







这篇文章主要介绍我们即将发表在ISSTA 2020 上的工作,欢迎大家引用,这里是我们的preprint版本。
Muhui Jiang, Yajin Zhou, Xiapu Luo, Ruoyu Wang, Yang Liu, and Kui Ren.2020. An Empirical Study on ARM Disassembly Tools. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA ’20)
Bibtex格式如下:
@inproceedings{issta20:arm_study,
author = { Muhui, Jiang and Yajin, Zhou and Xiapu, Luo and Ruoyu, Wang and Yang, Liu and Kui, Ren },
title = {An Empirical Study on ARM Disassembly Tools},
booktitle = {Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis},
year = {2020}
} 研究动机
嵌入式设备的安全问题一直以来是学术界研究的热点。无论是我们日常生活中经常使用到的手机,路由器,还是无人机,单反相机这些富帅们的标配,其实都属于嵌入式设备。因为低功耗,高性能,低成本的重点优点,ARM架构的微处理器一直备受嵌入式设备厂商的喜爱。
那么,问题来了。因为涉及到不同的商业机密,很多时候我们是拿不到嵌入式设备的源代码的。研究者们想要研究这些设备的安全性的时候,只能研究经过编译过后的binary。而所谓binary,其实是给处理器看的(毕竟处理器的世界都是0和1,我们的世界还有666),咱们人类乍一看肯定看不懂。因此,我们自然需要一些工具的帮助,去把这些binary转换成我们读得懂的汇编语言,才能继续研究。那么,问题又来了,我该用哪种工具呢?不同工具有什么优缺点呢?IDA Pro那么贵 (支持正版!),到底值不值啊,是不是最好的呢。带着种种问题,我们做了这么一个工作。
[懒人必备] 毕竟有的老铁不喜欢看细节,这里总结一下我们的工作。我们针对1896个不同的binaries,测了8种不同的支持ARM的反汇编器,探究他们在对于指令集(Instruction Boundary)和函数(Function Boundary)识别上的正确性。其中有5个是开源的工具,3个是商业工具。然后我们发现了一些有趣的结论,比如不同类型的指令模式(ARM架构下有ARM模式的指令和Thumb模式的指令)对反汇编器影响很大。因为ARM架构中没有专门用来做函数跳转的指令,这会大大影响反汇编器识别函数的准确性,除此之外,ARM的binary中 inline的data很常见,这也对反汇编带来了不小的难度。 接下来,我们详细的介绍我们的工作。
研究的反汇编器
我想有过逆向工程研究经历的同学们,一定知道大名鼎鼎的IDA Pro。奈何IDA Pro贵啊,我用学生优惠还花了快800刀才只能买一个操作系统的,换个系统又要收费了。事实上,业界除了IDA Pro外,还有很多优秀的反汇编器,有一些还是开源的。 通过阅读一些paper和搜索,我们最终确定下来8个比较流行的反汇编器(这里有一些工具,不仅仅包含反汇编的功能,还有一些advanced的功能)。以下是具体这些tool的信息。冒号后仅为我个人的简单介绍。
- angr: 2016年安全顶级会议oakland发表的一篇sok中介绍的tool,社区一直很活跃,开发者也一直在积极维护中。由python编写,简单易用。很多顶会文章中的工具都基于此开发
- BAP: 安全大佬David Brumley的大作,用Ocaml的函数式编程语言写的。目前项目也在积极维护中。奈何个人觉得Ocaml还是比较难学的,所以我自己其实用的不多
- Objdump: 这个可能是大家最熟悉的工具之一吧,基本上linux发行版都会自带,简单易用。不过准确性嘛,其实并不太好
- Ghidra: 美国军方背景,NSA掏钱做的,基于java写的,好处当然就是跨平台。而且开源!实际用起来性能也还不错。不过刚刚release不久,正确性还有待提高
- Radare2: 用C开发的,跟一般的反汇编器不太一样,是交互式的。命令非常多,不过用户体验还不错,正确性也还是有待提高的。也是开源的!
