







简介:Lucene Web Service是一个开源项目,它利用Java Servlet技术,通过RESTful接口提供Lucene的全文搜索引擎功能。此项目允许开发者通过HTTP请求操作索引和查询,支持跨平台、跨语言的搜索应用。本项目将详细解析Lucene的核心功能、RESTful API设计、以及如何部署和使用该服务。 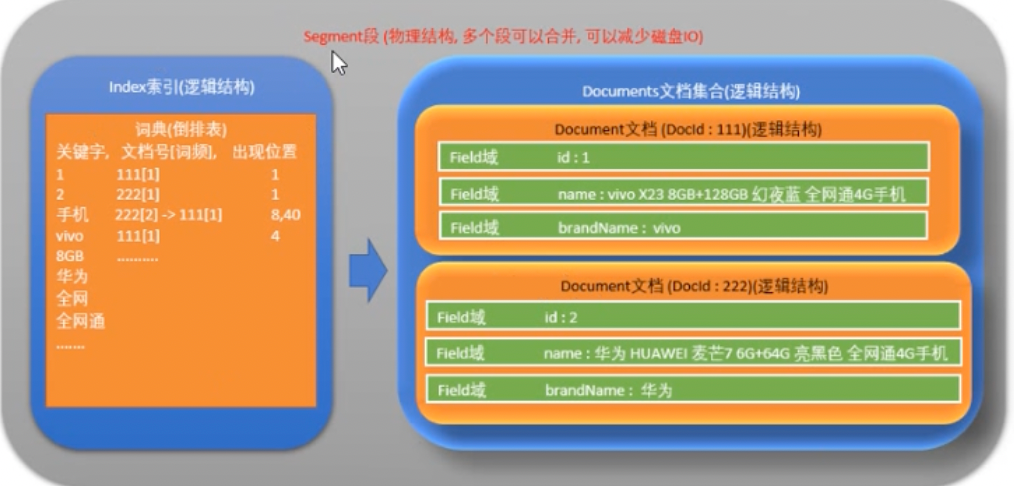
1. Lucene Web Service简介
1.1 Lucene Web Service概述
Lucene Web Service是一种基于Apache Lucene搜索引擎的Web服务,它将强大的搜索引擎功能封装为可通过HTTP协议访问的接口。它的出现使得搜索引擎技术能够更广泛地应用于不同的开发环境中,无论是客户端应用程序还是服务器端应用程序。Lucene Web Service通过RESTful API提供索引创建、查询执行等服务,为开发者提供了一种简洁、高效的数据检索手段。
1.2 Lucene Web Service的用途
作为一种搜索引擎服务,Lucene Web Service广泛应用于内容管理系统(CMS)、企业应用、电子商务平台、网络档案存储以及各种需要搜索功能的应用程序中。它可以帮助开发者快速实现全文搜索、字段搜索、模糊搜索等功能,提高应用程序的数据检索能力和用户体验。
1.3 Lucene Web Service的优势
与传统数据库的全文搜索功能相比,Lucene Web Service具有更高的灵活性和扩展性。它支持多种复杂的搜索算法,如TF-IDF评分机制、倒排索引技术以及多字段搜索等,这使得它在处理大规模数据时表现更为优秀。此外,由于其设计的模块化,Lucene Web Service便于维护和升级,能够快速适应业务变化。
2. Lucene核心功能详解
2.1 全文检索功能
2.1.1 全文检索的基本原理
全文检索是指在大量的文本数据中,快速找到包含一个或多个指定关键词的文档的过程。它的基本原理可以概括为以下几个步骤:
- 文本预处理 :将原始文本进行分词、去除停用词、词干提取等操作,转换为可搜索的索引项。
- 索引构建 :根据预处理后的索引项建立索引,通常采用倒排索引形式存储,记录每个关键词对应出现在哪些文档中。
- 查询处理 :用户输入查询请求,系统同样进行文本预处理,并与索引进行匹配。
- 结果排序 :根据相关性评分对结果进行排序,最终返回给用户。
2.1.2 Lucene中的全文检索实现
Apache Lucene 是一个高效的全文检索库,它在全文检索的各个步骤都有成熟的实现:
- 分词器(Tokenizer) :Lucene 提供了多种语言的分词器,可以将文本转换成词项(Term)。
- 索引构建器(Indexer) :利用倒排索引技术,Lucene 可以高效地建立索引。
- 查询解析器(QueryParser) :能够解析用户的查询请求,转换为 Lucene 可执行的查询对象。
- 评分模型(ScoringModel) :使用 TF-IDF 等算法为搜索结果进行相关性评分,以便于排序。
2.2 倒排索引技术
2.2.1 倒排索引概念解析
倒排索引是全文检索的核心数据结构,其目的是将词项映射到包含它们的文档。在倒排索引中,每个唯一的词项都有一个记录列表,该列表包含了这个词项出现过的所有文档信息。
基本组成要素包括:
