






聚焦NeRF的整体训练以及其中最为关键的volume render过程。

图1|NeRF的render过程流程
首先从创造NeRF网络的create_nerf程序段开始介绍:这一部分是NeRF代码的承接部分,既将上一节NeRF介绍的载入数据,网络等参数接入进来,又接着将这些定义好的参数处理完送入到之后的主循环中:
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)
input_ch_views = 0
embeddirs_fn = None
if args.use_viewdirs:
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
# 想要=5生效,首先需要use_viewdirs=False and N_importance>0
output_ch = 5 if args.N_importance > 0 else 4
skips = [4]
# 粗网络
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars = list(model.parameters())
model_fine = None
if args.N_importance > 0:
# 精细网络
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
# 模型参数
grad_vars += list(model_fine.parameters())
# netchunk 是网络中处理的点的batch_size
network_query_fn = lambda inputs, viewdirs, network_fn: run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
# Create optimizer
# 优化器
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
start = 0
basedir = args.basedir
expname = args.expname
##########################
# Load checkpoints
if args.ft_path is not None and args.ft_path != 'None':
ckpts = [args.ft_path]
else:
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if
'tar' in f]
print('Found ckpts', ckpts)
# load参数
if len(ckpts) > 0 and not args.no_reload:
ckpt_path = ckpts[-1]
print('Reloading from', ckpt_path)
ckpt = torch.load(ckpt_path)
start = ckpt['global_step']
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
# Load model
model.load_state_dict(ckpt['network_fn_state_dict'])
if model_fine is not None:
model_fine.load_state_dict(ckpt['network_fine_state_dict'])
##########################
render_kwargs_train = {
'network_query_fn': network_query_fn,
'perturb': args.perturb,
'N_importance': args.N_importance,
# 精细网络
'network_fine': model_fine,
'N_samples': args.N_samples,
# 粗网络
'network_fn': model,
'use_viewdirs': args.use_viewdirs,
'white_bkgd': args.white_bkgd,
'raw_noise_std': args.raw_noise_std,
}
print(model_fine)
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
render_kwargs_test = {k: render_kwargs_train[k] for k in render_kwargs_train}
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0.
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
继而是将图片中像素点的二维坐标转化成三维坐标,完成相机坐标系到世界坐标系的转换。
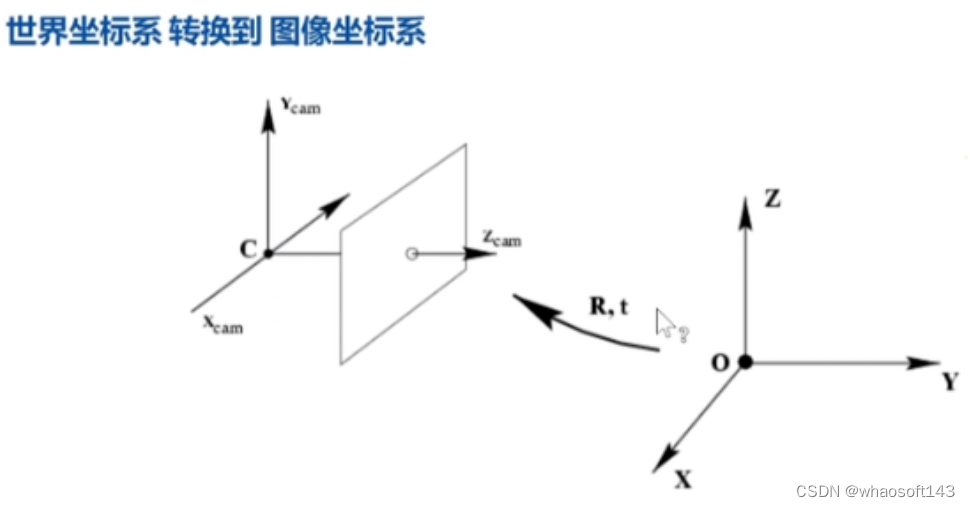
图2|坐标转化
def get_rays(H, W, K, c2w):
"""
K:相机内参矩阵
c2w: 相机到世界坐标系的转换
"""
