







[ID3算法是J. RossQuinlan在1975提出的分类预测算法,当时还没有数据挖掘吧,哈哈哈。该算法的核心是“信息熵”,属于数学问题,我也是从这里起发现数据挖掘最底层最根本的
0 引言
决策树的目的在于构造一颗树像下面这样的树。
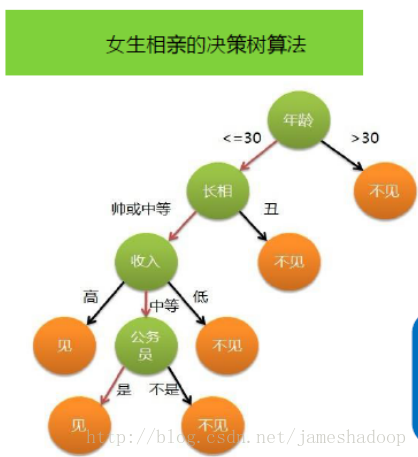
图1
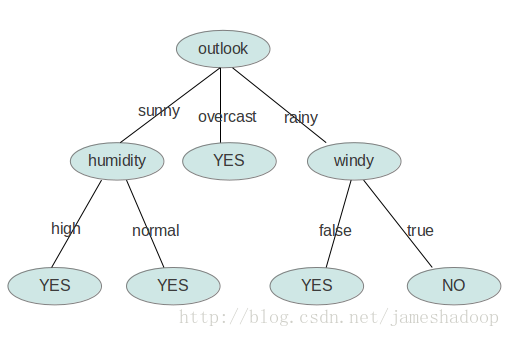
图2
1. 如何构造呢?
1.1 参考资料。 本例以图2为例,并参考了以下资料。 (1)
http://www.cnblogs.com/zhangchaoyang/articles/2196631.html
写的东西非常经典。 (2)
http://blog.sina.com.cn/s/blog_67bc5aa60100qays.html
(3)机器学习(Tom.Mitchell著) 第三章 决策树,里面详细介绍了信息增益的计算,和熵的计算。建议大家参考
1.2 数据集(训练数据集)
outlook
temperature
humidity
windy
play sunny hot high FALSE no sunny hot high TRUE no overcast hot high FALSE yes rainy mild high FALSE yes rainy cool normal FALSE yes rainy cool normal TRUE no overcast cool normal TRUE yes sunny mild high FALSE no sunny cool normal FALSE yes rainy mild normal FALSE yes sunny mild normal TRUE yes overcast mild high TRUE yes overcast hot normal FALSE yes rainy mild high TRUE no
1.3 构造原则—选信息增益最大的 从图中知,一共有四个属性,outlook temperature humidity windy,首先选哪一个作为树的第一个节点呢。答案是选信息增益越大的作为开始的节点。信息增益的计算公式如下:
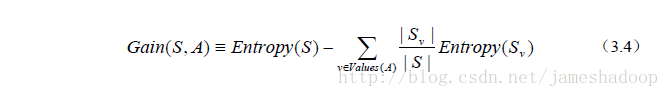 Entropy(s)是熵,S样本集,Sv是子集。熵的计算公式如下:
Entropy(s)是熵,S样本集,Sv是子集。熵的计算公式如下:
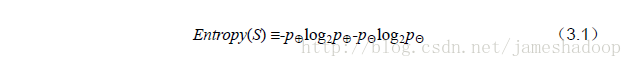 举例: 根据以上的数据,我们只知道新的一天打球的概率是9/14,不打的概率是5/14。此时的熵为
举例: 根据以上的数据,我们只知道新的一天打球的概率是9/14,不打的概率是5/14。此时的熵为

对每项指标分别统计:在不同的取值下打球和不打球的次数。
table 2
outlook
temperature
humidity
windy
play yes no yes no yes no yes no yes no sunny 2 3 hot 2 2 high 3 4 FALSE 6 2 9 5 overcast 4 0 mild 4 2 normal 6 1 TRUR 3 3 rainy 3 2 cool 3 1
下面我们计算当已知变量outlook的值时,信息熵为多少。[所谓决策树就是用树来帮助我们做决策,从树的根节点开始一级一级的访问节点,直到叶子节点,也就完成了决策的过程。决策树算法是描述用已知的样本来构建决策树的过程,这
outlook
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1758
1758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