- 词典(Dictionary) :存储所有独立的词项。
- ** postings 列表**:每个词项对应一个 postings 列表,记录了这个词项出现的文档列表及在文档中的位置信息。
2.2.2 Lucene倒排索引的应用
Lucene 对倒排索引的应用是高效且灵活的,主要体现在:
- 索引存储 :Lucene 以一种压缩格式存储倒排索引,优化了存储空间。
- 索引更新 :支持实时添加、删除或更新索引项。
- 扩展字段 :支持扩展字段,允许存储更多属性信息,增强检索能力。
- 索引合并 :对多个小索引文件进行合并,优化查询性能。
2.3 多语言分词支持
2.3.1 分词技术概述
分词是将连续的文本流切分成有意义的最小单元(通常是词)。不同语言有不同的分词需求和规则:
- 英文分词 :通常基于空格切分,复杂情况需要使用词干提取等技术。
- 中文分词 :没有明显分隔符,需要根据词典、统计模型等方法进行分词。
2.3.2 Lucene对多语言分词的实现
Lucene 提供了一系列的分词器(Analyzer),包括:
- 标准分析器(StandardAnalyzer) :适用于英文分词。
- 中文分词器(CJKAnalyzer) :专为中文设计,支持中文、日文和韩文。
- 自定义分词器 :可以创建自定义的分词器来适应特殊需求。
2.4 TF-IDF评分机制
2.4.1 TF-IDF评分原理
TF-IDF(Term Frequency-Inverse Document Frequency)是一种统计方法,用于评估一个词在一份文档中的重要程度。其核心思想是:
- 词频(TF) :词在文档中出现的频率越高,表明它可能越重要。
- 逆文档频率(IDF) :一个词在所有文档中出现的频率越低,它对于区分文档就越重要。
评分公式通常表示为: TF-IDF = TF * log(N/DF) ,其中 N 是文档总数, DF 是包含该词的文档数。
2.4.2 Lucene中的TF-IDF评分实践
在 Lucene 中,TF-IDF 评分机制被用于排序搜索结果。Lucene 实现了多种评分模型,开发者可以根据需要选择:
- 默认评分模型 :基于 TF-IDF 算法实现。
- BM25 等高级模型 :为了提高检索效果,提供了其他高级评分模型。
2.5 多字段搜索能力
2.5.1 多字段搜索的理论基础
多字段搜索允许在不同的文档字段中执行查询,并对结果进行组合。这种搜索能力提高了数据检索的灵活性,使得检索更为精确。
其原理是:
- 字段索引 :每个字段可以独立建立索引。
- 查询解析 :对每个字段应用查询语句,并计算各字段的评分。
- 结果合并 :将各字段的评分进行合并,得到最终评分。
2.5.2 在Lucene中实现多字段搜索
Lucene 提供了灵活的多字段搜索实现:
- Field对象 :可以为不同的字段创建Field对象,并为每个字段指定分析器。
- 查询语法 :支持通过语法指定特定字段进行搜索。
- 评分合并 :提供评分合并策略,如最常见的
BooleanClause.Occur.SHOULD,允许在不同字段之间组合结果。
2.6 过滤与排序功能
2.6.1 过滤机制的详细介绍
过滤(Filtering)在 Lucene 中用于对搜索结果进行条件筛选,它不会影响评分,但会影响结果集的大小。
使用场景包括:
- 时间范围筛选 :如仅返回特定时间范围内的文档。
- 状态筛选 :比如仅显示有效或未删除的记录。