# j
# [0,......]
# [1,......]
# [W-1,....]
# i
# [0,..,H-1]
# [0,..,H-1]
# [0,..,H-1]
i, j = torch.meshgrid(torch.linspace(0, W - 1, W), torch.linspace(0, H - 1, H), indexing='ij')
i = i.t()
j = j.t()
# [400,400,3]
dirs = torch.stack([(i - K[0][2]) / K[0][0], -(j - K[1][2]) / K[1][1], -torch.ones_like(i)], -1)
# Rotate ray directions from camera frame to the world frame
# dirs [400,400,3] -> [400,400,1,3]
# dot product, equals to: [c2w.dot(dir) for dir in dirs]
# rays_d [400,400,3]
rays_d = torch.sum(dirs[..., np.newaxis, :] * c2w[:3, :3], -1)
# Translate camera frame's origin to the world frame. It is the origin of all rays.
# 前三行,最后一列,定义了相机的平移,因此可以得到射线的原点o
rays_o = c2w[:3, -1].expand(rays_d.shape)
return rays_o, rays_d
def get_rays_np(H, W, K, c2w):
# 与上面的方法相似,这个是使用的numpy,上面是使用的torch
i, j = np.meshgrid(np.arange(W, dtype=np.float32), np.arange(H, dtype=np.float32), indexing='xy')
dirs = np.stack([(i - K[0][2]) / K[0][0], -(j - K[1][2]) / K[1][1], -np.ones_like(i)], -1)
# Rotate ray directions from camera frame to the world frame
rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3, :3],
-1) # dot product, equals to: [c2w.dot(dir) for dir in dirs]
# Translate camera frame's origin to the world frame. It is the origin of all rays.
rays_o = np.broadcast_to(c2w[:3, -1], np.shape(rays_d))
return rays_o, rays_d- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
得到点的世界坐标后,就得进行render操作。
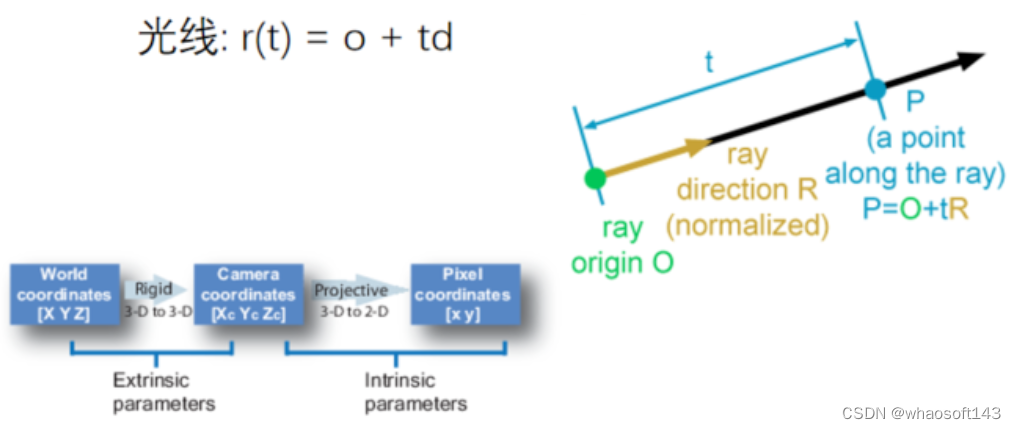
图3|光线采样
def render(H, W, K,
chunk=1024 * 32, rays=None, c2w=None, ndc=True,
near=0., far=1.,
use_viewdirs=False, c2w_staticcam=None,
**kwargs):
"""Render rays
Args:
H: int. Height of image in pixels.
W: int. Width of image in pixels.
