






有时候数据库中表的数据可能存在重复的情况,如何从表中找出重复的数据呢?本文中提到两种方式:
使用group by + 临时表
使用group by + having

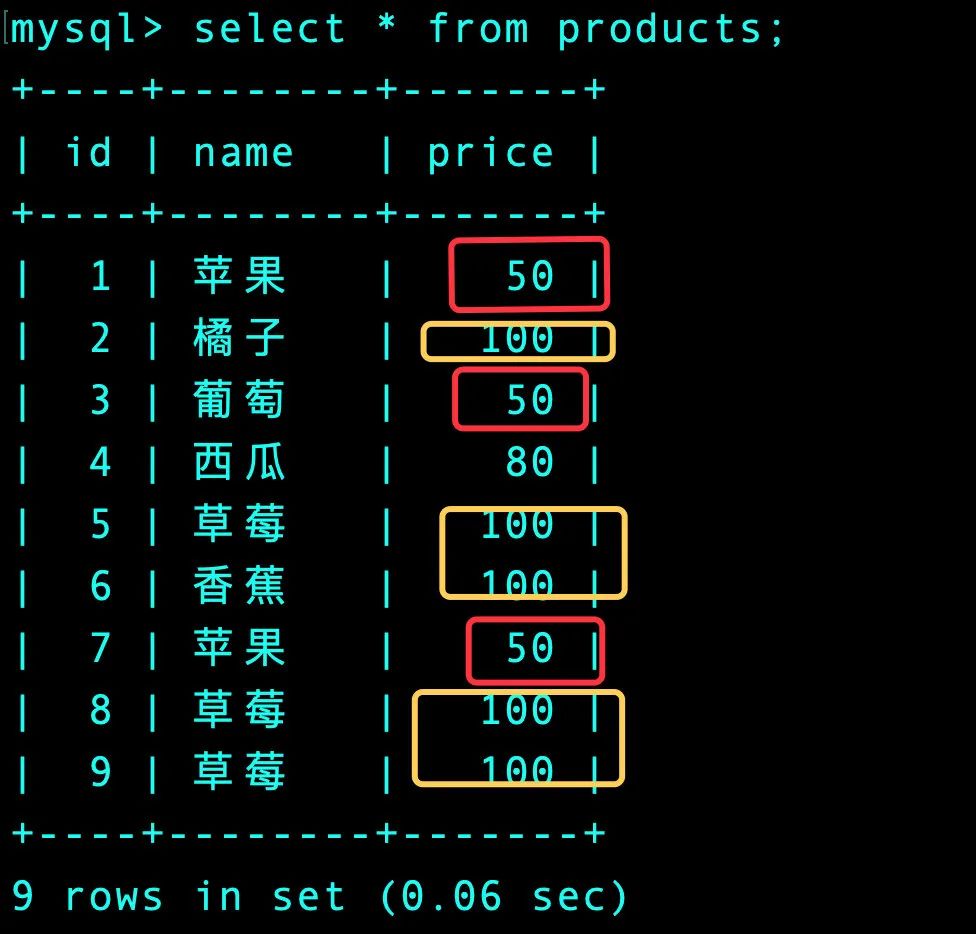
需求
根据价格price找出相同数据的行记录。可以见到下面的数据中name中的值会出现相同的记录,需要将它们找出来。
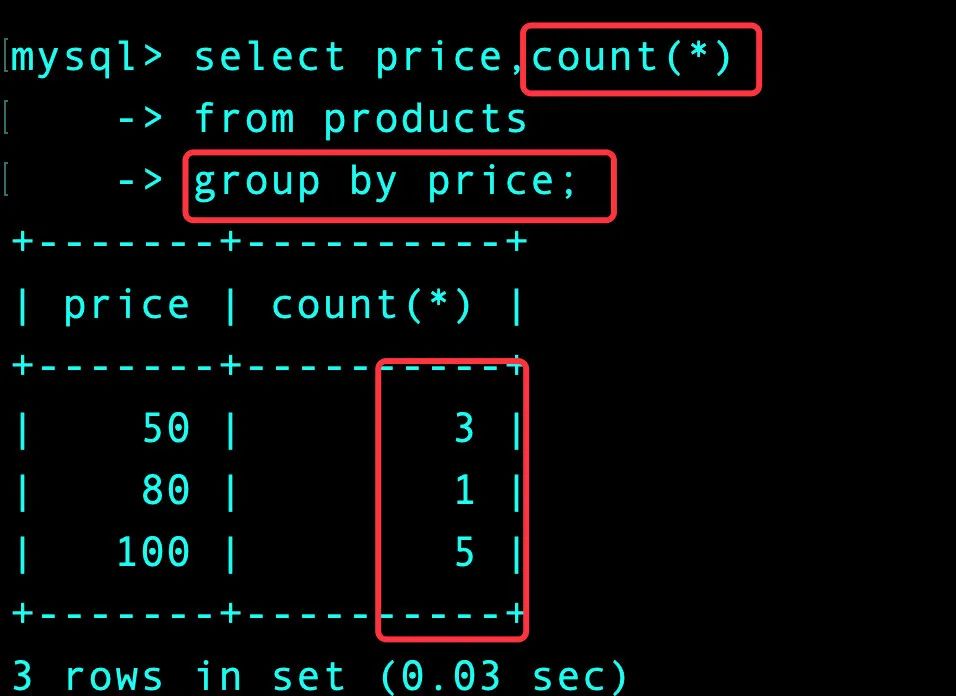
方式1-临时表实现
- 先统计每个price出现的次数,次数大于1则肯定是重复的
- 将上面的结果看做是一个临时表,从临时表中直接取出重复的行记录
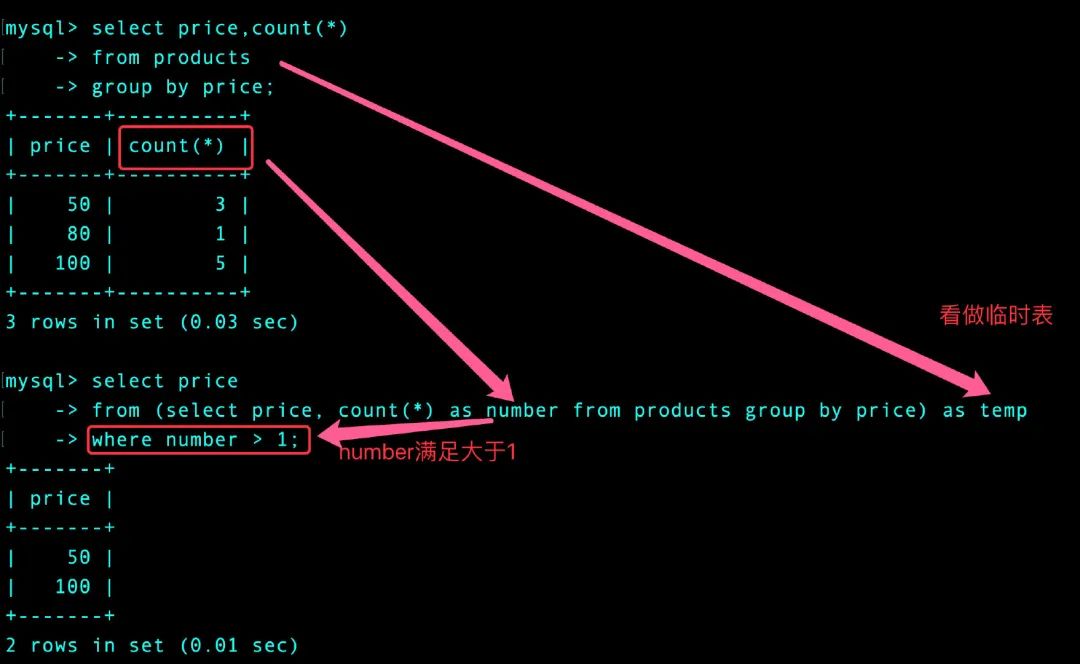