2.6.2 排序功能的实现与优化
Lucene 提供了灵活的排序功能,可以根据不同字段进行排序,如按时间、按相关性等。
排序实现要点:
- DocValues :Lucene 中的高效存储结构,用于快速访问排序用的字段值。
- 自定义评分器 :可以通过实现
Similarity接口来自定义文档相关性评分。
// 示例代码:创建一个自定义的评分器
public class CustomSimilarity extends DefaultSimilarity {
@Override
public float tf(float freq) {
return (float) (1.0 + Math.log(freq));
}
@Override
public float idf(long docFreq, long numDocs) {
return (float) (Math.log(numDocs / (double) (docFreq + 1)) + 1.0);
}
}
上述代码示例中,自定义评分器 CustomSimilarity 重写了 tf 和 idf 方法,以调整文档的评分算法。
3. RESTful API设计与应用
3.1 索引管理方法
3.1.1 RESTful API中索引的创建与删除
在使用Lucene Web Service进行全文检索和信息管理时,索引是核心组件。RESTful API允许通过HTTP请求与索引进行交互,其中创建和删除索引是常见的管理任务。创建索引通常使用 PUT 请求,而删除索引则通常使用 DELETE 请求。
创建索引时,需要指定索引名称以及其配置参数,如分词器、存储类型等。以下是一个RESTful API的示例,展示了如何创建一个名为"myindex"的索引:
PUT /myindex
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
在这个例子中,通过发送一个 PUT 请求到 /myindex 路径,定义了一个包含单个分片( number_of_shards )和零个副本( number_of_replicas )的索引配置。如果索引创建成功,服务器会返回状态码 200 OK 。
删除索引的操作也同样简单:
DELETE /myindex
如果索引删除成功,服务器通常会返回状态码 200 OK ,或者在索引不存在的情况下返回 404 Not Found 。
3.1.2 索引的更新与优化策略
索引的更新往往涉及到文档的添加、修改或删除。在RESTful API中,可以使用 POST 、 PUT 和 DELETE 请求来分别处理新增、更新和删除文档的操作。例如,添加一个新的文档到索引中:
POST /myindex/_doc
{
"title": "Lucene Web Service Guide",
"content": "Everything you need to know about Lucene Web Service..."
}
更新操作可以使用 PUT 请求,需要指定文档的ID,如下所示:
PUT /myindex/_doc/1
{
"title": "Updated Guide to Lucene Web Service",
"content": "Updated content with more insights on how to use Lucene Web Service..."