K: 相机内参 focal
chunk: int. Maximum number of rays to process simultaneously. Used to
control maximum memory usage. Does not affect final results.
rays: array of shape [2, batch_size, 3]. Ray origin and direction for
each example in batch.
c2w: array of shape [3, 4]. Camera-to-world transformation matrix.
ndc: bool. If True, represent ray origin, direction in NDC coordinates.
near: float or array of shape [batch_size]. Nearest distance for a ray.
far: float or array of shape [batch_size]. Farthest distance for a ray.
use_viewdirs: bool. If True, use viewing direction of a point in space in model.
c2w_staticcam: array of shape [3, 4]. If not None, use this transformation matrix for
camera while using other c2w argument for viewing directions.
Returns:
rgb_map: [batch_size, 3]. Predicted RGB values for rays.
disp_map: [batch_size]. Disparity map. Inverse of depth.
acc_map: [batch_size]. Accumulated opacity (alpha) along a ray.
extras: dict with everything returned by render_rays().
"""
if c2w is not None:
# special case to render full image
rays_o, rays_d = get_rays(H, W, K, c2w)
else:
# use provided ray batch
# 光线的起始位置, 方向
rays_o, rays_d = rays
if use_viewdirs:
# provide ray directions as input
viewdirs = rays_d
# 静态相机 相机坐标到世界坐标的转换
if c2w_staticcam is not None:
# special case to visualize effect of viewdirs
rays_o, rays_d = get_rays(H, W, K, c2w_staticcam)
# 单位向量 [bs,3]
viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True)
viewdirs = torch.reshape(viewdirs, [-1, 3]).float()
sh = rays_d.shape # [..., 3]
if ndc:
# for forward facing scenes
rays_o, rays_d = ndc_rays(H, W, K[0][0], 1., rays_o, rays_d)
# Create ray batch
rays_o = torch.reshape(rays_o, [-1, 3]).float()
rays_d = torch.reshape(rays_d, [-1, 3]).float()
# [bs,1],[bs,1]
near, far = near * torch.ones_like(rays_d[..., :1]), far * torch.ones_like(rays_d[..., :1])
# 8=3+3+1+1
rays = torch.cat([rays_o, rays_d, near, far], -1)
if use_viewdirs:
# 加了direction的三个坐标
# 3 3 1 1 3
rays = torch.cat([rays, viewdirs], -1) # [bs,11]
# Render and reshape
# rgb_map,disp_map,acc_map,raw,rbg0,disp0,acc0,z_std
all_ret = batchify_rays(rays, chunk, **kwargs)
for k in all_ret:
# 对所有的返回值进行reshape
k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:])
all_ret[k] = torch.reshape(all_ret[k], k_sh)
# 讲精细网络的输出单独拿了出来
k_extract = ['rgb_map', 'disp_map', 'acc_map']
ret_list = [all_ret[k] for k in k_extract]
ret_dict = {k: all_ret[k] for k in all_ret if k not in k_extract}
# 前三是list,后5还是在map中
return ret_list + [ret_dict]- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
NeRF使用batchify_rays()函数以及里面调用的render_rays()函数来批量地处理射线上的点。NeRF采用微积分的方式处理射线上的点并进行累加积分得到估计的颜色值:
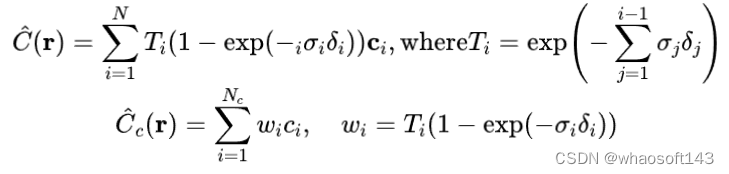
def batchify_rays(rays_flat, chunk=1024 * 32, **kwargs):
"""
Render rays in smaller minibatches to avoid OOM.
rays_flat: [N_rand,11]
"""
all_ret = {}
for i in range(0, rays_flat.shape[0], chunk):
ret = render_rays(rays_flat[i:i + chunk], **kwargs)
for k in ret:
if k not in all_ret:
all_ret[k] = []
all_ret[k].append(ret[k])
# 将分批处理的结果拼接在一起
all_ret = {k: torch.cat(all_ret[k], 0) for k in all_ret}
return all_ret
# 这里面会经过神经网络
def render_rays(ray_batch,
network_fn,
network_query_fn,
N_samples,
retraw=False,
lindisp=False,
perturb=0.,
N_importance=0,
network_fine=None,
white_bkgd=False,
raw_noise_std=0.,
verbose=False,
pytest=False):
"""Volumetric rendering.
