







简介:Python是IT领域中用于自动化任务的广泛应用的编程语言。本文将深入探讨如何利用Python实现文件的批量重命名功能,特别通过实际的脚本文件如rename.py进行操作演示。我们会看到如何使用Python的os模块来读取文件列表、生成新的文件名,并执行重命名操作。同时,简要介绍了一个名为kalman.py的脚本,虽然与批量重命名文件不直接相关,但涉及到了在数据处理中常见的卡尔曼滤波器技术。 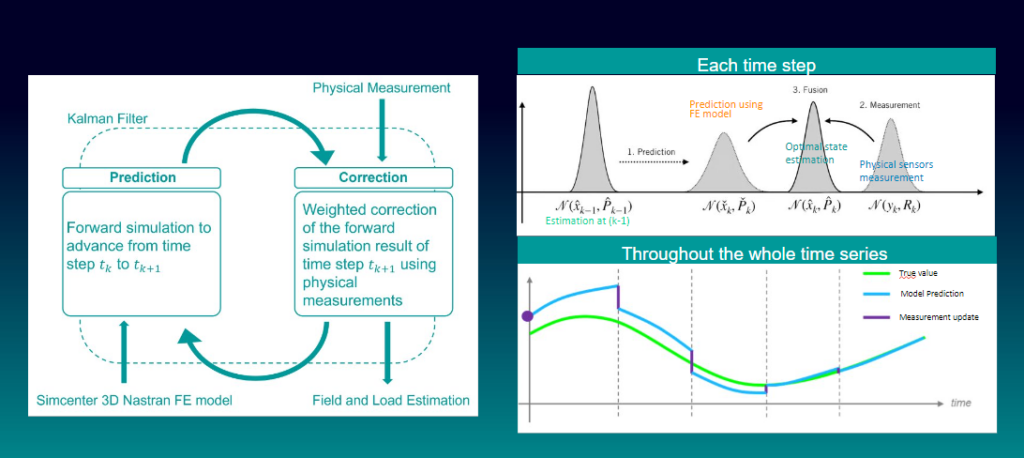
1. Python在自动化任务处理中的应用
1.1 Python语言的优势
Python被誉为“简洁明了的编程语言”,不仅因其易读性强、语法简单而受到初学者的欢迎,更因其广泛的库支持和强大的功能而受到专业开发者的青睐。在自动化任务处理方面,Python能够轻松地与其他系统交互,执行复杂的操作,这是其成为众多自动化工具首选语言的原因。
1.2 自动化任务处理的场景与实例
在现实世界中,自动化任务处理涉及到众多场景,包括但不限于:数据处理、文件管理、系统监控、网络请求等。例如,一个典型的应用场景是使用Python编写脚本来自动备份重要数据,无需人工干预即可定期执行,从而保障数据安全。
1.3 Python在自动化任务中的具体应用
以一个具体的例子来说明Python在自动化任务中的应用:假定一个IT管理员需要定期从日志文件中提取特定信息,通过Python脚本可以实现日志的自动读取、解析、信息提取,并输出结构化报告。这个过程可以使用Python的文件操作、正则表达式等库来完成,大大减少了重复劳动并提高了工作效率。
2. Python批量重命名文件的原理与方法
文件重命名的基本原理
文件重命名是一项基础且广泛应用于数据整理、文件管理和系统自动化的任务。在操作系统层面,文件重命名主要涉及修改文件的元数据,其中包括文件名这一属性。具体而言,当我们执行重命名操作时,操作系统会将新名称与原文件名在文件系统中的索引链接起来,同时更新相关的数据结构。尽管不同的操作系统可能采用不同的文件系统,但大多数都提供了重命名的命令或API接口。
文件系统的存储结构
理解文件系统的存储结构对于深入掌握批量重命名的原理至关重要。文件系统将存储设备划分为多个区域,用于存放文件数据和文件属性信息。在文件系统中,每个文件通常由其索引节点(inode)唯一标识,索引节点包含了文件的属性如大小、权限、创建时间等,其中就包括了文件名。当重命名操作发生时,文件系统的元数据结构会更新,新的文件名会替换旧的文件名与相应的索引节点关联。
批量重命名的流程
批量重命名文件的流程一般涉及以下几个步骤:
- 扫描目标文件夹 :确定需要重命名文件的文件夹,遍历该文件夹内所有文件。
- 确定重命名规则 :根据用户需求或预设规则,决定如何修改文件名。
- 执行重命名操作 :对每个文件应用重命名规则,调用文件系统的API进行重命名。
- 验证操作结果 :检查文件名是否按照预期被更改,确保没有错误发生。
文件系统的API接口
在编程层面,开发者通常会使用操作系统的API来实现文件重命名。例如,在Windows系统中,可以使用Win32 API,而在类Unix系统中,则可能使用POSIX标准的系统调用。Python通过其标准库中的os模块和shutil模块,为开发者提供了跨平台的文件操作接口,使得批量重命名变得简单易行。
使用Python脚本批量重命名文件
通过编写Python脚本,我们可以实现对文件系统的访问,并对文件进行批量重命名。这一过程不但可以自动化完成,还能够根据复杂的命名规则灵活地调整文件名。
Python文件操作模块
Python的os模块提供了与操作系统交互的接口,能够进行文件路径操作、文件系统遍历、文件属性查询等功能。shutil模块则用于文件的复制、移动、重命名等高级操作。以下是一个使用os模块进行文件重命名的基础示例:
import os
# 设定工作目录,假设我们的工作目录下有多个需要重命名的文件
directory = "/path/to/your/directory"
# 遍历目录下的所有文件
for filename in os.listdir(directory):
if filename.endswith(".txt"): # 假设只重命名.txt文件
# 新文件名由原文件名加上额外的信息组成
newname = "new_" + filename
# 构造完整的旧文件路径和新文件路径
old_path = os.path.join(directory, filename)
new_path = os.path.join(directory, newname)