- Binary Ninja:一群hacker在hack时候觉得找不到nb的工具,于是自己写了一个(真 hacker style)
- Hopper: 支持MacOS跟linux,商业化工具中最便宜的,而且准确率也还不错。
- IDA Pro: 这个不解释。最贵的就是它,其中decompiler还是不同架构分开卖,更是贵到天际。
总的来说,Hopper应该算是最便宜的商业工具,只要100刀左右,而且很适合Mac OS的用户。最贵的无疑是IDA Pro。其中Objdump因为只支持解析指令集,并不支持识别函数,因此不会测试它这个功能。
研究的数据集
我们总共用了1896个不同的binaries。由于ARM中有不同的指令模式,并且编译时候采用不同的优化方法或者是不同的ARM版本都会产生不同的binary
我们希望我们的数据足够有代表性。因此我们还额外的做了一个survey,探究真实世界中的ARM binaries到底是什么样的。我们把基于ARM架构的binary分成了三类。他们分别是嵌入式系统中的binary,linux内核以及用户态程序。对于每一种特定的类型,我们选择了不同的较为代表性的程序,并且真实的编译了他们。最后我们编了超过20w个不同的object,搜集了他们的编译指令。经过对他们编译指令的研究,我们发现ARM的两种不同模式(ARM和Thumb)在不同类型的程序中都会出现。而对于编译时候的优化选项,O2和Os是最为常见的。
基于以上survey的结果。我们最终有了我们用来测试的1896个不同的binaries。他们分别来自安卓开源项目(AOSP),非常流行的嵌入式设备Linux发行版(Openwrt)。还有我们对SPEC CPU 2006,用不同类型的编译指令编译而来的binaries。与此同时,我们还考虑到混淆技术在商业软件中的使用,基于SPEC CPU 2006,用不同的编译指令编译了248个由OLLVM混淆后的程序。详细的统计数据,可以看我们的文章。
如何判断一个编译器的好坏
因为所有用来测试的binaries都是我们手动编译的。通过编译过程中的一些debug information。我们可以自动的从这些binaries中抽取出来我们的ground truth,也就是标准答案。然后我们会把这些debug information去掉 (这并不会影响binary的指令集和函数),我们称呼这些没有了debug information的binaries为stripped binaries(可以理解为release 版本)。我们会把这些stripped binaries丢给反汇编器,我们为每一种反汇编器都写了不同的脚本,去抽取出来反汇编器的解析结果。
再得到了反汇编器的结果后,我们将这个结果跟我们的ground truth做比较。通过统计领域中经常使用到的 recall和precision 来衡量这个反汇编器到底是否够优秀。
实验的结果
我们最终发现IDA Pro和Hopper其实是综合结果最好的两个反汇编器。其中针对指令集的正确性上,IDA Pro有着最高的precision,而Hopper有最高的recall。而对于函数的识别上,IDA Pro是最好的,比Hopper略高一点。下面这个表格是整个的结果。我们还发现BAP对于很多个binaries会timeout(我们设置timeout 为 2 cpu hours)。而angr对于很多的binaries会抛出exception或者直接crash了(segfault)。其中有87.5%都是thumb 模式的binaries。

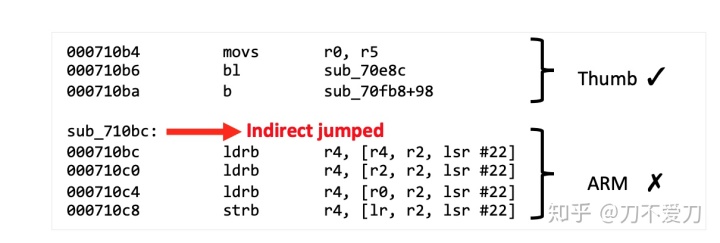