}
删除操作可以使用 DELETE 请求,指定要删除文档的ID:
DELETE /myindex/_doc/1
索引优化对于提高查询性能至关重要。Lucene提供了优化操作,可以通过发送 POST 请求来触发:
POST /myindex/_optimize
这个操作会合并索引段,以减少索引的碎片化并优化搜索效率。优化操作会消耗较多资源,因此应该根据实际需要来计划使用。
3.2 查询执行过程
3.2.1 查询语句的构建与解析
在Lucene Web Service中,通过RESTful API执行查询操作是通过发送 GET 或 POST 请求到 /_search 路径来完成的。查询语句通常是JSON格式的,遵循Elasticsearch的查询DSL(Domain Specific Language)。
构建查询语句时,需要指定查询类型和相关参数。以下是构建一个简单全文匹配查询的示例:
GET /myindex/_search?q=title:Lucene
{
"query": {
"match": {
"title": "Lucene"
}
}
}
在这个例子中, q 参数指定一个简单的查询字符串,而 query 字段则定义了一个详细的JSON格式的查询语句。查询语句中的 match 操作用于在 title 字段中查找包含"Lucene"的文档。
对于更复杂的查询,比如组合查询、范围查询、模糊查询等,可以在 query 字段中嵌套不同的查询类型来实现:
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "Lucene"
}
},
{
"range": {
"date": {
"gte": "2022-01-01",
"lte": "2022-12-31"
}
}
}
]
}
}
}
在这个例子中, bool 查询用于组合多个条件,其中 must 表示必须满足所有列出的条件。
3.2.2 查询的执行流程详解
当执行查询请求时,RESTful API背后的流程是复杂且有序的。查询首先被API端点接收,然后被翻译成对应的Lucene查询操作。服务器将根据提供的参数和索引的数据结构来执行查询,并返回结果。
在执行查询之前,Lucene会分析查询语句,将其转化为倒排索引查询。查询的执行涉及到以下几个主要步骤:
- 语法解析 :将JSON格式的查询语句解析为内部的查询对象结构。
- 查询编译 :将解析后的查询结构转化为查询引擎可以理解的形式。
- 索引搜索 :对倒排索引执行查询操作,定位匹配的文档。
- 文档加载 :获取匹配文档的完整内容(如果需要的话)。
- 评分与排序 :根据评分机制对结果集进行排序,选择出最相关的文档。
- 结果格式化 :将结果数据转化为JSON或XML格式,并返回给客户端。
整个查询过程需要考虑的因素包括缓存策略、并发处理、异常处理等,以确保查询的效率和稳定性。
3.3 结果返回格式(JSON/XML)
3.3.1 JSON与XML数据格式比较
在返回数据时,RESTful API通常支持JSON和XML格式。JSON(JavaScript Object Notation)和XML(Extensible Markup Language)都是可扩展的标记语言,但它们在结构和易用性方面有所不同。
JSON格式以其简洁和易于阅读的特性而被广泛采用。它使用键值对的方式来表示数据结构,这使得它在编程语言中解析和使用时非常直观。以下是JSON格式的一个例子:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "myindex",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"title": "Updated Guide to Lucene Web Service",
"content": "Updated content with more insights on how to use Lucene Web Service..."
}
},
{
"_index": "myindex",
"_type": "_doc",
"_id": "2",
"_score": 0.7,
"_source": {
"title": "Lucene Web Service Guide",
"content": "Everything you need to know about Lucene Web Service..."
}
}
]
}
}
JSON被许多现代Web服务采用,因为它与JavaScript等编程语言的集成性好,并且能够以较少的带宽传输更多的信息。
而XML是一种更为成熟的标记语言,它使用标签来定义对象和数据字段,例如:
<response>
<took>15</took>
<timed_out>false</timed_out>
<shards>
<total>5</total>
<successful>5</successful>
<skipped>0</skipped>
<failed>0</failed>
</shards>
<hits>
<total>
<value>2</value>
<relation>eq</relation>
</total>
<max_score>1.0</max_score>
<hits>
