







@[TOC](并查集(Union Find)快速入门)
1. 需求分析
假设有n个村庄,有些村庄之间有连接的路,有些村庄之间并没有连接的路。设计一个数据结构,能够快速执行2个操作:
- 查询2个村庄之间是否有连接的路
- 连接2个村庄

那么就要用到一个用于表示集合间元素关系的数据结构 ----- 并查集,其能够办到查询、连接的均摊时间复杂度都是O (α(n)) ,α (n) < 5
2. 定义
在计算机科学中,并查集是一种树型的数据结构,用于处理一些不交集(Disjoint Sets)的合并及查询问题
并查集有2个核心操作
- 查找(Find):查找元素所在的集合(这里的集合并不是特指Set这种数据结构,是指广义的数据集合)
- 合并(Union):将两个元素所在的集合合并为一个集合
有2种常见的实现思路
- Quick Find
✓ 查找(Find)的时间复杂度:O(1)
✓ 合并(Union)的时间复杂度:O(n) - Quick Union
✓ 查找(Find)的时间复杂度:O(logn),可以优化至 O( 𝛼 (𝑛)) ,α(𝑛) < 5
✓ 合并(Union)的时间复杂度:O(logn),可以优化至 O( 𝛼 (𝑛)) ,α(𝑛) < 5
3. 存储数据
假设并查集处理的数据都是整型,那么可以用整型数组来存储数据,如下图:
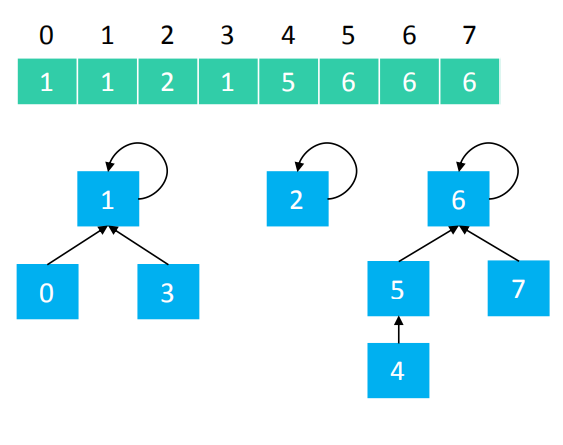
其中0、1、3 属于同一集合, 2 单独属于一个集合, 4、5、6、7 属于同一集合
4. API设计

设计一个抽象类,定义一个整型数组,作为基本数据结构来存放这些数据,然后定义基本的操作,如find(int),union(int,int)让子类主要去实现它们。
初始化时,每个元素各自属于一个单元素集合

public abstract class UnionFind {
protected int[] parents;
public UnionFind(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("capacity must be >= 1");