Args:
ray_batch: array of shape [batch_size, ...]. All information necessary
for sampling along a ray, including: ray origin, ray direction, min
dist, max dist, and unit-magnitude viewing direction. 单位大小查看方向
粗网络
network_fn: function. Model for predicting RGB and density at each point
in space.
network_query_fn: function used for passing queries to network_fn.
N_samples: int. Number of different times to sample along each ray.
raw 是指神经网络的输出
retraw: bool. If True, include model's raw, unprocessed predictions.
lindisp: bool. If True, sample linearly in inverse depth rather than in depth.
perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified random points in time.
精细网络中的光线上的采样频率
N_importance: int. Number of additional times to sample along each ray.
These samples are only passed to network_fine.
精细网络
network_fine: "fine" network with same spec as network_fn.
white_bkgd: bool. If True, assume a white background. 白色背景
raw_noise_std: ...
verbose: bool. If True, print more debugging info.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model.
disp_map: [num_rays]. Disparity map. 1 / depth.
acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model.
raw: [num_rays, num_samples, 4]. Raw predictions from model.
rgb0: See rgb_map. Output for coarse model.
disp0: See disp_map. Output for coarse model.
acc0: See acc_map. Output for coarse model.
z_std: [num_rays]. Standard deviation of distances along ray for each
sample.
"""
N_rays = ray_batch.shape[0] # N_rand
# 光线起始位置,光线的方向
rays_o, rays_d = ray_batch[:, 0:3], ray_batch[:, 3:6] # [N_rays, 3] each
# 视角的单位向量
viewdirs = ray_batch[:, -3:] if ray_batch.shape[-1] > 8 else None
bounds = torch.reshape(ray_batch[..., 6:8], [-1, 1, 2]) # [bs,1,2] near和far
near, far = bounds[..., 0], bounds[..., 1] # [-1,1]
# 采样点
t_vals = torch.linspace(0., 1., steps=N_samples)
if not lindisp:
z_vals = near * (1. - t_vals) + far * (t_vals) # 插值采样
else:
z_vals = 1. / (1. / near * (1. - t_vals) + 1. / far * (t_vals))
# [N_rand,64] -> [N_rand,64]
z_vals = z_vals.expand([N_rays, N_samples])
if perturb > 0.:
# get intervals between samples,64个采样点的中点
mids = .5 * (z_vals[..., 1:] + z_vals[..., :-1])
upper = torch.cat([mids, z_vals[..., -1:]], -1)
lower = torch.cat([z_vals[..., :1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
# [bs,64] 加上随机的噪声
z_vals = lower + (upper - lower) * t_rand
# 空间中的采样点
# [N_rand, 64, 3]
# 出发点+距离*方向
pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :, None] # [N_rays, N_samples, 3]
# 使用神经网络 viewdirs [N_rand,3], network_fn 指的是粗糙NeRF或者精细NeRF
# raw [bs,64,3]
raw = network_query_fn(pts, viewdirs, network_fn)
# rgb值,xx,权重的和,weights就是论文中的那个Ti和alpha的乘积
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd,
pytest=pytest)
# 精细网络部分
if N_importance > 0:
# _0 是第一个阶段 粗糙网络的结果
# 这三个留着放在dict中输出用
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
# 第二次计算mid,取中点位置
z_vals_mid = .5 * (z_vals[..., 1:] + z_vals[..., :-1])
z_samples = sample_pdf(z_vals_mid, weights[..., 1:-1], N_importance, det=(perturb == 0.), pytest=pytest)
z_samples = z_samples.detach()
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
# 给精细网络使用的点
# [N_rays, N_samples + N_importance, 3]
pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :, None]
run_fn = network_fn if network_fine is None else network_fine
# 使用神经网络
# create_nerf 中的 network_query_fn 那个lambda 函数
# viewdirs 与粗糙网络是相同的
raw = network_query_fn(pts, viewdirs, run_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd,
pytest=pytest)
ret = {'rgb_map': rgb_map, 'disp_map': disp_map, 'acc_map': acc_map}
if retraw:
# 如果是两个网络,那么这个raw就是最后精细网络的输出
ret['raw'] = raw
if N_importance > 0:
# 下面的0是粗糙网络的输出
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
# 检查是否有异常值
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return ret- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
- 159.