<hit>
<index>myindex</index>
<type>_doc</type>
<id>1</id>
<score>1.0</score>
<source>
<title>Updated Guide to Lucene Web Service</title>
<content>Updated content with more insights on how to use Lucene Web Service...</content>
</source>
</hit>
<hit>
<index>myindex</index>
<type>_doc</type>
<id>2</id>
<score>0.7</score>
<source>
<title>Lucene Web Service Guide</title>
<content>Everything you need to know about Lucene Web Service...</content>
</source>
</hit>
</hits>
</hits>
</response>
XML格式虽然更为冗长,但具有良好的自描述性和可扩展性,适用于需要严格数据结构和文档交换的场合。
3.3.2 Lucene Web Service中结果格式选择与应用
在Lucene Web Service中,结果的格式化是通过请求头中的 Accept 字段来指定的。例如,客户端可以通过发送以下请求来指定返回JSON格式的结果:
GET /myindex/_search
Accept: application/json
返回的响应头中会包含 Content-Type: application/json 以指示内容格式。
对于XML格式,客户端可以这样请求:
GET /myindex/_search
Accept: application/xml
响应头中则会包含 Content-Type: application/xml 。
在实际应用中,选择JSON还是XML取决于客户端应用程序的需求。JSON通常在Web应用和移动应用中更受欢迎,因为它与JavaScript的兼容性好且易于处理。XML则可能在需要结构化程度更高的文档交换中使用,比如企业级应用和数据交换标准中。
在本章节中,我们详细探讨了RESTful API在索引管理方法、查询执行过程以及结果返回格式上的应用和设计原则。RESTful API提供了一种高效、直观的方式来管理和查询索引,而JSON和XML格式的选择取决于应用的具体需求和上下文环境。在下一章,我们将深入探讨Lucene Web Service的优势所在。
4. Lucene Web Service的优势
Lucene Web Service在企业级搜索解决方案中占据了一席之地,这在很大程度上归功于它众多的优势。以下内容将深入探讨Lucene Web Service的易用性、可扩展性、跨语言和平台支持,以及其在自定义搜索和索引策略方面的强大功能。
4.1 易用性与可扩展性
4.1.1 用户体验分析
从用户的角度来看,Lucene Web Service最大的优势之一就是其简洁明了的API设计。开发者可以轻松上手,利用简单的API调用就能完成复杂的搜索任务。为了进一步分析用户体验,我们可以从以下几个方面入手:
- 学习曲线 :Lucene Web Service具有较低的学习曲线。API文档详细,社区活跃,使得即使是初学者也能快速掌握基本操作。
- 界面简洁性 :用户界面简洁,提供了清晰的指引和即时反馈。这种界面设计使得用户在使用过程中能够快速定位问题并作出相应的调整。
- 错误处理 :系统具有良好的错误提示和异常处理机制,使得开发者能够更容易地诊断和修复问题。
4.1.2 Lucene Web Service的模块化设计
Lucene Web Service的另一个显著优势是其高度模块化的架构。通过将不同的功能划分为独立的模块,它为开发者提供了极大的灵活性和自由度。以下是模块化设计的几个关键点:
- 模块化存储 :索引和查询处理被分离为不同的模块,这样的设计不仅提高了可维护性,也便于将来的功能扩展。
- 插件系统 :Lucene Web Service允许开发者通过插件系统来扩展功能,这意味着用户可以添加自定义的解析器、分析器和评分算法等,而不需要修改核心代码。
- 可扩展的接口 :为了支持未来可能出现的搜索需求,Lucene Web Service提供了一套可扩展的接口,使得开发者能够开发新的功能或对现有功能进行改进。
4.2 跨语言与平台支持
4.2.1 跨平台部署与使用
由于Lucene Web Service是基于Java编写的,它能够轻松部署在任何支持Java的平台上。这意味着无论是Windows、Linux还是macOS,Lucene Web Service都能提供一致的服务。它的跨平台特性主要体现在:
- 操作系统兼容性 :Lucene Web Service与多种操作系统兼容,开发人员可以在任何他们熟悉的环境中进行开发和部署。
- 云服务支持 :通过使用Java的特性,Lucene Web Service也支持在各种云平台上运行,包括AWS、Azure和阿里云等。
4.2.2 跨语言应用的实例分析
Lucene Web Service不仅支持多语言,而且还提供了一种机制来处理各种语言的特殊需求,例如对于不同语言的分词器和分析器的支持。以下是一些关于跨语言应用的实例分析:
