






做小目标检测的正道还是那些只有小物体的任务?小目标检测还有哪些有价值的可深入的研究方向?本文讲述了在研究小目标检测的心路历程以及对小目标检测近年来的发展现状的看法。
当时COCO sota还只有61.0 AP,而现在已经到了66.0 AP,小物体的AP_S也从44.0 AP提升到了48.5 AP;另外当时还只是流行把Transformer当backbone,而如今DETR-based方法已经屠榜。
正如作者上篇文章所说的,一开始是坚定地朝着攻克通用小目标检测难题(COCO)的方向前进的,在对COCO中的小物体一通数据分析后,里面大量人眼都很难识别的hard case让我感到隐隐的绝望,发现自己太小看COCO了。经过一段时间的迷茫,我突然想着能不能去COCO数据集原文找灵感,发现了下图中的这句话:

当时觉得瞬间找到了方向,既然COCO的初衷就是用context来解小物体,那我就先朝着这条路走走试试。
于是对Context-based方法的探索就开始了,同时也在不知不觉中掉入一个大坑。Context-based方法主要有用self-attention建模物体关系的Relation Network[1]以及用图卷积神经网络GCN建模物体关系的SGRN[2]和Reasoning-RCNN[3]两大类。当时觉得Relation Network在2018年就被提出,改进空间不大,用GCN或许还有机会,于是开始着手复现SGRN。SGRN的核心思想是将proposal视作一个个物体,proposal的RoI特征视作物体特征,然后将proposal特征当作节点特征,proposal的中心点位置当作节点坐标,利用GCN建模物体之间的语义关联和空间关联。一开始我没有源码,但看论文的效果那么好,就头铁从零开始撸,整体框架搭起来倒是很快,只是一些细节文章里没有写清楚,比如GCN聚合邻近节点信息时权重是否做了归一化,只能自己不断尝试(PS:如非必要,千万不要在无源码的情况下复现AI论文,一是论文可能造假,二是很多技术细节论文里是不会写的,而这些细节的缺失往往是致命的)。
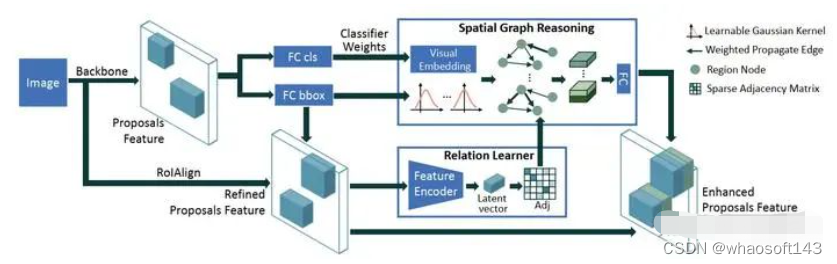
SGRN框架图
结果经过一个月的尝试,怎么都达不到论文里的效果,让我大受打击,疯狂怀疑自己的能力,于是通过某渠道直接找到了作者(一开始连发几封邮件未回),要到了源码。对比自己的代码,确实有些细节没考虑,于是开始用源码训练,发现提升确实是有的,但是可视化出来的物体关系图完全不像图中那样可解释,那么提升来自于哪里呢?一番研究后,我大受震撼,Baseline是Faster R-CNN,而源码是Faster R-CNN后再加一个relation reasoning stage,相当于three-stage模型,实际是直接用的Cascade R-CNN+GCN,经过实验发现性能的绝大部分提升是来源于Cascade R-CNN本身,因为即使我去除了GCN的relation reasoning过程,性能也提升了很多,而GCN的relation reasoning提升非常小。这意味着论文实际的baseline是Cascade R-CNN,但论文完全没有提到这点。。。并且,我发现HTD[4](也使用了GCN做relation reasoning)的作者在复现SGRN时和我发现了一样的问题,我瞬间觉得人生都灰暗了。。。
