







Go map实现原理 - 恋恋美食的个人空间 - OSCHINA - 中文开源技术交流社区 https://my.oschina.net/renhc/blog/2208417
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
Golang的map使用哈希表作为底层实现,一个哈希表里可以有多个哈希表节点,也即bucket,而每个bucket就保存了map中的一个或一组键值对。
map数据结构由runtime/map.go:hmap定义:
type hmapstruct{
countint//当前保存的元素个数
...
B uint8
...
bucketsunsafe.Pointer// bucket数组指针,数组的大小为2^B
...
}
下图展示一个拥有4个bucket的map:
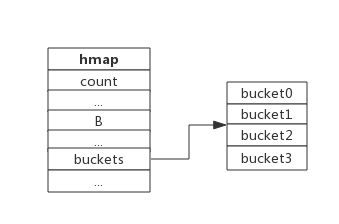
本例中, hmap.B=2, 而hmap.buckets长度是2^B为4. 元素经过哈希运算后会落到某个bucket中进行存储。查找过程类似。
bucket很多时候被翻译为桶,所谓的哈希桶实际上就是bucket。
2. bucket数据结构
bucket数据结构由runtime/map.go:bmap定义:
type bmapstruct{
tophash [8]uint8//存储哈希值的高8位
databyte[1]//key value数据:key/key/key/.../value/value/value...
overflow *bmap//溢出bucket的地址
}
每个bucket可以存储8个键值对。
tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
overflow 指针指向的是下一个bucket&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1293
1293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