- 多语言分词 :Lucene Web Service支持多种语言的分词器,如中文、阿拉伯语和俄语等。这意味着它能够处理多种书写系统和语法结构。
- 国际化搜索 :为了实现国际化的搜索功能,Lucene Web Service还支持国际化版本的查询解析和结果展示,允许用户按照自己的语言偏好进行搜索。
4.3 自定义搜索与索引策略
4.3.1 自定义搜索策略的优势
Lucene Web Service的一个显著优势在于其强大的自定义搜索能力。开发者可以根据具体需求设计和实现独特的搜索策略,例如:
- 复杂的查询逻辑 :允许开发者构建复杂的查询,包括布尔运算、通配符查询、范围查询等。
- 相关性排序 :提供多种相关性排序机制,如TF-IDF、BM25、语言模型等,以适应不同场景的需要。
4.3.2 索引策略的个性化定制方法
对于索引策略,Lucene Web Service提供了高级的自定义选项,包括但不限于:
- 索引字段定制 :用户可以自定义哪些字段被索引,以及如何被索引,包括是否进行分词、是否存储原始数据等。
- 索引更新策略 :提供了灵活的索引更新机制,允许实时更新索引,或使用批量索引的策略以提高性能。
为了进一步说明,以下是一个使用Java代码块来展示如何自定义Lucene索引策略的示例:
// 创建一个索引写入器
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_4_10_4, new StandardAnalyzer(Version.LUCENE_4_10_4));
iwc.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND); // 如果索引存在则追加,不存在则创建
IndexWriter writer = new IndexWriter(directory, iwc);
// 定义一个文档并添加到索引中
Document doc = new Document();
doc.add(new TextField("content", "Lucene Web Service索引文档内容", Field.Store.YES));
writer.addDocument(doc);
// 刷新并关闭索引写入器
writer.forceMerge(1); // 强制合并
writer.close();
逻辑分析 :在上面的代码段中,我们首先创建了一个 IndexWriterConfig 对象并配置了相应的分词器和索引模式。接着,我们实例化了一个 IndexWriter 对象,它负责将文档写入索引。然后,我们创建了一个文档对象,并添加了一个类型为 TextField 的字段,这个字段将被索引并存储在索引库中。最后,我们调用了 addDocument 方法将文档添加到索引中,同时使用 forceMerge 方法对索引进行优化,并关闭了索引写入器。
参数说明 : Version.LUCENE_4_10_4 表示我们使用的是Lucene的4.10.4版本。 StandardAnalyzer 是一个用于文本分析的分词器,它将文本分割为一系列的词条,有助于后续的索引和搜索操作。 TextField 是一个字段类型,用于存储文本内容,同时支持全文搜索。 forceMerge 方法是为了将段落进行合并,减少索引数量,提高搜索效率。
通过上面的代码示例,我们可以看到Lucene Web Service在索引策略定制方面的强大功能和灵活性。开发者可以根据具体的应用场景,编写更加复杂的索引创建和管理代码,以满足特定需求。
5. 使用步骤指南
5.1 服务部署流程
5.1.1 环境准备与依赖配置
在开始部署Lucene Web Service之前,需要确保服务器或本地机器上安装了Java开发环境(JDK),并且安装了相关的构建工具,如Maven。以下是部署前的环境准备步骤:
- 安装Java开发工具包(JDK):Lucene Web Service是用Java开发的,因此必须安装JDK。确保安装后JDK环境变量配置正确。
- 安装Maven:通过Maven可以管理项目依赖和构建过程。可以从Maven官网下载安装包或者通过包管理器安装。
- 克隆或下载Lucene Web Service源码:可以通过Git或直接下载源码压缩包到本地。
- 配置项目依赖:在项目根目录下运行
mvn install命令来下载所有必需的依赖项。
5.1.2 部署步骤与常见问题处理
在完成环境准备和依赖配置后,接下来进行部署的具体步骤,以及在此过程中可能会遇到的一些常见问题:
- 部署服务:使用
mvn tomcat7:deploy(假设使用Tomcat作为Web容器)部署服务到服务器上。 - 启动服务:确保Tomcat服务器已经启动,并且Web服务也开始运行。
- 测试服务:可以通过浏览器或者使用curl命令测试服务是否正常运行。
- 处理常见问题:如果遇到端口冲突、权限问题等,需要根据错误信息进行相应的处理。例如,更改端口号或调整文件夹权限。
# 启动Tomcat服务命令示例
./apache-tomcat-9.0.24/bin/startup.sh
# 使用curl测试Lucene Web Service是否部署成功
curl -i ***
