





这里提出了一种称为散射视觉Transformer(SVT),SVT包含一个光谱散射网络,可以捕获复杂的图像细节。SVT通过分离低频和高频分量克服了与下采样操作相关的可逆性问题,并引入了一种独特的频谱门控网络,利用爱因斯坦乘法进行token和信道混合,有效降低了复杂度。微软提出散射视觉Transformer全新backbone,性能表现出色!
文章地址:https://badripatro.github.io/svt
项目地址:https://github.com/badripatro/svt
视觉transformer在各种计算机视觉任务(包括图像分类、实例分割和目标检测)中获得了极大的关注,并取得了最先进的性能。
现状: 在解决注意力复杂性和有效捕获图像中的细粒度信息方面现有的解决方案通常采用下采样操作(如池化)来降低计算成本,这种操作是不可逆转的,可能导致信息丢失。
解决: 提出了一种称为散射视觉Transformer(SVT)的新方法来解决这些挑战,SVT包含一个光谱散射网络,可以捕获复杂的图像细节。
- SVT通过分离低频和高频分量克服了与下采样操作相关的可逆性问题。
- SVT引入了一种独特的频谱门控网络,利用爱因斯坦乘法进行token和信道混合,有效降低了复杂度。
实验表明,SVT在ImageNet数据集上实现了最先进的性能,显著降低了许多参数和FLOPS。SVT比LiTv2和iFormer提高了2%。SVT-H-S达到84.2%的top-1精度,而SVTH-B达到85.2%(最先进的基础版本),SVT-H-L达到85.7%(也是最先进的大版本)。
创新点:
- 引入一种基于DTCWT变换的新型可逆散射网络,将图像特征分解为低频和高频特征。
- 提出了一种新的SGN,它使用TBM混合低频表示,使用EBM混合高频表示。在爱因斯坦乘法的帮助下,使用信道和token混合的有效方法来混合高频分量。
1 方法
1)背景:DTCWT及低高频解耦概述


2)SVT方法
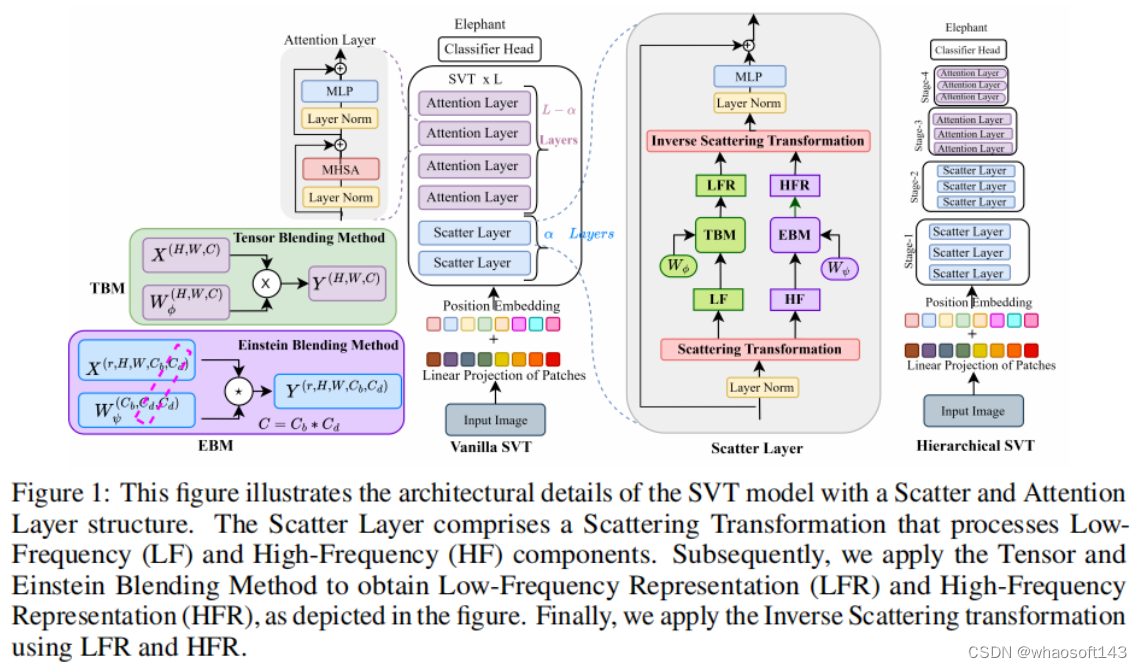
图1 SVT模型的分散和注意层结构的架构细节
图1详细说明了SVT体系结构的不同组件。散射视觉变压器由三个部分组成:a)散射变换,b)光谱门控网络,c)光谱通道和token混合。