}
parents = new int[capacity];
for (int i = 0; i < parents.length; i++) {
parents[i] = i;
}
}
/**
* 查找v所属的集合(根节点)
* @param v
* @return
*/
public abstract int find(int v);
/**
* 合并v1、v2所在的集合
*/
public abstract void union(int v1, int v2);
/**
* 检查v1、v2是否属于同一个集合
*/
public boolean isSame(int v1, int v2) {
return find(v1) == find(v2);
}
protected void rangeCheck(int v) {
if (v < 0 || v >= parents.length) {
throw new IllegalArgumentException("v is out of bounds");
}
}
}
5.quick-find算法
分析
Quick Find 的 union(v1, v2) :让 v1 所在集合的所有元素都指向 v2 的根节点。我们举一个下面的例子:
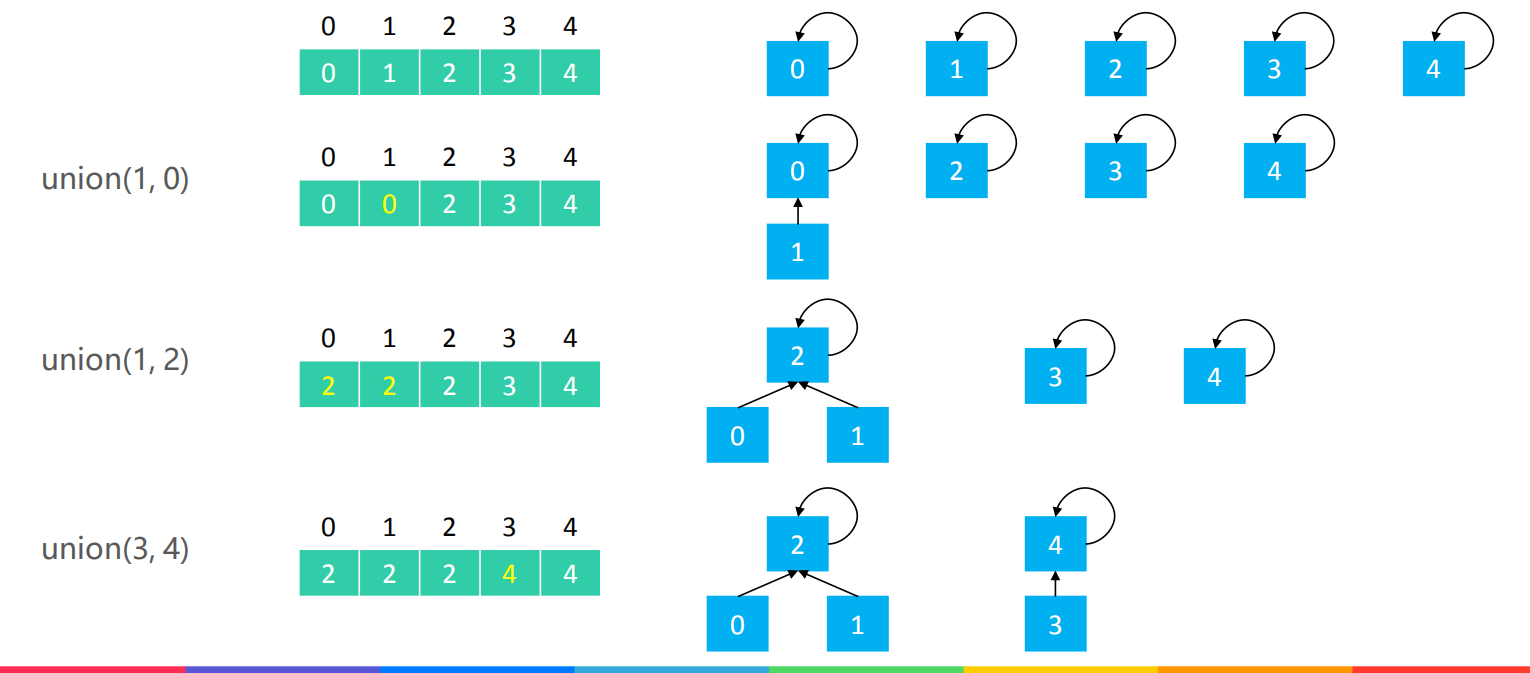
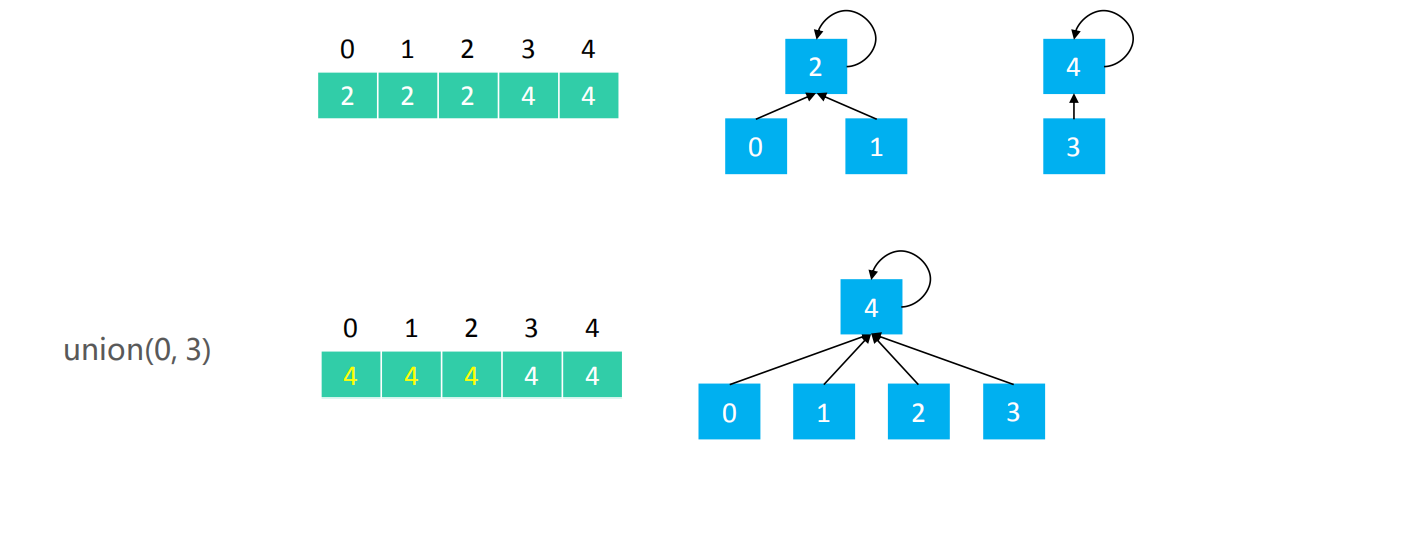
上面这些操作保证了parents[v1]=parent[v2]时v1和v2是连通的,也就是说要想在同一个集合,那么parents数组里面的值就一定相同。
就比如union(1,0),它意思也就是把1所在集合的所有元素都指向0的根节点,现在1和0都是根节点,只需要让1指向0就可以了,把parents[1]的值改为parents[0]的值。
再比如union(0,3),此时就是把0所在集合的所有元素都指向3的根节点4,只需要把0所在集合{0,1,2}的parents值改为4的parents值4就好了。
