






union-find算法(并查集算法)
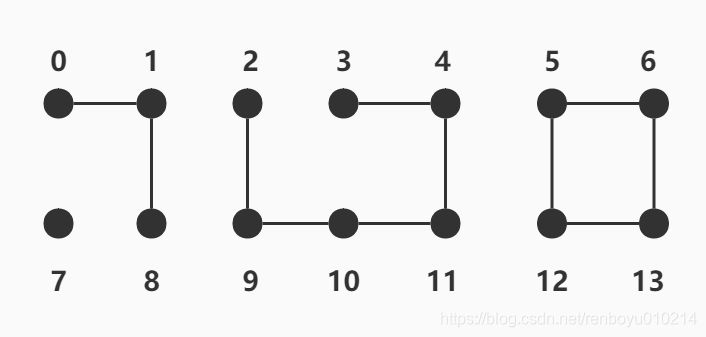
如上图所示就是一组简单的连通性问题
其中0与1是相连的,1与8是相连的,等等
该图一共具有四个等价分量,分别是(0,1,8)(2,3,4,9,10,11)(5,6,12,13)(7)
动态连通性:(即相连的两个节点分别具有的性质)
自反性,P与P是相连的
对称性,若P与Q相连,则Q与P也相连
传递形,P与W相连,W与Q相连,则P与Q也相连
union-find算法简化了对节点本身值的讨论,而更注重于节点之间的联通关系,初始状态下,每个节点在数组中的值都等于各自的索引值,在连接过程中,两个被连接的节点将被赋予相同值,这个值来自于连接的两个节点其中之一
例如:9与10连通,则9与10的值都变为9,后来,2与9连通,2,9,10三个的值均变为2
其本质就是将已经连通的节点归并到同一集合中,所以节点本身的值实际不在考虑范围内,也因此我们无法通过union-find算法求得某两点之间的路径,只能判断这两个点是否连通
union-find算法的API
public class
UnionFind
操作
构造函数
UnionFind(int N)
以整数标识0~N-1,初始化N个触点
void
union(int p,int q)
将p和q两个节点连接
int
find(int p)
返回p在网络中的标识符(值,也就是对应集合)
boolean
connected(int p,int q)
判断p和q两个节点是否相连
int
count()
返回连通分量的数量
union-find算法实现
实现一:quick-find算法
这个算法保证了find方法的高效性,也就是我们前文提到过的忽略每个节点值的意义,一旦连接两个节点,就对两个节点所在的连通分量进行处理,使两个两桶分量的标识符相等(通过遍历整个数组实现)
这虽然保证了find的高效性(只需要遍历一次数组就能得到所在连通分量),但这使union方法无法处理大型数据,因为每连通一次都需要遍历整个数组
package cn.ywrby.UF;
import edu.princeton.cs.algs4.StdIn;
import edu.princeton.cs.algs4.StdOut;
public class UnionFind {
private int[] id; // 存放节点的数组
private int count; // 分量数量
// 初始化类
public UnionFind(int N) {
count = N; // 元素数量
id = new int[N];
for (int i = 0; i < N; i++) {
id[i] = i;
}
}
// 返回当前分量数量
public int count() {
return count;
}
// 判断两个节点是否连通
public boolean connected(int p, int q) {
return id[p] == id[q];
}
// 判断当前节点所处的分量
public int find(int p) {
return id[p];
}
// 对两个节点进行联通
public void union(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID) {
return;
}
for (int i = 0; i < id.length; i++) {
if (id[i] == pID) {
id[i] = qID;
}
}
count--;
}
public static void main(String[] args) {
int N = StdIn.readInt();
UnionFind uf = new UnionFind(N);
while (!StdIn.isEmpty()) {
int p = StdIn.readInt();
int q = StdIn.readInt();
if (uf.connected(p, q))
continue;
uf.union(p, q);
StdOut.println(p + " connected " + q);
}
StdOut.println(uf.count + "components");
// TODO 自动生成的方法存根
}
}
quick-find算法分析:
算法运行过程中,每次调用find算法对数组只进行一次遍历,当调用connected方法时如果两个节点没有连通,则进行的遍历次数在(N+3)~(2N+1)之间。(首先调用两次find,然后再for循环处进行N次遍历,最后如果条件成立id[i]=qID;处进行至少一次,至多N-1次遍历)
分析最坏情况,使用该算法并且最后只剩一个联通变量,则至少进行了N-1次连接操作,所以访问数组次数至少(N+1)*(N+3)~N^2次,该算法为平方级别
实现二:quick-union算法
这个算法实现了高效的union方法,它引用到了最基础的树的概念,通过保存上一个节点的索引,找到根节点,再通过比较根节点,判断两个节点是否同属于一个分量中。
package cn.ywrby.UnionFind;
import edu.princeton.cs.algs4.StdIn;
import edu.princeton.cs.algs4.StdOut;
public class QuickUnion {
private int[] id; // 存放节点的数组
private int count; // 分量数量
// 初始化类
public QuickUnion(int N) {
count = N; // 元素数量
id = new int[N];
for (int i = 0; i < N; i++) {
id[i] = i;
}
}
// 返回当前分量数量
public int count() {
return count;
}
// 判断两个节点是否连通
public boolean connected(int p, int q) {
return id[p] == id[q];
}
// 判断当前节点所处的分量
public int find(int p) {
while(id[p]!=p){
p=id[p];
}
return p;
}
// 对两个节点进行联通
public void union(int p, int q) {