B.频谱门控网络

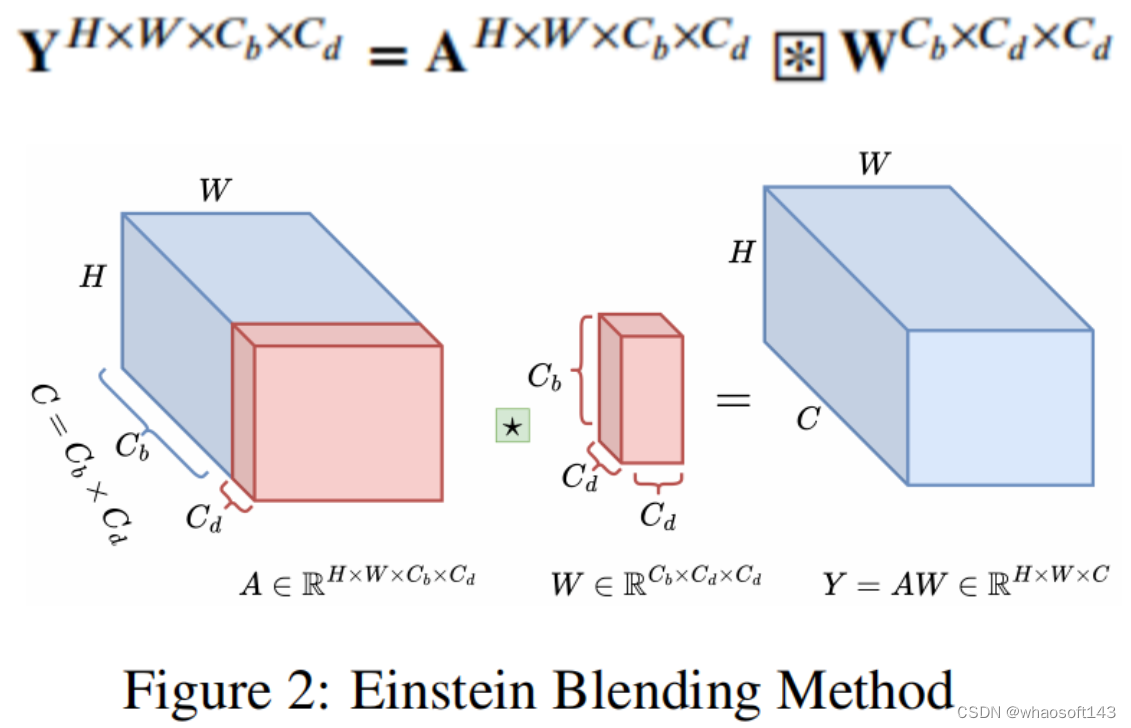
图2 EBM方法
C.频谱信道和token混合

实验结果
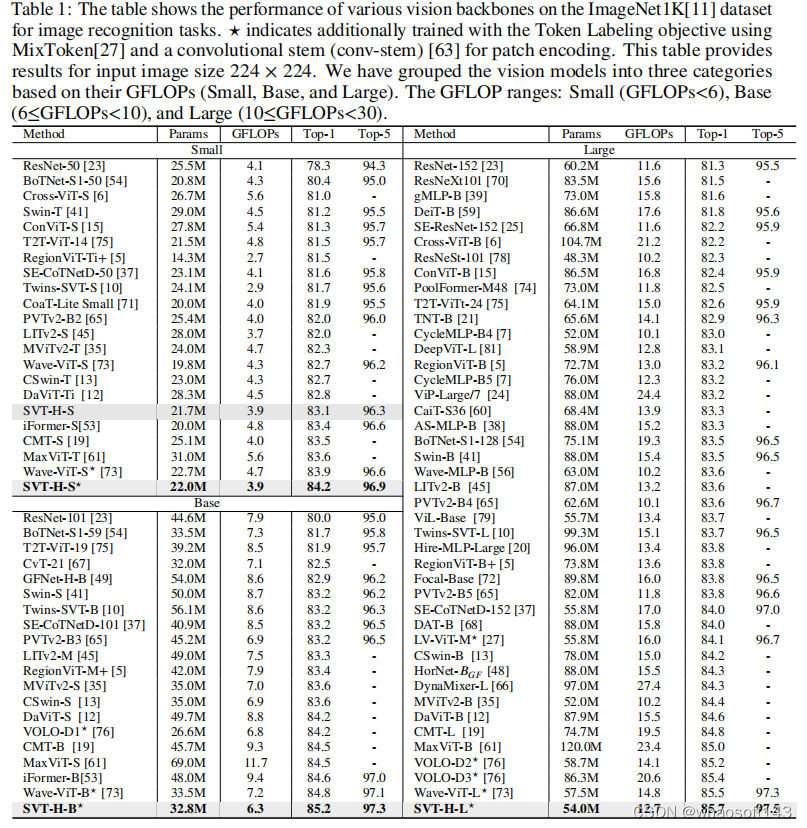
将SVT与LiTv2 (Hilo)进行比较,LiTv2 (Hilo)分解注意力以找到低频和高频分量。LiTv2的top-1准确率为83.3%,而SVT在参数数量较少的情况下的top-1准确率为85.2%。将SVT与从视觉数据中捕获低频和高频信息的iFormer进行了比较,其中SVT使用一种可反演的光谱方法即散射网络来获取低频和高频分量,并分别使用张量和爱因斯坦混合来捕获视觉数据中的有效光谱特征。SVT top-1精度为85.2,优于iFormer-B,在参数数量和FLOPS较少的情况下,其精度为84.6。
将SVT与WaveMLP进行比较,后者是一种基于MLP混频器的技术,使用幅度和相位信息来表示图像的语义内容。SVT使用低频分量作为原始特征的幅值,而高频分量捕获输入图像中复杂的语义变化。研究表明,如表1所示,SVT的性能比WaveMLP高出约1.8%。wave - vitb在多头注意方法的关键和值部分使用小波变换,而SVT使用散射网络,利用爱因斯坦和张量混合来分解具有可逆性和更好方向性的高低频分量,SVT比wave - v - b高出0.4%。















 7473
7473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