# 执行重命名操作
os.rename(old_path, new_path)
print("所有文件重命名完成。")
批量重命名规则的实现
在上一个代码段的基础上,我们可以进一步实现更加复杂和灵活的批量重命名规则。例如,根据文件的创建时间、大小或其他属性来构造文件名。此外,我们可以将规则抽象成函数,以便于复用和维护。
import os
import time
def rename_files(directory, suffix, rule):
for filename in os.listdir(directory):
if filename.endswith(".txt"):
# 应用规则函数得到新文件名
newname = rule(filename, suffix)
old_path = os.path.join(directory, filename)
new_path = os.path.join(directory, newname)
os.rename(old_path, new_path)
def rule_by_time(filename, suffix):
# 以当前时间戳为后缀进行重命名
timestamp = str(int(time.time()))
return f"{filename.split('.')[0]}_{timestamp}{suffix}"
# 使用我们定义的规则函数进行文件重命名
rename_files("/path/to/your/directory", ".txt", rule_by_time)
在这个示例中,我们定义了一个 rule_by_time 函数,该函数将文件名和一个时间戳后缀结合,实现了以时间戳为依据的重命名规则。通过将重命名逻辑抽象成函数,我们能够轻松地调整和扩展重命名规则以满足不同场景下的需求。
执行批量重命名脚本
为了更进一步自动化重命名流程,我们可以将上述Python代码封装成一个脚本。通过命令行参数来接收输入目录、后缀和规则函数等,这样便能够在不同的文件集合上重复利用此脚本。
python rename_script.py --directory "/path/to/directory" --suffix ".txt" --rule "rule_by_time"
执行上述命令行指令,即可根据指定的规则对指定目录下的所有 .txt 文件进行批量重命名。
在下一章节中,我们将深入探讨os模块在实现文件批量重命名时的应用细节,并且提供一个具体的脚本示例——rename.py。通过分析这个脚本,我们将更直观地了解如何在实际场景中应用Python进行文件批量重命名的操作。
3. 使用os模块进行文件操作
文件操作基础
文件系统是操作系统用于管理数据存储在硬盘上的方式。文件操作指的是对文件系统的读、写、修改等行为。Python通过标准库中的os模块提供了对操作系统文件系统进行操作的能力。这些操作包括但不限于:
- 文件创建与删除
- 目录的创建与删除
- 文件或目录的重命名
- 路径管理
- 文件属性获取与修改
通过这些基础操作,开发者可以在不同的场景下对文件进行自动化处理。
os模块文件操作方法
下面的表格展示了os模块中常用的文件操作方法及其用途。
| 方法 | 用途 | | --- | --- | | os.remove(path) | 删除文件 | | os.rename(src, dst) | 重命名文件或目录 | | os.mkdir(path[, mode]) | 创建目录 | | os.makedirs(name[, mode]) | 递归创建目录 | | os.rmdir(path) | 删除目录 | | os.walk(top, topdown=True, οnerrοr=None, followlinks=False) | 生成目录树下的文件名 |
这些方法为进行文件和目录操作提供了基础的工具。
文件操作的实例
假设我们有一个目录,里面存放了大量未命名的文件,我们希望将这些文件批量重命名为具有特定模式的名字。
首先,我们可以使用 os.listdir() 来获取目录中所有的文件列表,然后遍历这些文件名并使用 os.rename() 方法进行重命名。
import os
# 目标目录
directory = "/path/to/your/directory"
# 获取目录下所有文件名
files = os.listdir(directory)
for idx, file in enumerate(files):
# 新文件名格式为: "new_name_<index>.ext"
new_name = f"new_name_{idx}.txt"