int pRoot=find(p);
int qRoot=find(q);
if(qRoot==pRoot){
return;
}
id[qRoot]=pRoot;
count--;
}
public static void main(String[] args) {
int N = StdIn.readInt();
QuickUnion uf = new QuickUnion(N);
while (!StdIn.isEmpty()) {
int p = StdIn.readInt();
int q = StdIn.readInt();
if (uf.connected(p, q))
continue;
uf.union(p, q);
StdOut.println(p + " connected " + q);
}
StdOut.println(uf.count + "components");
// TODO 自动生成的方法存根
}
}
算法分析
quick-union算法可以看作是对quick-find算法的一次改良,它解决了union方法是平方级别的问题(在quick-union中一般情况下为线性的)。
find方法在最好情况下只需要遍历一次数组(即该节点为根节点时),最坏情况为2N+1次数组(当节点位于最尾端时,while循环遍历数组N+1次,赋值语句遍历数组N次)
同样的,quick-union在最坏情况下(只有一个连通分量时),也是N^2级别的
实现三:加权quick-union算法
quick-union算法出现的主要问题就是树的平衡性,由于没有控制树的生长方式,所以可能造成众多子树线性的连接在一起,增加find成本
通过简单的加权,我们可以控制树的生长,保证始终将小树连接到大树上
package cn.ywrby.UnionFind;
import edu.princeton.cs.algs4.StdIn;
import edu.princeton.cs.algs4.StdOut;
public class WeightedQuickUnion
{
private int[] id; // 存放节点的数组
private int[] sz; //存放各个节点所在分量的根节点数目
private int count; // 分量数量
// 初始化类
public WeightedQuickUnion(int N) {
count = N; // 元素数量
id = new int[N];
for (int i = 0; i < N; i++) {
id[i] = i;
}
sz=new int[N];
for(int i=0;i
sz[i]=1; //初始化每个分量的数量
}
}
// 返回当前分量数量
public int count() {
return count;
}
// 判断两个节点是否连通
public boolean connected(int p, int q) {
return id[p] == id[q];
}
// 判断当前节点所处的分量
public int find(int p) {
while(id[p]!=p){
p=id[p];
}
return p;
}
// 对两个节点进行联通
public void union(int p, int q) {
int pRoot=find(p);
int qRoot=find(q);
if(qRoot==pRoot){
return;
}
//比较节点对应分量的大小,再进行合并
if(sz[pRoot]
id[pRoot]=qRoot;
sz[qRoot]+=sz[pRoot]; //修改该分量元素数目
}
else{
id[qRoot]=pRoot;
sz[pRoot]+=sz[qRoot];
}
count--;
}
public static void main(String[] args) {
int N = StdIn.readInt();
WeightedQuickUnion uf = new WeightedQuickUnion(N);
while (!StdIn.isEmpty()) {
int p = StdIn.readInt();
int q = StdIn.readInt();
if (uf.connected(p, q))
continue;
uf.union(p, q);
StdOut.println(p + " connected " + q);
}
StdOut.println(uf.count + "components");
}
}
算法分析:
根据算法特性不难发现,加权后形成的树最大深度不会超过lgN。所以find,union的成本增长数量级为lgN。这是目前为止最优的算法
三种算法运行过程中遍历数组次数比较
public class AnalysisChart {
public static void main(String[] args) {
int N = 5000;
QuickUnion qu = new QuickUnion(N);
VisualAccumulator accumulator=new VisualAccumulator(N,2*N+1);
StopWatch watch=new StopWatch();
for(int i=0;i
Random r =new Random();
int p=r.nextInt(N);
int q=r.nextInt(N);
if (qu.connected(p, q)) {continue;}
qu.union(p, q);
accumulator.addDataValue(qu.NUM);
qu.NUM=0;
StdOut.println(p+" connected "+q);
}
double time=watch.elapsedTime();
StdOut.println(qu.count() + "components");
StdOut.println("time = " + (time));
}
}
quick-find算法
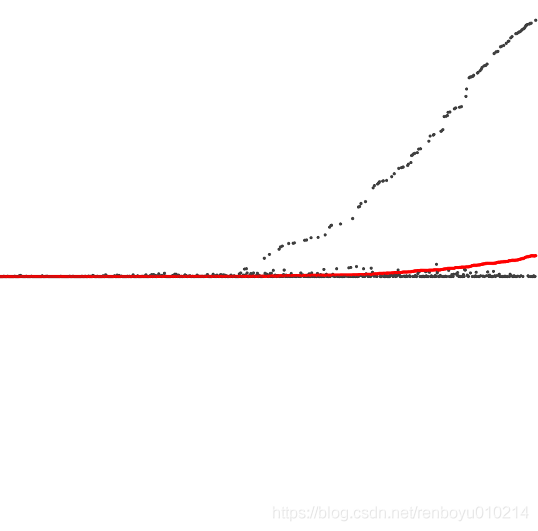
quick-uniob算法

加权的quick-union算法
















 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