从原始数据中看出来只有价格50和100具有重复值
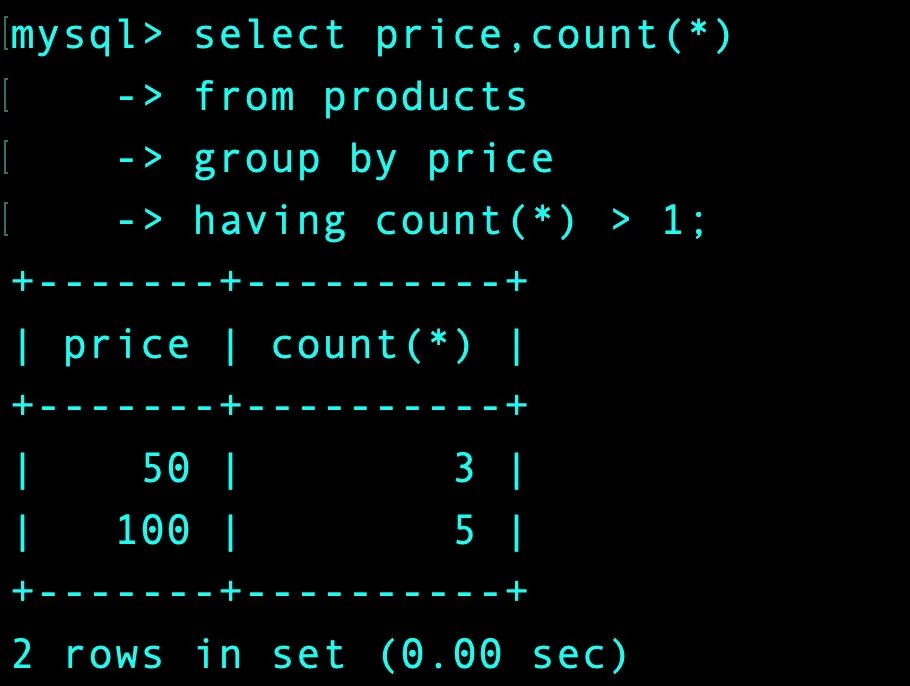
方式2-使用having
mysql> select price,count(*)
-> from products
-> group by price
-> having count(*) > 1; -- 直接指定条件
重复出现n次的数据
mysql> select price, count(*)
-> from products
-> group by price
-> having count(*) > n; -- 直接指定条件
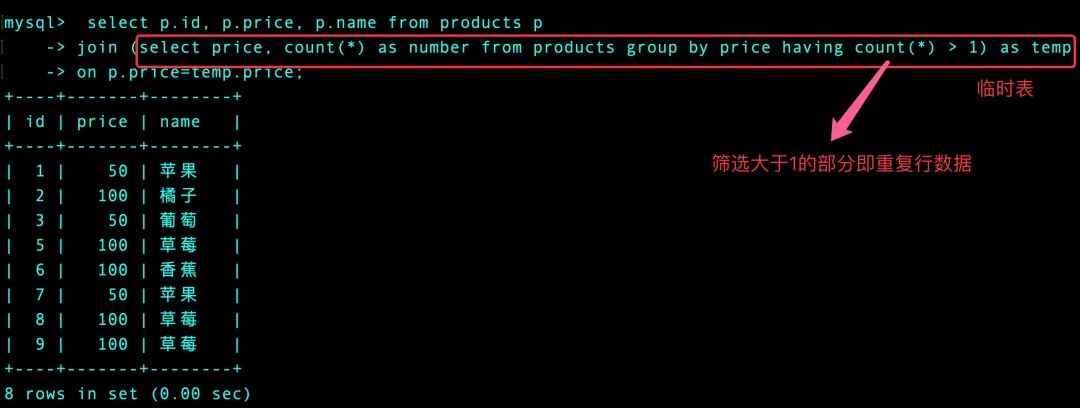
需求-提取重复行的全部数据
select p.id, p.price, p.name
from products p
join (select price, count(*) as number
from products
group by price
having count(*) > 1) as temp -- 将临时表的price 和 原始表的price进行联结,查询原始表的全部数据
on p.price=temp.price;
SQL语句执行顺序
- select
- from
- where
- group by
- having
- order by(desc是降序)















 1480
1480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