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if (p1 == p2) return;
for (int i = 0; i < parents.length; i++) {
if (parents[i] == p1) {
parents[i] = p2;
}
}
}
Quick Find 的 find(v)比较简单,从下面代码可以看出,find(v)的时间复杂度是O(1)。
/*
* 父节点就是根节点
*/
public int find(int v) {
rangeCheck(v);
return parents[v];
}
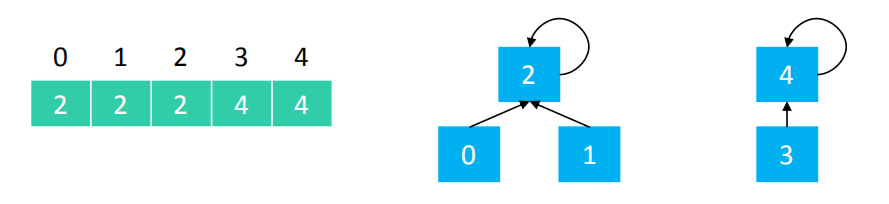
就看上面这张图: find(0) == 2 ,find(1) == 2 , find(2) == 2 , find(3) == 4
6.quick-union算法
6.1分析
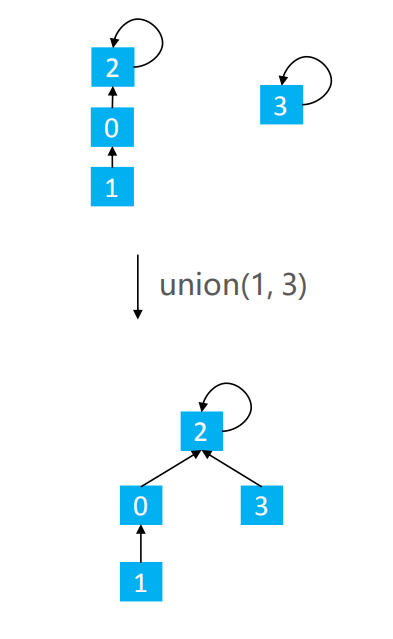
Quick Union 的 union(v1, v2) :让 v1 的根节点指向 v2 的根节点,我们举一个下面的例子:
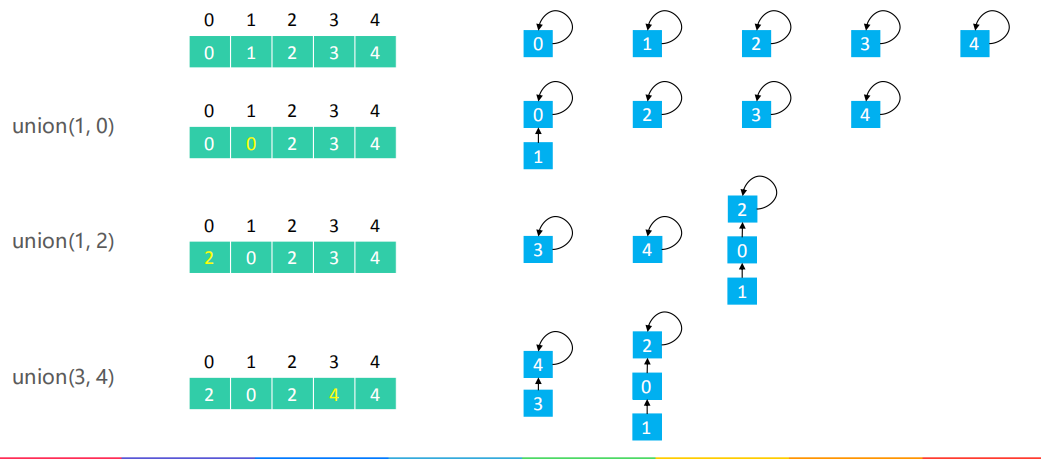
从上面这些操作可以看出,我们分别找到v1,v2的根节点,再将v1的根节点连接到v2的根节点即可。
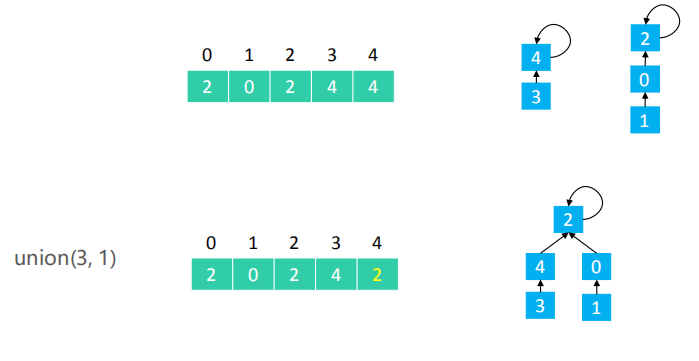
比如union(3,1),先找到3的根节点4,再找到1的根节点2,接着把3的根节点4连接到1的根节点2上就可以了,也只需要把4的parents值改为和2的parents值相等。
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if (p1 == p2) return;
parents[p1] = p2;
}
Quick Union 的 find(v) :通过parent链条不断地向上找,直到找到根节点
