






B题相关优秀论文+问题一数据预处理代码分享链接:
https://pan.baidu.com/s/1wpNZYW5v8jf2iM0uB7pDEA
提取码:sxjm
| B | 2024 | 111 |
钢铁产品质量优化
摘要
冷轧带钢是钢铁企业的高附加值产品,其产品质量稳定性对于钢铁企业的经 济效益具有非常重要的影响。在实际生产中,冷连轧之后的带钢需要经过连续退 火处理来消除因冷轧产生的内应力并提高其机械性能。连续退火的工艺一般包括加热、保温、缓冷、快冷、过时效、淬火等加工阶段。由于连续退火工序中各阶段的工艺参数之间存在耦合性(加热炉的温度设定会影响后续均热与冷却温度的设定,以及带钢穿行速度),导致难以建立该工序的机理模型,从而为在线的产品质量控制与优化带来挑战。
针对问题一,首先要做的就是检查数据并清洗,检查缺失值并处理异常值,然后对所有的数据进行归一化处理。针对带钢的机械性能,将工艺参数和对应的带钢机械性能数据进行斯皮尔曼相关性分析,初步筛选出相关性较高的参数,然后哦再采用因子分析和随机森林进一步筛选出重要的参数,得到哪些参数对于带钢的机械性能具有显著影响。
针对问题二,建立一个数据驱动的带钢产品质量在线检测模型,并分析该模型的性能。该问题首先需要选择对带钢硬度有潜在影响的特征作为模型的输入变量,这里从问题一求得到结果中选择变量进行分析,采用决策树的方法构建模型,并利用多项式特征生成器生成二次交互项的特征。将数据分割为训练集和测试集后,利用网格搜索和交叉验证优化决策树回归模型,选择最佳参数并训练模型。最后,评估模型在训练集和测试集上的性能,包括均方误差(MSE)、平均绝对误差(MAE)和决定系数(R^2),并使用matplotlib可视化决策树的结构来完成一个在线的检测模型。
针对问题三,设立目标函数与约束条件,使用遗传算法、粒子群优化等全局优化算法进行参数优化。然后通过模拟退火、梯度下降等局部优化算法进一步微调参数。在优化后的参数设置下,使用已建立的在线检测模型预测硬度,验证优化效果。
关键词:随机森林,决策树,特征组合,梯度下降,优化算法


22页 1万字+ 7页无水印结果 代码(py+ma两套)运行教程
1.1 问题背景
冷轧带钢是钢铁企业的高附加值产品,其产品质量稳定性对于钢铁企业的经 济效益具有非常重要的影响。在实际生产中,冷连轧之后的带钢需要经过连续退 火处理来消除因冷轧产生的内应力并提高其机械性能。连续退火的工艺流程一般包括加热、保温、缓冷、快冷、过时效、淬火等加工阶段。首先,带钢在加热炉中被加热到指定的温度,然后在均热炉中进行保温使得带钢内外的 温度一致;接着,带钢依次穿过缓冷炉、快冷炉、过时效炉、淬火炉等阶段,以实现带钢内部金属组织的再结晶,达到需要的力学性能。处理完成后的板卷会通过实验室对其机械性能进行离线检测,如果性能不达标则会产生经济损失。
由于连续退火工序中各阶段的工艺参数之间存在耦合性(加热炉的温度设定 会影响后续均热与冷却温度的设定,以及带钢穿行速度),导致难以建立该工序 的机理模型,从而为在线的产品质量控制与优化带来挑战。为了实现对连退带钢产品质量的优化,带钢产品的生产过程工艺参数和对应的带钢机械性能数据的分析尤为重要。
1.2 问题回顾
问题1要求确定哪些参数对于带钢的机械性能具有重要影响;
问题2要求建立一个数据驱动的带钢产品质量在线检测模型,并分析该模型的性能;
问题3要求帮助现场的操作人员建立一个带钢工艺参数优化的解决方案,使其不再根据个人经验对带钢产品的工艺参数进行设定,提高工艺参数选取的可靠性。
一、模型假设
为了方便模型的建立与模型的可行性,我们这里首先对模型提出一些假设,使得模型更加完备,预测的结果更加合理。
1.假设给出的数据均为真实数据,真实有效。
2.假设各工艺参数之间是相对独立的,尽管在实际生产中可能存在某种程度的相互影响。在建模过程中,我们忽略这种潜在的交互作用。