- 160.
- 161.
有了采样,坐标转换,体渲染,loss以及训练的介绍后,我们来看看主循环部分是如何调用上述所有函数的:
def train():
# 解析参数
from opts import config_parser
parser = config_parser()
args = parser.parse_args()
# --------------------------------------------------------------------------------------------------------
# Load data
# 在这个数据集会特殊些 LINEMOD
K = None
# 一共有四种类型的数据集
# 是configs目录中 只有llff和blender两种类型
# 原始的nerf仓库中有deepvoxels类型的数据
# LINEMOD 没见过
# llff Local Light Field Fusion
if args.dataset_type == 'llff':
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
recenter=True, bd_factor=.75,
spherify=args.spherify)
hwf = poses[0, :3, -1]
poses = poses[:, :3, :4]
print('Loaded llff', images.shape, render_poses.shape, hwf, args.datadir)
if not isinstance(i_test, list):
i_test = [i_test]
if args.llffhold > 0:
print('Auto LLFF holdout,', args.llffhold)
i_test = np.arange(images.shape[0])[::args.llffhold]
i_val = i_test
i_train = np.array([i for i in np.arange(int(images.shape[0])) if
(i not in i_test and i not in i_val)])
print('DEFINING BOUNDS')
if args.no_ndc:
near = np.ndarray.min(bds) * .9
far = np.ndarray.max(bds) * 1.
else:
near = 0.
far = 1.
print('NEAR FAR', near, far)
elif args.dataset_type == 'blender':
# images,所有的图片,train val test在一起,poses也一样
images, poses, render_poses, hwf, i_split = load_blender_data(args.datadir, args.half_res, args.testskip)
print('Loaded blender', images.shape, render_poses.shape, hwf, args.datadir)
i_train, i_val, i_test = i_split
near = 2.
far = 6.
if args.white_bkgd:
# todo 这个是什么操作,为什么白色背景要这样操作
images = images[..., :3] * images[..., -1:] + (1. - images[..., -1:])
else:
images = images[..., :3]
elif args.dataset_type == 'LINEMOD':
# 这个数据类型 原始的nerf中没有
images, poses, render_poses, hwf, K, i_split, near, far = load_LINEMOD_data(args.datadir, args.half_res,
args.testskip)
print(f'Loaded LINEMOD, images shape: {images.shape}, hwf: {hwf}, K: {K}')
print(f'[CHECK HERE] near: {near}, far: {far}.')
i_train, i_val, i_test = i_split
if args.white_bkgd:
images = images[..., :3] * images[..., -1:] + (1. - images[..., -1:])
else:
images = images[..., :3]
elif args.dataset_type == 'deepvoxels':
images, poses, render_poses, hwf, i_split = load_dv_data(scene=args.shape,
basedir=args.datadir,
testskip=args.testskip)
print('Loaded deepvoxels', images.shape, render_poses.shape, hwf, args.datadir)
i_train, i_val, i_test = i_split
hemi_R = np.mean(np.linalg.norm(poses[:, :3, -1], axis=-1))
near = hemi_R - 1.
far = hemi_R + 1.
