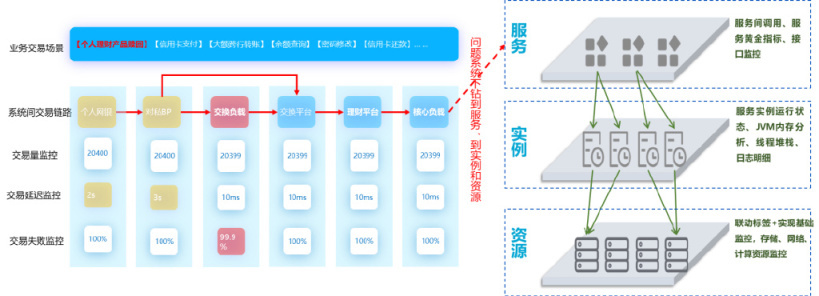
可观测平台三年建设计划建议
前面提到,可观测不是将现有监控推倒重来,而是基于现状进行规划建设。对于大部分传统企业而言,可参考以下三年建设计划:
第一年:感知 &治理
构建硬件、云、容器、系统、组件监控等统一基础监控感知能力;
构建统一日志监控感知能力;
构建统一应用调用链监控感知能力;
构建告警的统一闭环治理能力。
第二年:定位 &业务
面向应用构建故障的快速定位能力
融合 APM(Trace)、基础监控(Metric)、日志(Log)、CMDB 拓扑(Topology)进行辅助故障定位;
构建各类可视化应用拓扑提供故障上游影响分析能力,提供故障下游溯源分析能力。
面向业务提供监控与故障定位能力
实现业务指标监控与业务交易链路观测;
结合应用可观测能力实现业务问题的故障定位。
第三年:智能 &扩展
结合 AI 和大模型进一步升华可观测能力
基于 AI 实现根因定位、动态阈值、告警聚类、离群检测、容量预测、智能扩缩容、算力调度能力;
基于大模型与知识库的处置预案推荐,基于自动化的故障自愈。
融合网络监控工具和用户监控工具实现全栈监控
融合 NPM、eBPF 技术将网络流量级诊断能力丰富到故障定位能力中;
融合 RUM(真实用户监控)实现端到端的全栈可观测能力。
直达原文:【可观测系列】传统企业可观测建设之路















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