3.假设在模型中考虑的工艺参数(如带钢速度、加热炉温度等)是最主要的影响因素,其他未考虑的因素对结果的影响可以忽略。假设给出的脱敏数据没有造成数据的损坏。
4.假设在优化过程中,所有参数都在预定义的范围内变化,不会出现超出合理范围的情况。
5.假设优化模型得到的工艺参数在实际生产中是可行的,即这些参数可以在实际的生产设备中设置和实现。
6.假设在实际生产中,其他潜在因素(如环境变化、设备老化等)对优化效果的影响可以忽略不计。
二、问题求解与分析
4.1 问题一求解与分析
4.1.1 问题一分析
针对问题一,首先要做的就是检查数据并清洗,检查缺失值并处理异常值,然后对所有的数据进行归一化处理。针对带钢的机械性能,将工艺参数和对应的带钢机械性能数据进行斯皮尔曼相关性分析,初步筛选出相关性较高的参数,然后哦再采用因子分析和随机森林进一步筛选出重要的参数,得到哪些参数对于带钢的机械性能具有显著影响。
4.1.2 问题一建模与求解
1、数据预处理
针对我们给出的附件1带钢数据,首先要做的就是对数据进行预处理操作。对于实际生产中获得的许多带钢产品的生产过程工艺参数和对应的带钢机械性能数据,数据值的确实是最有可能产生的问题,因此首先要进行缺失值的检查。这里对总共的1000个数据进行缺失值统计检测,如图1所示。可以看到并无缺失值,因此不需要对数据进行缺失值删除或填补操作。
图1
接下里处理数据中的异常值。异常值可能是由于测量错误、数据录入错误或极端条件产生的。对数据中的带钢特征属性进行可视化操作,如图2所示,可视化每个属性的箱线图(最小值、第一四分位数、中位数、第三四分位数、最大值以及异常值)。从图2可以看到,带钢厚度数据主要集中在8000到8500之间,有一些较小和较大的异常值。带钢宽度数据较为集中在190到200之间,有一些显著的异常值。碳含量数据主要集中在300到400之间,有一些小于200和大于400的异常值。硅含量数据主要集中在6到10之间,有一些显著的异常值。带钢速度数据主要集中在540到550之间,分布较为均匀,没有明显的异常值。加热炉温度数据主要集中在720到740之间,有一些小于700的异常值。均热炉温度数据集中在680到700之间,存在较多的异常值。缓冷炉温度、过时效炉温度、快冷炉温度、淬火炉温度,存在较多的异常值。平整机张力数据集中在2000到2400之间,有一些小于2000和大于2500的异常值。从图中我们还是可以看到有不少异常值的。
图3是其特征属性分布情况,可以看到,大多数属性呈现正态分布或近似正态分布,但也存在一些属性分布较为分散。带钢厚度呈多峰分布,主要集中在8300至8700之间,存在一些极端值。带钢宽度的分布相对分散,没有明显的集中区域。碳含量大部分集中在200至400之间,呈现正态分布趋势。硅含量分布较为分散,主要集中在0至20之间。带钢速度分布较为集中,主要集中在400至600之间。加热炉温度呈现近似正态分布,集中在700至800之间。均热炉温度呈现近似正态分布,集中在650至750之间。缓冷炉温度分布较为分散,集中在400至600之间。过时效炉温度呈现近似正态分布,集中在400至500之间。
快冷炉温度呈现近似正态分布,集中在400至500之间。淬火炉温度呈现近似正态分布,集中在300至500之间。平整机张力分布较为分散,集中在20至50之间。而且,大多数属性存在异常值,需要进一步处理。
针对此情况,采用Z-score判断异常值。z-score规范化(零均值规范化)是将属性A的值根据其平均值和标准差进行规范化。

2、相关性分析
由图3我们可以知道,多数属性呈现正态分布或近似正态分布,但也存在一些属性分布较为分散。由于皮尔逊相关系数适合于正态分布的情况,因此采用斯皮尔曼系数进行相关性分析。
计算每个参数与带钢硬度之间的斯皮尔曼相关系数,以初步判断参数与硬度之间的线性相关程度。斯皮尔曼相关系数的值范围从-1到1,其中1表示完全正相关,-1表示完全负相关,0表示无线性相关。然后采用使用热力图(图4)展示所有参数之间的相关性矩阵,帮助直观地理解参数之间的相关性。热力图的每个单元格颜色深浅表示对应两个参数之间的相关系数大小。