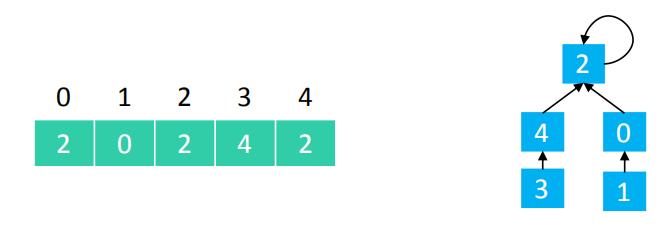
public int find(int v) {
rangeCheck(v);
while (v != parents[v]) {
v = parents[v];
}
return v;
}
比如上图,find(0) == 2, find(1) == 2, find(3) == 2, find(2) == 2
6.2问题
在Union的过程中,可能会出现树不平衡的情况。如下图
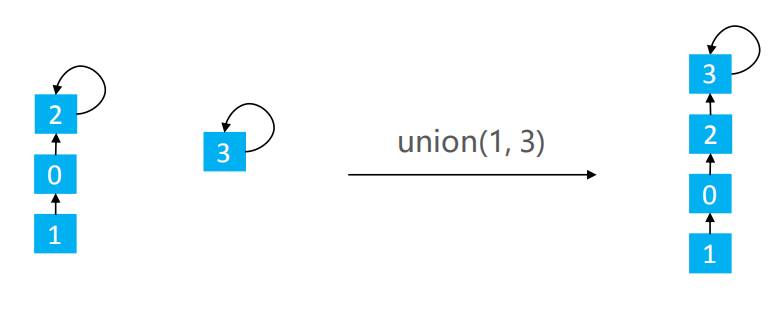
有2种常见的优化方案
- 基于size的优化:元素少的树 嫁接到 元素多的树
- 基于rank的优化:矮的树 嫁接到 高的树
7. Quick Union – 基于size的优化
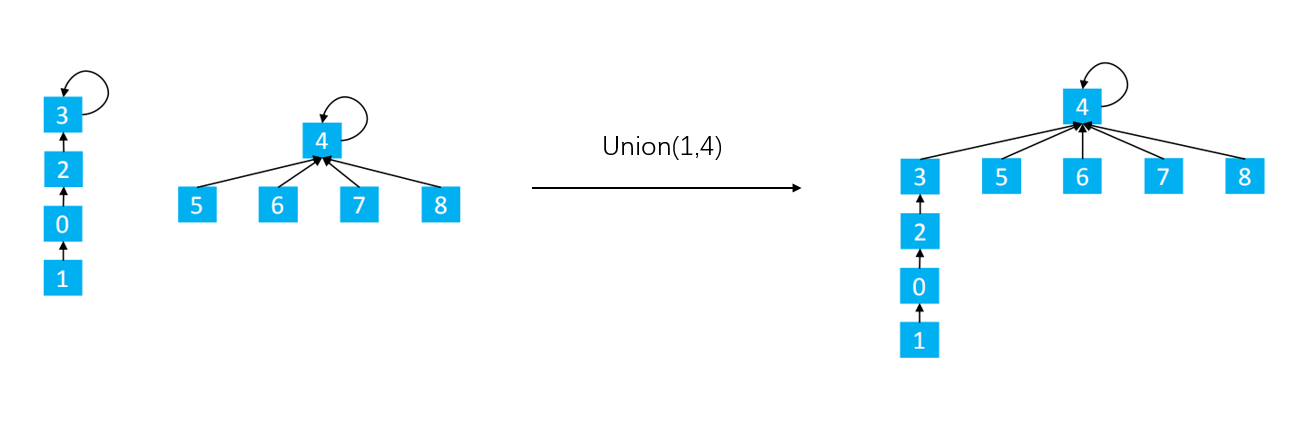
7.1分析
我们现在会记录每一棵树的大小并总是将较小的树连接到较大的树上。
public class UnionFind_QU_S extends UnionFind_QU {
//各个根节点所对应的分量的大小
private int[] sizes;
public UnionFind_QU_S(int capacity) {
super(capacity);
sizes = new int[capacity];
for (int i = 0; i < sizes.length; i++) {
sizes[i] = 1;//size大小初始化为1
}
}
/**
* 将v1的根节点嫁接到v2的根节点上
*/
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if (p1 == p2) return;
// 将小树的根节点连接到大树的根节点
if (sizes[p1] < sizes[p2]) {
parents[p1] = p2;
sizes[p2] += sizes[p1];
} else {
parents[p2] = p1;
sizes[p1] += sizes[p2];
