






原文:
Label-Specific Document Representation for Multi-Label Text Classification(EMNLP 2019)
多标签文本分类
摘要:
本文使用标签相关的注意力网络学习文档表示。
该方法在构建文档表示时使用了标签的语义信息来决定标签和文档的语义联系。
并且,根据文档内容信息,使用了自注意力机制识别标签特定的文档表示。
为了整合以上两部分,使用了自适应的融合机制,这样可以输出全面的文档表示。
1 Introduction:
类似CNN、RNN、注意力机制的方法已经很好的实现了文档的表示。但是其中的大多数方法仅仅关注文档而忽略了标签。
近期的一些工作通过探索标签结构或标签内容捕获标签相关性。尽管其已经取得了一些成果,但是这些方法无法在标签文本有巨大差异的情况下,取得好的效果。
比如Management vs Management moves,就很难区分。
2 Label-Specific Attention Network model (LSAN)
模型包含两部分。第一部分通过利用文档内容和标签文本,从每一个文档中,捕获标签相关的部分。第二部分旨在从两个方面自适应的提取正确的信息。最终,分类器基于融合的标签特定的文档表示。
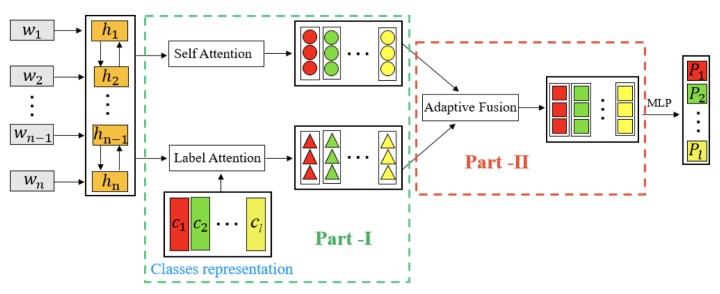
2.1 Input Text Representation:
使用Bi-LSTM捕获双向的语义信息,从而学习每一个输入文档的word embedding。
在第p个时间步,隐藏状态可以被更新。
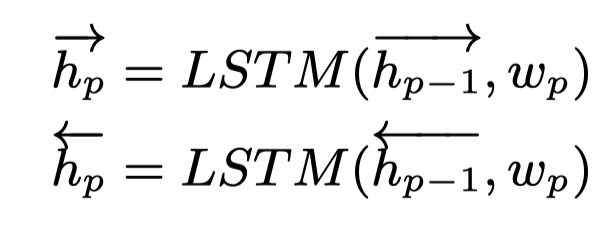
是第p个单词的embedding向量,是其相应的正向/反向词表示。从而,整个文档可以被表示为:

2.2 Label-Specific Attention Network
这一部分旨在于获取每个文档的标签相关的内容。这种策略受启发于文本分类。
例子:
June a Friday, in the lawn, a war between the young boys of the football game start.
属于类别youth和sports。内容young boys与youth更相关而不是sports。而football game直接与sports相关。
2.2.1 Self-attention Mechanism
一篇文档中的每一个单词对每一个标签的贡献程度不同。为了捕获文档与每个标签的相关性,本文采取自注意力机制。标签-单词注意力分数可以通过以下公式获得:
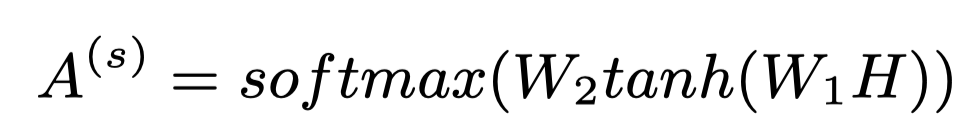
是自注意力参数。代表着所有词对第j个标签的贡献度。
接下来,可以获取文本单词对每一个标签的加权和:
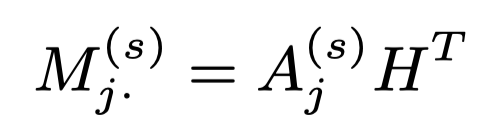
是输入文档结合第j个标签的表示。就是标签特定的文档表示,
2.2.2 Label-Attention Mechanism
刚刚的自注意力部分可以看作是基于内容的注意力机制,只考虑到了文档内容信息。
然而,标签在文本分类中具有特定的语义信息。为了利用到标签的语义信息,他们被预处理和表示为一个可训练的矩阵,在同一个潜在的k维空间:
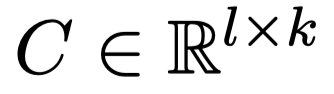
一旦得到Bi-LSTM输出的word embedding,以及标签embedding C,我们可以显式的得到每一对单词和标签的语义联系。一个简单的方法是计算词表示和标签表示的点积:
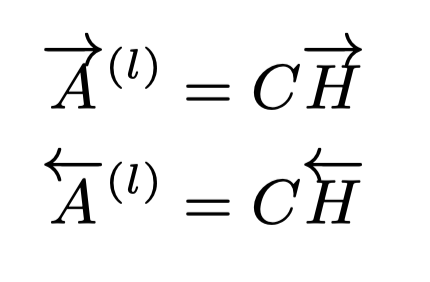
以上两者分别是词和标签正向和反向的语义联系。与刚刚的自注意力机制类似,标签特定的文档表示可以通过标签词的线性组合被构建:
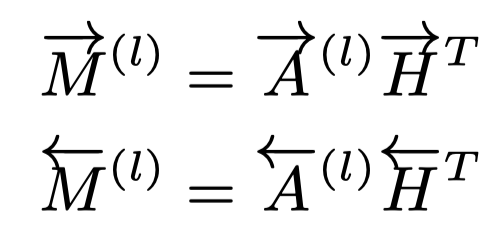
最后,文档可以被重表示:

这一部分的表示是基于标签文本,所以我们将其命名为标签注意力机制。
2.3 Adaptive Attention Fusion Strategy
为了对以上两者(基于内容的注意力机制,基于标签的注意力机制)结合,在这一部分我们探究使用了注意力融合机制,自适应的从以上两部分中提取正确的信息,并建立更全面的文档表示。
具体来讲,两个权重向量用于得到以上两部分文档表示的重要程度,可以通过一个全连接层得到:
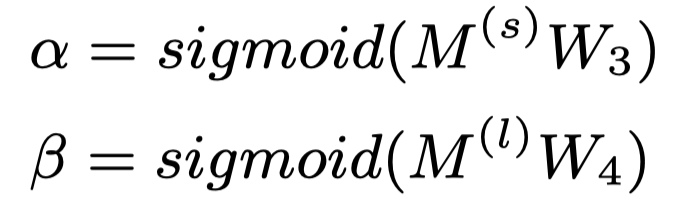
两个W是参数。分别是自注意力机制和标签注意力机制的重要程度(沿着第j个标签)。所以为这两对参数添加限制:
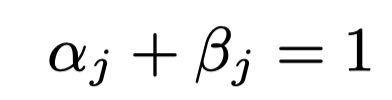
得到最终的文档表示:
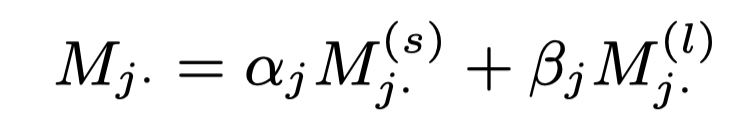
2.4 Label Prediction
在得到最终的文档表示后,我们可以通过含两个全连接层的多层感知机建立一个多标签文本分类器。每个标签的预测概率可以通过如下公式得到:
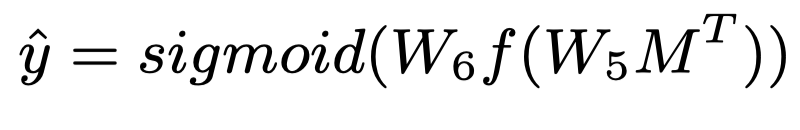
Sigmoid输出的值可以看作概率,所以我们最后使用交叉熵损失。
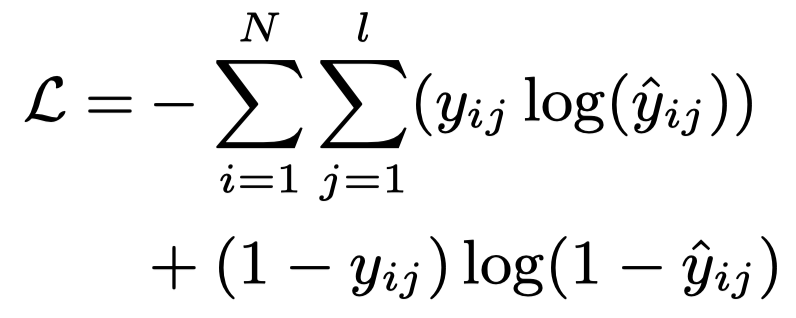
N是训练集文档数目,是标签数量,是零一变量,代表文档是否有标签。
3 Experiments
Datasets:
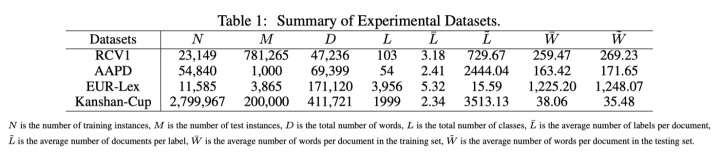
不同数据集的标签数量L有多有少。
Baseline Models:
一些经典的文本多标签分类方法:XML-CNN: (Liu et al., 2017),SGM: (Yang et al., 2018),DXML: (Zhang et al., 2018)。
AttentionXML: (You et al., 2018) 可以看作本文模型的特殊情况,即只考虑到了文本内容,没有考虑到标签语义。
EXAM: (Du et al., 2018) 与本文模型最接近的工作,但是本文模型处理的更好。
3.2 Comparison Results and Discussion
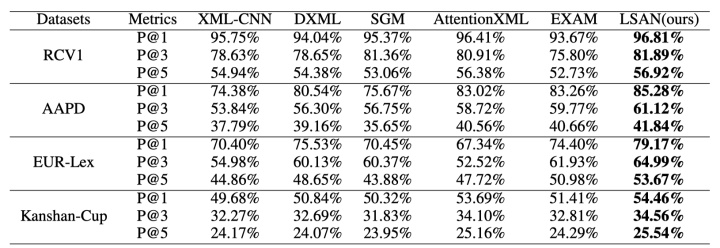
XML-CNN的效果最差,原因是其没有考虑到标签相关性。
在RCV1和Kanshan-Cup数据集上,AttentionXML比EXAM效果好。因为这两个数据集具有层级标签结构。此时父标签和子标签可能包含相同的文本内容,使得其更难区分。
在EUR-Lex数据集上,AttentionXML效果最差,因为其只关注文档内容信息,EXAM和LSAN都受益于标签文本信息,所以效果更好。
3.3 Comparison on Sparse Data
为了验证本文方法LSAN在低频标签上的效果,我们将EUR-Lex根据频率划分为三个组。