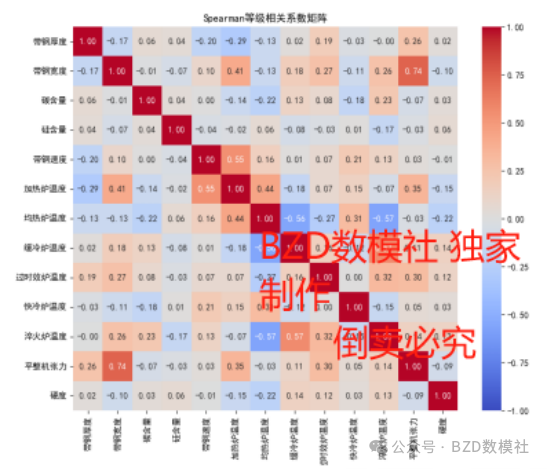

从图4可以看到,带钢宽度与平整机张力具有较强的正相关关系(0.74),表明带钢宽度增加时,平整机张力也会增加。此外,带钢宽度与加热炉温度也存在一定的正相关关系(0.41)。带钢速度与加热炉温度呈现一定的正相关关系(0.55),意味着带钢速度增加时,加热炉温度也会增加。缓冷炉温度与过时效炉温度(0.57)呈现较强的正相关关系,说明缓冷炉温度增加时,过时效炉温度也会增加。过时效炉温度与快冷炉温度(0.57)和快冷炉温度与淬火炉温度(0.57)均存在较强的正相关关系,说明这些温度参数之间相互影响。
总体而言,各个工艺参数与硬度之间的相关性都不强,相关系数都在-0.1到0.14之间。尽管有些参数(如碳含量、均热炉温度、缓冷炉温度、过时效炉温度、淬火炉温度)对硬度有一定的影响,但影响程度较弱,因此需要结合多个因素共同分析。
3、特征分析
(1)随机森林算法(Random Forest)是一种基于决策树的集成学习算法,主要用于分类和回归任务。它由多个决策树组成,每个决策树都是独立训练的,并通过组合多个决策树的预测结果来提高模型的准确性和稳定性。随机森林的基本思想是:每次随机选取一些特征,独立建立树,重复这个过程,保证每次建立树时变量选取的可能性一致,如此建立许多彼此独立的树,最终的分类结果由这些树共同确定。
采用随机森林能够同时达到提升和自适应装袋一样好的结果,中间不需要改变训练集,对噪声和稳健性比提升要好。适合高维输入变量的特征选择,不需要提前对变量进行删减和筛选。在这里,带钢数据属于高维数据,因此比较适合。使用随机森林算法得到的特征重要性如图6所示,可以看到,对于带钢的机械性能具有重要影响的参数是x10,x3,x6,x8,x12。
图6
(2)因子分析法
因子分析是一种统计技术,旨在从变量群中提取共性因子。这一方法最早由英国心理学家C.E.斯皮尔曼提出,他通过观察学生各科成绩之间的相关性,推想是否存在某些潜在的共性因子或一般智力条件影响学生的学习成绩。因子分析能够在多个变量中找出隐藏的、具有代表性的因子,将相同本质的变量归入一个因子,从而减少变量的数目,并检验变量间关系的假设。因子分析是简化、分析高维数据的一种有效工具,广泛应用于市场调研、社会科学研究等领域。
因子分析的基本原理是根据变量间的相关性大小将原始变量进行分组,使得同组内的变量之间相关性较高,而不同组的变量间的相关性则较低。每组变量代表一个基本结构,这个基本结构用一个不可观测的综合变量来表示,称为公共因子。因子分析的主要步骤包括:
1)确认数据适用性:通过KMO检验和Bartlett球形检验等方法,确认数据是否适合进行因子分析。
2) 构造因子变量:确定公共因子的个数,通常根据因子的累积方差贡献率来确定,一般取累积贡献率大于85%的特征值所对应的主成分。
3) 因子旋转:为了使因子变量更具有可解释性,通常需要进行因子旋转,如正交旋转或斜交旋转。
4) 计算因子得分:对于每一个样本数据,计算其在不同因子上的具体数据值,即因子得分。
其数学模型为:
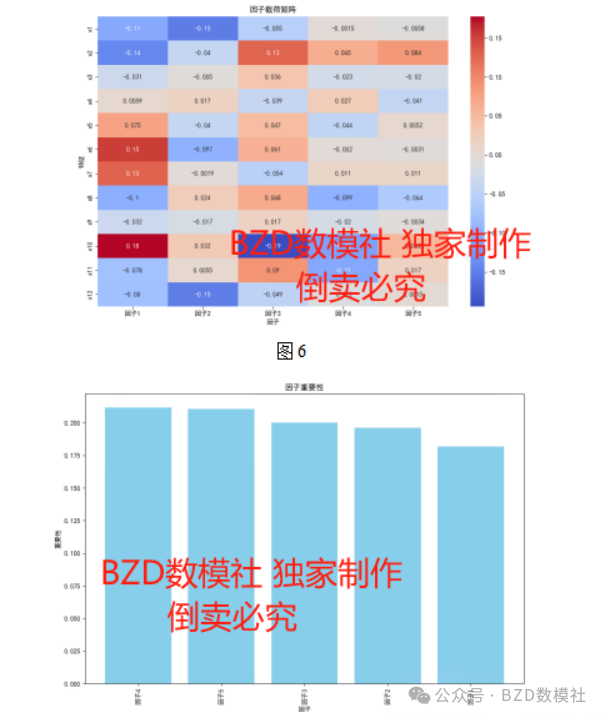
根据因子载荷矩阵图和因子重要性图,可以看出,因子2(Factor 2)对硬度的影响最为显著,其重要性最大,达到0.35左右;因子3(Factor 3)次之,重要性在0.2左右;因子1、因子4和因子5的影响相对较小,但仍然具有一定的解释力。具体来看,带钢厚度(x1)、带钢宽度(x2)、碳含量(x3)等指标在不同因子上的载荷值不同,表明这些指标在不同因子上对硬度的贡献不同。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









