







 背景写这篇文章主要是介绍一下我做数据仓库ETL同步的过程中遇到的一些有意思的内容和提升程序运行效率的过程。关系型数据库:项目初期:游戏的运营数据比较轻量,相关的运营数据是通过Java后台程序聚合查询关系型数据库MySQL完全可以应付,系统通过定时任务每日统计相关数据,等待运营人员查询即可。项目中后期:随着开服数量增多,玩家数量越来越多,数据库的数据量越来越大,运营后台查询效率越来越低。对于普通的关...
背景写这篇文章主要是介绍一下我做数据仓库ETL同步的过程中遇到的一些有意思的内容和提升程序运行效率的过程。关系型数据库:项目初期:游戏的运营数据比较轻量,相关的运营数据是通过Java后台程序聚合查询关系型数据库MySQL完全可以应付,系统通过定时任务每日统计相关数据,等待运营人员查询即可。项目中后期:随着开服数量增多,玩家数量越来越多,数据库的数据量越来越大,运营后台查询效率越来越低。对于普通的关...
背景
写这篇文章主要是介绍一下我做数据仓库ETL同步的过程中遇到的一些有意思的内容和提升程序运行效率的过程。
关系型数据库:
项目初期:游戏的运营数据比较轻量,相关的运营数据是通过Java后台程序聚合查询关系型数据库MySQL完全可以应付,系统通过定时任务每日统计相关数据,等待运营人员查询即可。
项目中后期:随着开服数量增多,玩家数量越来越多,数据库的数据量越来越大,运营后台查询效率越来越低。对于普通的关系型来说,如MySQL,当单表存储记录数超过500万条后,数据库查询性能将变得极为缓慢,而往往我们都不会只做单表查询,还有多表join。这里假如有100个游戏服,每个服有20张表,而每个表有500W数据,那么:
总数据量 = 100 * 20 * 500W = 10亿 按当时的库表结构,换算成磁盘空间,约为100G左右
我的天呐,现在没有单机的内存能同一时间载入100G的数据
https://www.zhihu.com/question/19719997
所以,考虑到这一点,Hive被提出来解决难题!
数据仓库
Hive适合做海量数据的数据仓库工具, 因为数据仓库中的数据有这两个特点:最全的历史数据(海量)、相对稳定的;所谓相对稳定,指的是数据仓库不同于业务系统数据库,数据经常会被更新,数据一旦进入数据仓库,很少会被更新和删除,只会被大量查询。而Hive,也是具备这两个特点
二、项目架构设计
在这里先说下初期项目架构的探索,因为数据流向,其实最终就是从MYSQL--------->Hive中,我使用的是Jdbc方式。为什么不使用下列工具呢?
Sqoop, 因为该游戏每个服有将近80张表,然后又有很多服,以后还会更多,而每个服的库表数据结构其实是完全一样的,只是IP地址不一样,使用Sqoop的话,将会需要维护越来越多的脚本,再者Sqoop没法处理原始数据中一些带有Hive表定义的行列分隔符
DataX 阿里开源的数据同步中间件,没做过详细研究
1、全局缓存队列
使用生产者消费者模型,中间使用内存,数据落地成txt
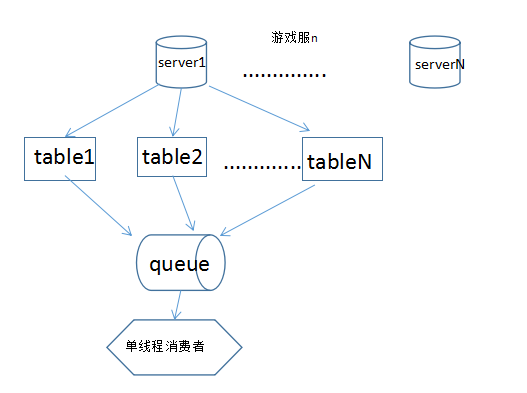
首先生产者通过Jdbc获取源数据内容,放入固定大小的缓存队列,同时消费者不断的从缓存读取数据,根据不同的数据类型分别读取出来,并逐条写入相应的txt文件。
速度每秒约8000条。
这样做表面上看起来非常美好,流水式的处理,来一条处理一下,可是发现消费的速度远远赶不上生产的速度,生产出来的数据会堆积在缓存队列里面,假如队列不固定长度的话,这时候还会大量消耗内存,所以为了提升写入的速度,决定采用下一种方案
2、每一张表一个缓存队列及writer接口
每张表各自起一个生产者消费者模型,消费者启动时初始化相应的writer接口,架构设计如下:
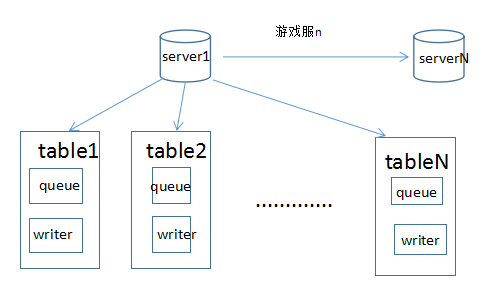
table1的生产者通过Jdbc获取源数据内容,放入table自带的固定大小的缓存队列,同时table1相应的消费者不断的从缓存读取数据,根据不同的数据类型分别读取出来,并逐条写入相应的txt文件。
速度每秒约2W条。
这样生产者线程可以并发的进行,通过控制生产者线程的数量,可以大大提高处理的效率, 项目关键代码如下:
1)线程池
/***
*
*
* @描述 任务线程池*/
public classDumpExecuteService {private static ExecutorService dumpServerWorkerService; //游戏服任务
private static ExecutorService dumpTableWorkerService; //表数据任务
private static ExecutorService dumpReaderWorkerService; //读取数据任务
private static ExecutorService dumpWriterWorkerService; //写数据结果任务
/***
* 初始化任务线程池
* @param concurrencyDBCount 并发数量*/
public synchronized static void startup(intconcurrencyDBCount) {if (dumpServerWorkerService != null)return;if (concurrencyDBCount > 2)
concurrencyDBCount= 2; //最多支持两个数据库任务并发执行
if (concurrencyDBCount < 1)
concurrencyDBCount= 1;
dumpServerWorkerService= Executors.newFixedThreadPool(concurrencyDBCount, newNamedThreadFactory("DumpExecuteService.dumpServerWorkerService" +System.currentTimeMillis()));
dumpTableWorkerService= Executors.newFixedThreadPool(2, new NamedThreadFactory("DumpExecuteService.dumpTableWorkerService"
+System.currentTimeMillis()));
dumpWriterWorkerService= Executors.newFixedThreadPool(8, new NamedThreadFactory(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3038
3038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