三个方法在三个组上的效果:
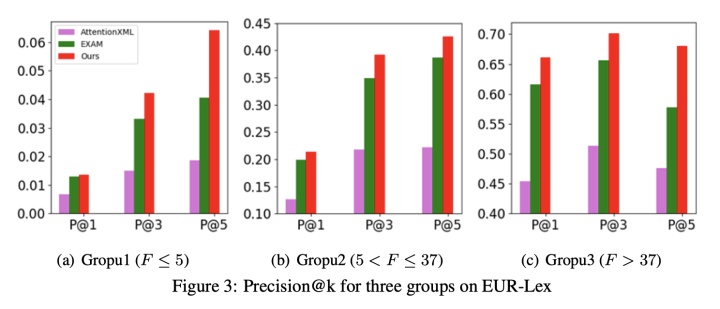
特别是在低频标签上,本文提出的方法获得了更大的提升。
3.4 Ablation Test
文本提出的LSAN方法可以看作是三部分的结合:自注意力部分(A),标签注意力部分(L)和融合注意力部分(W)。

自注意力部分A用来找到有用的文档内容,标签注意力部分L利用到了标签文本信息显式得得到了文档和标签的语义联系。然而,有些标签不易被区分(e.g., Management vs. Management movies).,所以结合两者也很重要。
注意力权重展示:
为了进一步展示融合注意力机制的重要性,展示自注意力和标签注意力在两个数据集上的权重分布。其中EUR-Lex数据比较稀疏,AAPD不稀疏。
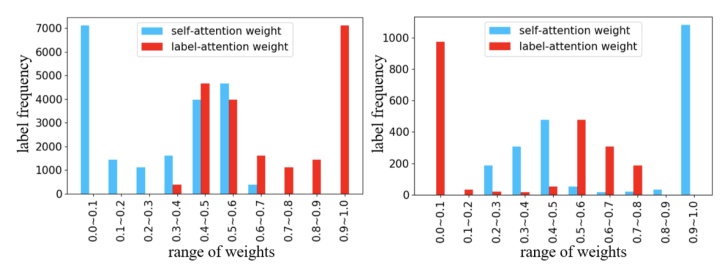
正如我们预料的,在稀疏数据集上,标签注意力机制比自注意力机制更有效。在不稀疏的数据集上,每个标签有充分的文档,所以自注意力机制就够了。
可视化:
探究标签注意力机制的效果。Computer Vision和Neural and Evolutionary Computing是该例子的两个类别,我们可以看出其各自在文本中对应的单词。

启发:
注意力机制可以拿来进行自适应学习,学习两部分的动态加权。但是需要两部分都有好的性能才能取得更好的效果。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