}
}
}
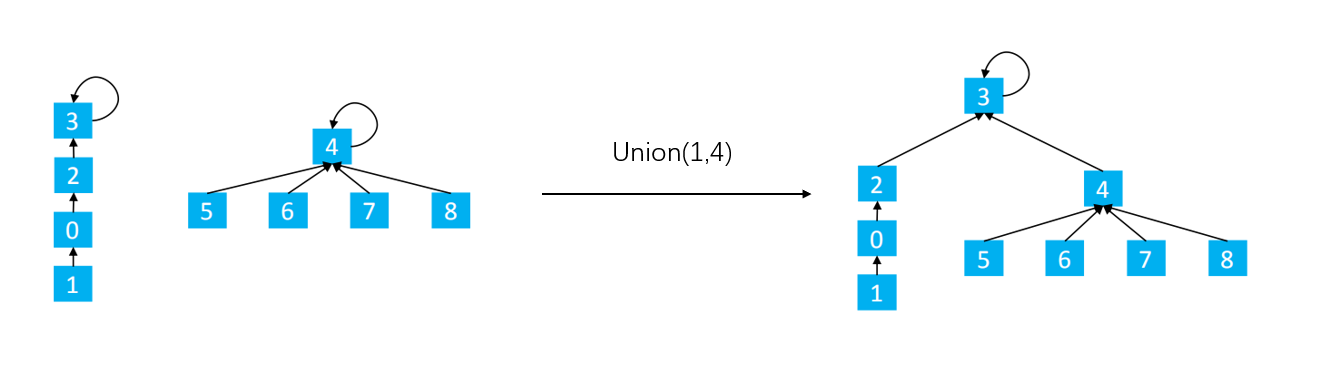
7.2问题
基于size的优化,也可能会存在树不平衡的问题,因为size小,高度并不一定小,更准确的是比较集合的层数来判断谁指向谁,这样最后合并出来的集合的层数能够竟可能的压缩至最小,因此执行find操作的效率将大大提高。在集合中,层数越少,对于每一个节点平均来说,找到根节点所需要查找的次数就会越小。
8.Quick Union – 基于rank的优化
8.1分析
合并后集合层数唯一会变的情况,就是两个集合的层数一模一样时。假设两个集合都只有一个元素,那么这两个集合的层数都为一层,层数相同时,此时谁的根节点的父亲节点指向另一个根节点都无所谓了,但是这样合并后的集合层数要比原来多了一层,其中rank可以理解为树高。
public class UnionFind_QU_R extends UnionFind_QU {
private int[] ranks;
public UnionFind_QU_R(int capacity) {
super(capacity);
ranks = new int[capacity];
for (int i = 0; i < ranks.length; i++) {
ranks[i] = 1;
}
}
public void union(int v1, int v2) {
int p1 = find(v1);
int p2 = find(v2);
if (p1 == p2) return;
if (ranks[p1] < ranks[p2]) {
parents[p1] = p2;
} else if (ranks[p1] > ranks[p2]) {
parents[p2] = p1;
} else {
parents[p1] = p2;
//层数相同,rank变化
ranks[p2] += 1;
}
}
}















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