上述事件持续了几个月事件,一边是论文结果无法复现,一边是导师要结果,觉得是我复现问题,是我研究生期间极其焦虑、痛苦的一段时期,也彻底粉碎了读博的念头,最终的结果是迫于毕业的压力,随便找了个简单的子任务重头开始做小目标检测。好在失败的研究经历也算是有了一定的研究基础,加上华为的作息,用两个多月魔改现有方法水了一篇论文。论文刚好在过年那天被接收,我记得看到邮件的那刻,我蹦跳着下楼告诉爸妈和我哥,兴奋地喊着“我毕业了!我毕业了!”,然后开心地举杯庆祝,心里悬着的石头终于落下。
回想这失败的学术生涯,除了自己本身的学术天赋不足外,造成此种结果的另一个重要原因是小目标检测这个问题太难了。而选择在COCO这种多尺度数据集上做小目标检测更是一个愚蠢的决定,因为大、小物体是相互影响的,你关注小物体,那么大物体便可能因为缺少关注而损失性能,这一点在QueryDet[5](第一版论文,见下图)上也有体现,我自己做实验时也发现过这种现象。这也是为什么在COCO上做小目标检测的少之又少,因为你要提升小物体AP,且要保持大中物体AP不掉,那么意味着你的总体AP要提升,那么既然同样是要提升总体AP,我从全局地去优化而不是只从最难的小物体去切入不是更简单吗?这也是COCO上SOTA方法的思路,提升整体AP,小物体AP的提升是自然而然的,而不用特地发明方法提升小物体AP。当然值得注意的是,流行的Transformer类方法并不太适合检测小物体,主要原因是小物体检测需要高分辨率特征,而这会使得self-attention的计算量爆炸,虽然也有一些缓解方法,但目前无法从根本上解决该问题。
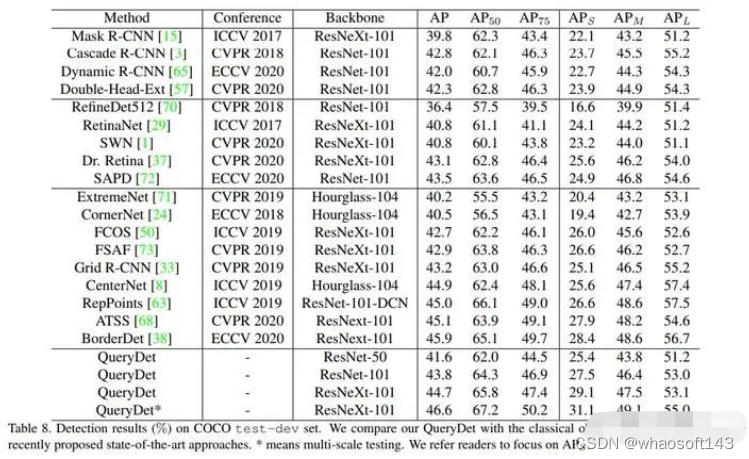
QueryDet的实验结果,AP_S比过了其他方法,但AP_M和AP_L却比不上
做小目标检测的正道还是那些只有小物体的任务,例如交通标志检测、卫星图像检测,或者自己发布新的benchmark,如TinyPerson[6]、AI-TOD[7],然后针对数据集特性,设计方法达到SOTA(RFLA[8]和DotD[9]均是如此)。自己一直关注的RFLA作者便是走的后面那条路,他是我见过的唯一做小目标检测能频繁发顶会的,研究思路很灵活,最新的工作已经转到做旋转小目标检测了,且不论他的工作对领域的实际贡献如何,至少认为这是在学术上做小目标检测的一条可行之路,大家可以多关注他。

SHAI方法,将高清图crop分别检测
但是必须要指出的是,学术界在小目标检测的进展已经停滞很久了,查查每年顶会的小目标检测相关论文就知道了,当然这也和深度学习的整体饱和大趋势有关。另外,小目标检测是个很有应用价值的方向,特别是在落地时,基本上都是卡在小目标这种corner case上(例如自动驾驶里的红绿灯检测、远处车辆检测),所以我上一篇文章才会有那么多读者关注。