5.2 索引创建与维护
5.2.1 索引创建的步骤与技巧
索引是全文检索系统的基础,创建索引的步骤与技巧对于优化搜索性能至关重要。以下是创建索引的步骤:
- 确定需要索引的数据源:可以是文件、数据库表等。
- 编写索引创建脚本:使用Lucene提供的API编写索引脚本,配置好分词器等。
- 执行索引创建:运行脚本,将数据源索引到Lucene的索引库中。
编写索引创建脚本时要注意以下技巧:
- 合理配置分词器 :分词器的选择和配置直接影响到索引的准确性和搜索效果。例如,中文搜索应选择中文分词器。
- 利用过滤器 :为了排除无效数据或重复内容,可以使用过滤器去除停用词或进行文本格式化。
- 增量索引 :对于动态更新的数据源,应该采用增量更新索引的方式,而不是每次都重新创建。
// 简单的Lucene索引创建代码示例
IndexWriter writer = new IndexWriter(FSDirectory.open(new File("indexDir")), new IndexWriterConfig(Version.LATEST, new StandardAnalyzer()));
// 添加文档到索引
Document doc = new Document();
doc.add(new TextField("content", "Lucene is great!", Field.Store.YES));
writer.addDocument(doc);
writer.close();
5.2.2 索引的日常维护与优化
索引创建之后,还需要进行日常的维护和优化工作以确保索引的性能和准确性:
- 监控索引性能:定期检查索引大小、查询响应时间等指标。
- 优化索引结构:随着数据量的增加,可能需要对索引结构进行优化,如合并小段落、更新倒排索引等。
- 清理无效数据:定期清理旧数据或不再相关的文档,以减少索引体积和提高查询效率。
# Lucene提供的命令行工具,用于优化索引
java -cp lucene-core-<version>.jar org.apache.lucene.index.IndexOptimize -i indexDir
5.3 查询执行与结果获取
5.3.1 查询语句的编写与调试
编写查询语句是与用户交互、提供搜索功能的关键步骤。这里有一些编写查询语句的技巧:
- 使用布尔查询 :结合布尔操作符(AND, OR, NOT)来构建更复杂的查询逻辑。
- 利用查询解析器 :Lucene提供了查询解析器,可以将用户输入的自然语言转换为内部的Query对象。
- 调试查询 :在调试查询时,可以使用Lucene提供的调试工具,查看查询的执行计划。
// 示例:使用BooleanQuery组合多个查询条件
BooleanQuery.Builder builder = new BooleanQuery.Builder();
builder.add(new TermQuery(new Term("title", "lucene")), BooleanClause.Occur.SHOULD);
builder.add(new TermQuery(new Term("content", "search")), BooleanClause.Occur.SHOULD);
BooleanQuery query = builder.build();
5.3.2 结果的解析与利用
执行查询后,需要对结果进行解析和利用。以下是结果解析与利用的一些方法:
- 结果排序 :根据特定的评分算法对结果进行排序,如相关度、日期等。
- 结果分页 :对于大量的搜索结果,需要实现分页机制,分批次展示给用户。
- 结果高亮 :对搜索关键词进行高亮显示,以提升用户体验。
- 结果缓存 :对重复查询或高频查询结果进行缓存,以提高响应速度。
// 从索引中搜索并获取结果的示例代码
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(FSDirectory.open(new File("indexDir"))));
TopDocs docs = searcher.search(query, 10); // 查询前10个结果
for (ScoreDoc scoreDoc : docs.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("Document: " + doc);
}
通过以上的步骤和分析,用户可以有效地使用Lucene Web Service进行全文检索服务的部署、索引的创建和维护以及查询的执行和结果的处理。这些操作能够让用户深入理解Lucene Web Service的强大功能和灵活性。
6. 性能优化与监控策略
6.1 索引优化实践
在使用Lucene进行全文检索时,索引优化是一个持续的过程。索引的大小和结构直接影响到查询的响应时间和准确性。以下是一些优化索引性能的实践方法:
- 索引碎片整理 :随着数据的不断更新,索引文件可能会变得分散。定期对索引进行碎片整理,可以减少磁盘I/O,提高查询效率。
// Lucene Java代码示例,用于执行索引合并
Directory directory = FSDirectory.open(new File("path/to/your/index"));