else:
print('Unknown dataset type', args.dataset_type, 'exiting')
return
# Cast intrinsics to right types
H, W, focal = hwf
H, W = int(H), int(W)
hwf = [H, W, focal]
# K 相机内参 focal 是焦距,0.5w 0.5h 是中心点坐标
# 这个矩阵是相机坐标到图像坐标转换使用
if K is None:
K = np.array([
[focal, 0, 0.5 * W],
[0, focal, 0.5 * H],
[0, 0, 1]
])
# --------------------------------------------------------------------------------------------------------
# render the test set instead of render_poses path
# 使用测试集的pose,而不是用那个固定生成的render_poses
if args.render_test:
render_poses = np.array(poses[i_test])
# Move testing data to GPU
render_poses = torch.Tensor(render_poses).to(device)
# --------------------------------------------------------------------------------------------------------
# Create log dir and copy the config file
basedir = args.basedir
expname = args.expname
create_log_files(basedir, expname, args)
# --------------------------------------------------------------------------------------------------------
# Create nerf model
# 创建模型
render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer = create_nerf(args)
# 有可能从中间迭代恢复运行的
global_step = start
bds_dict = {
'near': near,
'far': far,
}
render_kwargs_train.update(bds_dict)
render_kwargs_test.update(bds_dict)
# --------------------------------------------------------------------------------------------------------
# Short circuit if only rendering out from trained model
# 这里会使用render_poses
if args.render_only:
# 仅进行渲染,不进行训练
print('RENDER ONLY')
run_render_only(args, images, i_test, basedir, expname, render_poses, hwf, K, render_kwargs_test, start)
return
# --------------------------------------------------------------------------------------------------------
# Prepare ray batch tensor if batching random rays
N_rand = args.N_rand
use_batching = not args.no_batching
if use_batching:
# For random ray batching
print('get rays') # (img_count,2,400,400,3) 2是 rays_o和rays_d
rays = np.stack([get_rays_np(H, W, K, p) for p in poses[:, :3, :4]], 0) # [N, ro+rd, H, W, 3]
print('done, concats') # rays和图像混在一起
rays_rgb = np.concatenate([rays, images[:, None]], 1) # [N, ro+rd+rgb, H, W, 3]
rays_rgb = np.transpose(rays_rgb, [0, 2, 3, 1, 4]) # [N, H, W, ro+rd+rgb, 3]
rays_rgb = np.stack([rays_rgb[i] for i in i_train], 0) # train images only, 仅使用训练文件夹下的数据
rays_rgb = np.reshape(rays_rgb, [-1, 3, 3]) # [(N-1)*H*W, ro+rd+rgb, 3]
rays_rgb = rays_rgb.astype(np.float32)
print('shuffle rays')
np.random.shuffle(rays_rgb) # 打乱光线
print('done')
i_batch = 0
# 统一一个时刻放入cuda
# Move training data to GPU
if use_batching:
images = torch.Tensor(images).to(device)
rays_rgb = torch.Tensor(rays_rgb).to(device)
poses = torch.Tensor(poses).to(device)
# --------------------------------------------------------------------------------------------------------
print('Begin')
print('TRAIN views are', i_train)
print('TEST views are', i_test)
print('VAL views are', i_val)
# 训练部分的代码
# 两万次迭代
# 可能是强迫症,不想在保存文件的时候,出现19999这种数字
N_iters = 200000 + 1
start = start + 1
for i in trange(start, N_iters):
time0 = time.time()
# Sample random ray batch
if use_batching:
# Random over all images
# 一批光线
batch = rays_rgb[i_batch:i_batch + N_rand] # [B, 2+1, 3*?]
batch = torch.transpose(batch, 0, 1)
batch_rays, target_s = batch[:2], batch[2] # 前两个是rays_o和rays_d, 第三个是target就是image的rgb
i_batch += N_rand
if i_batch >= rays_rgb.shape[0]:
# 所用光线用过之后,重新打乱
print("Shuffle data after an epoch!")