这里给大家看几个代表性的例子。比如如下这张图中,Hopper错误的将从0x710bc开始的代码块用错误的ARM模式反汇编。原因是0x710bc这个地方的代码没有被直接跳转。所以Hopper用默认的ARM模式去做反汇编了。
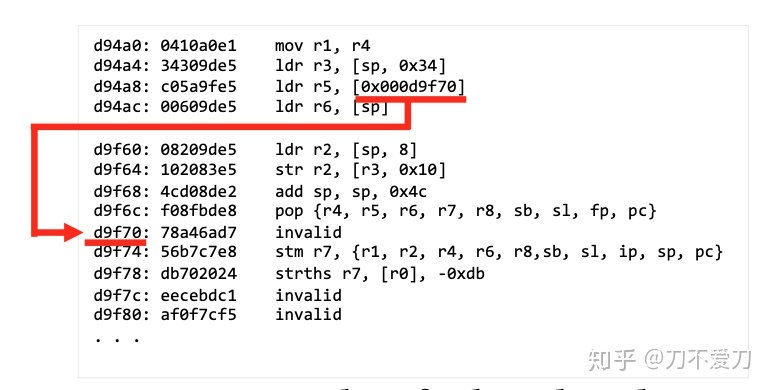
还有一个Radare2的例子如下,比如在0xd94a8这里,会从0xd9f70这里通过ldr指令读取数据。事实上,这代表0xd9f70这里就是data段。但是radare2,并没有解析出来这是data,还是继续尝试反汇编。
如果想要看更多详细的例子,可以仔细阅读参考我们的文章。我们向工具的开发者们提交了我们的测试用例和错误的地方。像Binary Ninja,Hopper还有angr都确认了我们的发现,并且在新的版本中fix了出错的地方。Radare2 效率较慢,虽然assign了bug label,但是一直没有fix。而Ghidra给了possible的solution,BAP表示他们对Thumb支持的确很差,会考虑以后增加支持。
我们还进一步探究了不同的因素对这些反汇编器的影响。这里直接上结论,详细的数据和图表可以看我们的文章。
- 我们发现反汇编器普遍对Thumb模式的binary支持不够好。像BAP会timeout,angr会crash。
- 我们发现对于不同的优化方法(O2 和 Os),其实产生的binary对于不同的反汇编器影响并不大。主要还是Os只是在O2的基础上多了一些关于padding和alignment的操作。不会有太大影响。
- 我们用了不同的编译器(GCC 和 Clang)去编译binary。结果发现BAP和Radare2对其比较敏感。主要还是跟这两个tool的算法有关。
- 不同的ARM版本其实对反汇编器在函数识别上影响比较大。这里要多说一下,在ARM里,通常用BL指令来call一个函数。但是在Thumb 模式中,由于指令的长度只有16bit,所以B指令的跳转范围有限。如果跳转的目标较远,Thumb模式会用BL来表示条件的跳转,这是因为BL指令的跳转范围比B指令更长。而在armv6之后,由于引入了Thumb2 指令,允许32bit的指令存在。所以这时候B指令的跳转幅度也足够使用了。但是很多反汇编器(比如Binary Ninja)会粗暴的把BL的跳转目标都当作是一个函数的开始。这显然是不对的。所以当我们用不同的ARM版本(armv5 和 armv7),函数的识别正确性是有区别的
- 不同的系统类型,结果也不一样。这里系统类型主要是指,不同场景下的binary。比如我们发现Android的binary中大量使用了Thumb模式,而Openwrt几乎都用的ARM模式。
- 我们还发现了混淆的影响。我们发现混淆的binary因为引入了很多fake的跳转。而对于thumb模式被混淆的binary,他们很多都是用的BL指令来进行这种跳转。这大大降低了反汇编器识别函数的正确性(引入了很多的false positive)
- 不同类型的反汇编器有不同的使用方法。比如Radare2有好几种解析的命令。Angr有多个参数。我们也探究了他们的影响,对使用者在使用时提出了建议。
- 最后我们还探究了不同类型的反汇编器在性能上的开销。我们发现Binary Ninja会很消耗CPU和Memory 资源。但是像BAP对CPU的利用率很低。
总结
总的来说,我们认为对于现在的针对ARM的反汇编器,还是有很多提升的空间的。不管是对不同模式的指令的识别,指令用途的识别,还是对内嵌数据段的识别等,都值得去探索。
感谢阅读,欢迎大家讨论。














 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