IndexWriterConfig config = new IndexWriterConfig();
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
IndexWriter writer = new IndexWriter(directory, config);
writer.forceMerge(1); // 合并索引段至单个段
writer.close();
-
文档字段存储策略 :并非所有字段都需要被索引,确定字段是否需要存储或仅索引,可以减少索引大小,提高索引效率。
-
索引缓存优化 :合理配置读写缓存的大小,可以减少磁盘I/O操作,提升索引速度。
// Lucene Java代码示例,配置写缓存大小
IndexWriterConfig config = new IndexWriterConfig();
config.setRAMBufferSizeMB(50.0); // 设置写缓存大小为50MB
- 多线程索引 :利用多线程进行索引操作可以充分利用现代多核处理器的能力,加速索引过程。
6.2 查询性能调优
查询性能调优的关键在于理解查询需求,并对索引结构进行适当调整:
- 短语查询优化 :在搜索短语时,可以指定短语搜索的最长距离,减少不必要的计算,提高短语搜索的速度。
// Lucene Java代码示例,进行短语搜索并指定距离
BooleanClause.Occur occur = BooleanClause.Occur.SHOULD;
PhraseQuery.Builder builder = new PhraseQuery.Builder();
// 添加短语查询的词项和距离
builder.add(new Term("field", "word1"));
builder.add(new Term("field", "word2"));
builder.setSlop(2); // 设置短语间最大距离
- 查询缓存 :对于频繁执行的查询,可以开启查询缓存,减少对索引的重复读取。
// Lucene Java代码示例,配置查询缓存
IndexSearcher searcher = new IndexSearcher(directory);
searcher.setQueryCache(new LRUQueryCache());
- 查询剖析 :通过分析查询计划,了解查询的执行过程和性能瓶颈,进行针对性优化。
// Lucene Java代码示例,执行查询并获取查询剖析
Query query = new TermQuery(new Term("field", "query"));
TopDocs results = searcher.search(query, 10);
Explanation explanation = query.explain(searcher, results.scoreDocs[0].doc);
System.out.println(explanation);
6.3 性能监控与日志分析
性能监控对于保持和提升系统性能至关重要。Lucene本身提供了强大的监控能力,可以结合外部工具进行更全面的性能分析:
- 日志记录 :在Lucene中启用详细日志记录,可以监控索引和查询过程中的关键操作。
// Lucene Java代码示例,配置日志记录
IndexWriterConfig config = new IndexWriterConfig();
config.setInfoStream(System.out); // 输出信息到标准输出
IndexWriter writer = new IndexWriter(directory, config);
-
监控工具集成 :集成如Prometheus和Grafana等工具,可以实现对系统性能指标的实时监控。
-
性能指标分析 :定期检查和分析关键性能指标,如索引增长率、平均响应时间等,及时发现和解决问题。
| 性能指标 | 描述 | 监控频率 | | -------------- | ------------------- | -------- | | 索引增长率 | 指标体现索引的增长趋势 | 每日 | | 平均响应时间 | 平均每次查询的响应时间 | 每小时 | | 错误率 | 查询失败的比率 | 每日 | | 索引和查询缓存命中率 | 缓存的有效性 | 每小时 |
- 定期压力测试 :通过模拟高负载的情况,评估系统在极端条件下的性能表现,为优化决策提供数据支持。
通过以上章节的介绍和实践,我们能够对Lucene Web Service的性能优化和监控有一个全面的了解。接下来的内容将讨论如何应用这些优化策略来提高Lucene Web Service的实际运行效率。
简介:Lucene Web Service是一个开源项目,它利用Java Servlet技术,通过RESTful接口提供Lucene的全文搜索引擎功能。此项目允许开发者通过HTTP请求操作索引和查询,支持跨平台、跨语言的搜索应用。本项目将详细解析Lucene的核心功能、RESTful API设计、以及如何部署和使用该服务。















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









