







0. 背景
主要是参考网上资源针对多标签分类大概描述,主要是数据集评估方法, 网上开源代码阅读, 多标签分类主要问题描述
1. 多标签分类
- 多标签学习[MLL]由一个样例和一个集合标签组成。
- 任务分解: MLL包括主要任务: 多标签分类(MLC)和标签排序(LR)
- 阈值校准: 设定排序的阈值
- 任务 特点:
(1)不同数据集多标签程度不同。-
衡量多标签程度自然方式: 即样本平均标签数。
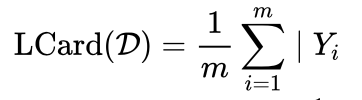
-
标签密度用标签集大小来规范化标签基数
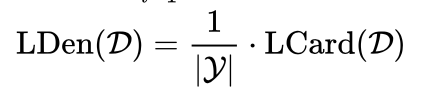
-
标签多样性: 数据集中不同标签集合的数量,可以用数据及大小规范化。
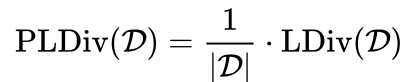
(2)标签具有相互关系
-
- 多标签数据集中学习的关键挑战在于难以控制巨型输出空间,即标签集合的数量随着类别数量指数及增长,因此利用好标签之间的相互关系是必要。
- 一阶策略: 即将多标签学习分解为若干个独立的二分类问题。简单,效率高,但有效性可能不是最好的。
- 二阶策略:标签之间的成对关系来处理。比如在相关和不相关标签之间排序,任意连个标签之间互动。
- 高阶策略: 考虑标签之间的高阶关系,将所有标签影响施加到每个标签上。可扩展性地。
2. 数据不平衡
- 某个类别的对应的样例可能远多与另一个类别,类别之间不平衡。
- 某个类别对应的正样本可能远多于负样本,类别只内不平衡。
- 另一方面: 从标签结合角度,有的标签结合的样本相对多,有的相对少。
3. 评估指标:
- 基于样例的指标: 预测标签集和真实标签集完全一样的比例,当标签空间较大时,指标过于严苛。
- 基于标签的指标:F score
4. 学习算法
- 问题转化:问题适应算法
- 算法改变方法: 算法适应问题。
5. 主要方法:
- sigmoid激活函数+binary_crossentropy(NCE loss)

- 将softmax 延伸到多标签分类上面,
苏神单标签到多标签延伸证明 https://kexue.fm/archives/7359
6. 多标签分类开源代码学习
源码: https://github.com/hellonlp/classifier_multi_label
- 通过aibert进行模型初始化。
- aibert输出进行pooling,
- 接mlp层,shape转为 (*, tag_size)
- 接sigmod 函数, 取概率>=0.5作为该内容的标签。
tf.nn.sigmoid_cross_entropy_with_logits测量离散分类任务中的概率误差,其中每个类是独立的而不是互斥的。这适用于多标签分类问题。
tf.nn.softmax_cross_entropy_with_logits测量离散分类任务中的概率误差,其中类之间是互斥的(每个条目恰好在一个类中)。这适用多分类问题。
在简单的二进制分类中,sigmoid和softmax没有太大的区别,但是在多分类的情况下,sigmoid允许处理非独占标签(也称为多标签),而softmax处理独占类。
sigmod 的输出shape与y shape一样, 输出的每一位与y中的每一位做交叉熵,然后取概率值 >0.5的值。默认y的shape为[1, tag_size], tag_size为候选tag的数目。
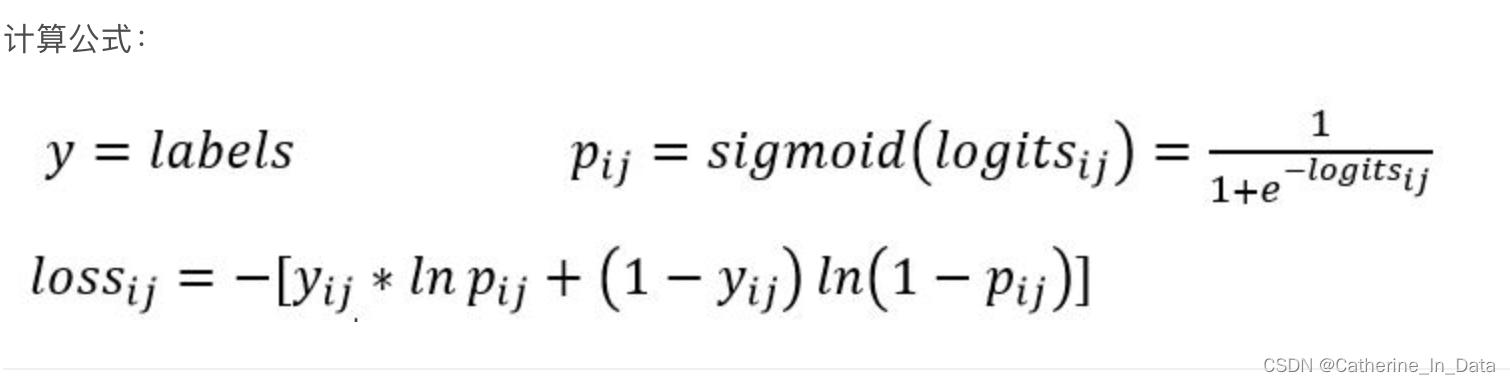
softmax 的输出shape 为[,1]
7. 多标签分类label 不平衡
- 何恺明大神的 Focal Loss
Focal Loss 就是一个解决分类问题中类别不平衡、分类难度差异的一个 loss

当实际y=1, 模型预测的y值越小,则当前样本影响越大。
当实际y=0, 模型预测的y值越大, 则当前样本影响越大。
主要目的: 提高难分样本的loss, 降低容易分样本的loss

-
ASL :
正样本loss 与负样本损失loss 进行隔离。
Asymmetric Loss For Multi-Label Classification)
https://www.cxyzjd.com/article/u010626747/113241655 —code -
few shot
few-shot 的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共 CK 个数据),构建一个 meta-task,作为模型的支撑集(support set)输入;再从这 C 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set)。即要求模型从 C*K 个数据中学会如何区分这 C 个类别,这样的任务被称为 C-way K-shot 问题
参考:https://baijiahao.baidu.com/s?id=1629626559555746572&wfr=spider&for=pc
参考文献
https://cloud.tencent.com/developer/article/1449734
https://github.com/javaidnabi31/Multi-Label-Text-classification-Using-BERT/blob/master/multi-label-classification-bert.ipynb
https://colab.research.google.com/github/rap12391/transformers_multilabel_toxic/blob/master/toxic_multilabel.ipynb#scrollTo=uDLZmEC_oKo3
多标签label不均衡
https://nextstart.online/2021/05/30/ASL/(Asymmetric Loss For Multi-Label Classification)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