从个人经验来看,在那么多小目标检测方法中,最有用的还是数据增广(例如Stitcher[10]、copy-paste[11])、放大输入图片(例如用GAN放大再检测、crop成patch再放大的SAHI方法[12])、使用高分辨率的特征(例如QueryDet[5]),或者针对极小目标(<=16*16 pixel)的检测,设计合适的标签分配方法(例如RFLA[8]、DotD[9]),以让小目标有更多的正样本。这些方法的共性就是简洁,正所谓大道至简,它们背后的思想都非常朴素,无非是增加小目标的训练样本数量(数据增广)、放大图片或特征使小物体变成大物体(放大输入图片或使用高分辨率特征)、增加小目标的正样本数量(合适的标签分配方法)。
而最花哨却无用的便是利用物体关系来辅助检测小物体一类的方法,其一,大部分小目标检测数据集没有像COCO一样丰富的物体关系可用(比如有读者检测的是朴实无华的小石头);其二,就算可用,现有的AI在关系推理方面的能力以及数据集的规模让模型不足以学习到理想的物体关系,往往最后上帝都不知道模型学到的是什么,并且从COCO上的实验结果来看,性能提升非常有限;其三,这方面已经研究烂了,被学术界验证最有效的用attention建模关系的方法(Relation Network[1]),已经被DETR类方法设为默认配置了。
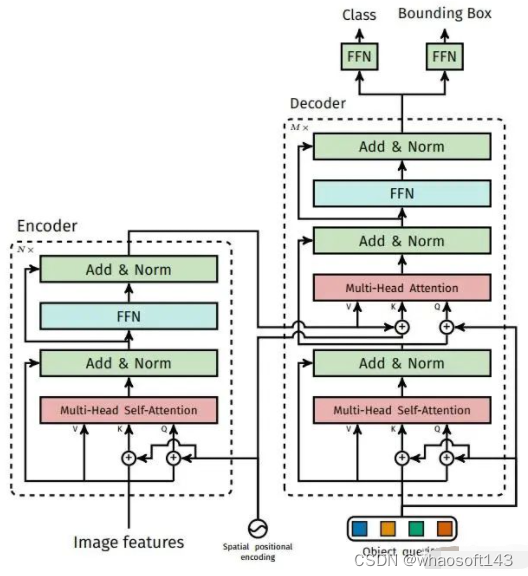
DETR Decoder中的multi-head self-attention本质就是在建模物体关系
除了走学术道路,还可以走工程道路-->打比赛。记得上篇文章里有读者问我小目标检测是工程问题还是学术问题,当时我的回答是学术问题,如今我倾向于认为是工程问题,因为对于小目标检测而言,花里胡哨的方法通常都不管用,这意味着不好发论文;管用的方法朴实无华,如放大图片或复制粘贴小物体等等,但难以写成论文。因此你可以尝试去打比赛,不用再因为所谓的创新性束手束脚,十八般武艺齐上就行,能涨点就是好方法,这种比赛通常在各类比赛平台上都能找到,例如CodaLab最近的Small Object Detection Challenge for Spotting Birds;很久之前Kaggle上的小麦检测大赛;飞桨平台的海上船舶智能检测大赛等等(如果大家有需要的话,我可以花时间整理一篇文章专门讲一些比赛相关的,可以评论留言),比赛打的好的话,也可以利用比赛方案魔改出一篇论文,毕竟有性能了,剩下的就是编故事。自己也是受益于比赛才勉强找到不错的工作,因此建议同领域的读者在发不出顶会的时候,但又想搞算法的话,不要一条路走到黑,尝试尝试打比赛这条路,要不然秋招教你做人。















 3584
3584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