rand_idx = torch.randperm(rays_rgb.shape[0])
rays_rgb = rays_rgb[rand_idx]
i_batch = 0
else:
# Random from one image
img_i = np.random.choice(i_train)
target = images[img_i] # [400,400,3] 图像内容
target = torch.Tensor(target).to(device)
pose = poses[img_i, :3, :4]
if N_rand is not None:
rays_o, rays_d = get_rays(H, W, K, torch.Tensor(pose)) # (H, W, 3), (H, W, 3)
# precrop_iters: number of steps to train on central crops
if i < args.precrop_iters:
dH = int(H // 2 * args.precrop_frac)
dW = int(W // 2 * args.precrop_frac)
coords = torch.stack(
torch.meshgrid(
torch.linspace(H // 2 - dH, H // 2 + dH - 1, 2 * dH),
torch.linspace(W // 2 - dW, W // 2 + dW - 1, 2 * dW), indexing='ij',
), -1)
if i == start:
print(
f"[Config] Center cropping of size {2 * dH} x {2 * dW} is enabled until iter {args.precrop_iters}")
else:
coords = torch.stack(torch.meshgrid(torch.linspace(0, H - 1, H),
torch.linspace(0, W - 1, W), indexing='ij'),
-1) # (H, W, 2)
coords = torch.reshape(coords, [-1, 2]) # (H * W, 2)
select_inds = np.random.choice(coords.shape[0], size=[N_rand], replace=False) # (N_rand,)
# 选出的像素坐标
select_coords = coords[select_inds].long() # (N_rand, 2)
rays_o = rays_o[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
rays_d = rays_d[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
batch_rays = torch.stack([rays_o, rays_d], 0) # 堆叠 o和d
# target 也同样选出对应位置的点
# target 用来最后的mse loss 计算
target_s = target[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
##### Core optimization loop #####
# rgb 网络计算出的图像
# 前三是精细网络的输出内容,其他的还保存在一个dict中,有5项
rgb, disp, acc, extras = render(H, W, K, chunk=args.chunk, rays=batch_rays,
verbose=i < 10, retraw=True,
**render_kwargs_train)
optimizer.zero_grad()
# 计算loss
img_loss = img2mse(rgb, target_s)
loss = img_loss
# 计算指标
psnr = mse2psnr(img_loss)
# rgb0 粗网络的输出
if 'rgb0' in extras:
img_loss0 = img2mse(extras['rgb0'], target_s)
loss = loss + img_loss0
psnr0 = mse2psnr(img_loss0)
loss.backward()
optimizer.step()
# NOTE: IMPORTANT!
### update learning rate ###
# 学习率衰减
decay_rate = 0.1
decay_steps = args.lrate_decay * 1000
new_lrate = args.lrate * (decay_rate ** (global_step / decay_steps))
for param_group in optimizer.param_groups:
param_group['lr'] = new_lrate
################################
# 保存模型
if i % args.i_weights == 0:
path = os.path.join(basedir, expname, '{:06d}.tar'.format(i))
torch.save({
# 运行的轮次数目
'global_step': global_step,
# 粗网络的权重
'network_fn_state_dict': render_kwargs_train['network_fn'].state_dict(),
# 精细网络的权重
'network_fine_state_dict': render_kwargs_train['network_fine'].state_dict(),
# 优化器的状态
'optimizer_state_dict': optimizer.state_dict(),
}, path)
print('Saved checkpoints at', path)
# 生成测试视频,使用的是render_poses (这个不等同于test数据)
if i % args.i_video == 0 and i > 0:
# Turn on testing mode
with torch.no_grad():
rgbs, disps = render_path(render_poses, hwf, K, args.chunk, render_kwargs_test)
print('Done, saving', rgbs.shape, disps.shape)
moviebase = os.path.join(basedir, expname, '{}_spiral_{:06d}_'.format(expname, i))
# 360度转一圈的视频
imageio.mimwrite(moviebase + 'rgb.mp4', to8b(rgbs), fps=30, quality=8)
imageio.mimwrite(moviebase + 'disp.mp4', to8b(disps / np.max(disps)), fps=30, quality=8)
# 执行测试,使用测试数据
if i % args.i_testset == 0 and i > 0:
testsavedir = os.path.join(basedir, expname, 'testset_{:06d}'.format(i))
os.makedirs(testsavedir, exist_ok=True)
print('test poses shape', poses[i_test].shape)
with torch.no_grad():
render_path(torch.Tensor(poses[i_test]).to(device), hwf, K, args.chunk, render_kwargs_test,
gt_imgs=images[i_test], savedir=testsavedir)
print('Saved test set')
# 用时
dt = time.time() - time0
# 打印log信息的频率
if i % args.i_print == 0:
tqdm.write(f"[TRAIN] Iter: {i} Loss: {loss.item()} PSNR: {psnr.item()} Time: {dt}")
global_step += 1- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
- 124.
- 125.
- 126.
- 127.
- 128.
- 129.
- 130.
- 131.
- 132.
- 133.
- 134.
- 135.
- 136.
- 137.
- 138.
- 139.
- 140.
- 141.
- 142.
- 143.
- 144.
- 145.
- 146.
- 147.
- 148.
- 149.
- 150.
- 151.
- 152.
- 153.
- 154.
- 155.
- 156.
- 157.
- 158.
- 159.
- 160.
- 161.
- 162.
- 163.
- 164.
- 165.
- 166.
- 167.
- 168.
- 169.
- 170.
- 171.
- 172.
- 173.
- 174.
- 175.
- 176.
- 177.
- 178.
- 179.
- 180.
- 181.
- 182.
- 183.
- 184.
- 185.
- 186.
- 187.
- 188.
- 189.
- 190.
- 191.
- 192.
- 193.
- 194.
- 195.
- 196.
- 197.
- 198.
- 199.
- 200.
- 201.
- 202.
- 203.
- 204.
- 205.
- 206.
- 207.
- 208.
- 209.
- 210.
- 211.
- 212.
- 213.
- 214.
- 215.
- 216.
- 217.
- 218.
- 219.
- 220.
- 221.
- 222.
- 223.
- 224.
- 225.
- 226.
- 227.
- 228.
- 229.
- 230.
- 231.
- 232.
- 233.
- 234.
- 235.
- 236.
- 237.
- 238.
- 239.
- 240.
- 241.
- 242.
- 243.
- 244.
- 245.
- 246.
- 247.
- 248.
- 249.
- 250.
- 251.
- 252.
- 253.
- 254.
- 255.
- 256.
- 257.
- 258.
- 259.
- 260.
- 261.
- 262.
- 263.
- 264.
- 265.
- 266.
- 267.
- 268.
- 269.
- 270.
- 271.
- 272.
- 273.
- 274.
- 275.
- 276.
- 277.
- 278.
- 279.
- 280.
- 281.
- 282.
- 283.
- 284.
- 285.
- 286.
- 287.
- 288.
- 289.
- 290.
- 291.
- 292.
- 293.
- 294.
- 295.
- 296.
- 297.
- 298.
- 299.
- 300.
- 301.
- 302.
- 303.
- 304.
- 305.
- 306.
- 307.
- 308.
- 309.
- 310.
- 311.
- 312.
- 313.
- 314.
- 315.
- 316.
- 317.
- 318.
- 319.
- 320.
- 321.
- 322.
- 323.
- 324.
- 325.
- 326.
- 327.
- 328.
- 329.
到这里,我们对于NeRF整体结构的解读基本完成。此次解读基本涵盖了NeRF代码的运行流程与逻辑,包括主要循环前的参数加载、各种数据集的处理、NeRF网络结构、Positional encoding、粗细两次采样、体渲染、整体训练部分的原理以及相应代码的具体解读。希望这篇总结可以让各位读者有所收获,能更加精确地使用或修改NeRF类的代码,做出优秀的工程和科研论文。















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