# 构建完整的文件路径
new_file_path = os.path.join(directory, new_name)
old_file_path = os.path.join(directory, file)
# 重命名文件
os.rename(old_file_path, new_file_path)
print("文件批量重命名完成")
在此代码中,我们使用了 os.path.join() 方法来构建完整的文件路径,这样可以避免硬编码路径,并确保代码的可移植性。
批量重命名逻辑详解
进行批量重命名操作时,需要考虑文件的新命名规则。在上面的代码中,我们使用了一个简单的计数器来创建新的文件名,并通过 os.rename() 方法来改变文件名。
重命名的参数说明
os.rename(src, dst) 方法需要两个参数:
-
src:源文件名 -
dst:目标文件名
如果 dst 已经存在,则该文件将被覆盖。这一特性在实际使用中需要注意,以避免无意中覆盖重要文件。
批量重命名的优化
在批量重命名文件时,我们还可以考虑以下优化措施:
- 使用异常处理来避免因文件不存在或权限问题导致的程序异常。
- 使用日志记录重命名的操作,便于问题追踪。
- 对于具有相同原始文件名但应有不同扩展名的文件,可以先重命名扩展名。
import os
directory = "/path/to/your/directory"
files = os.listdir(directory)
for file in files:
name, ext = os.path.splitext(file)
if ext: # 如果有扩展名
new_name = f"{name}_renamed{ext}"
else: # 没有扩展名
new_name = f"{name}_renamed.txt"
src = os.path.join(directory, file)
dst = os.path.join(directory, new_name)
try:
os.rename(src, dst)
except OSError as e:
print(f"文件 {file} 重命名失败: {e}")
print("文件批量重命名完成,并加入了异常处理")
此代码段将日志信息打印在控制台上,提供了一定程度的错误处理。开发者可以根据需要将日志记录到文件中。
文件操作的限制和注意事项
进行文件操作时,有几个限制和注意事项需要考虑:
- 文件访问权限 :在不同的操作系统中,对文件和目录的访问权限可能会有所不同。在编写文件操作代码时,应当考虑到不同平台的权限问题。
- 文件名编码 :在处理文件名时,尤其是涉及到不同语言或特殊字符时,可能会遇到编码问题。Python 3 默认使用 UTF-8 编码,这有助于避免很多编码问题。
- 异常处理 :文件操作可能会因为各种原因失败(如文件正在使用中),因此编写健壮的异常处理代码是必要的。
- 文件系统的差异 :不同的文件系统对大小写敏感性、路径表示法等可能有不同的规定。在跨平台开发时,这些差异应当被考虑。
在编写涉及文件操作的自动化脚本时,以上注意事项可以帮助避免常见的问题。通过合理利用os模块,开发者可以实现对文件系统高效、安全的管理。
4. 实际脚本rename.py的功能描述
在自动化文件处理任务中,Python脚本往往能够通过简洁的代码实现强大的功能。接下来,我们将深入分析rename.py脚本,该脚本是根据文件名的特定模式批量重命名文件的实用工具。通过展示和解释脚本的关键代码段,我们将揭示如何有效地执行复杂的文件重命名操作。
功能介绍与初始化
首先,rename.py脚本需要确定操作的起始目录。该脚本将遍历指定目录下的所有文件,并根据用户定义的规则进行重命名。它支持参数化方式,允许用户通过命令行输入来指定源目录和重命名规则。
import argparse
import os
from pathlib import Path
def parse_arguments():
parser = argparse.ArgumentParser(description="批量重命名文件脚本")
parser.add_argument("source_dir", help="源目录路径")
parser.add_argument("pattern", help="匹配文件的正则表达式")
parser.add_argument("replacement", help="替换匹配到的模式")
return parser.parse_args()
def main():
args = parse_arguments()
source_dir = Path(args.source_dir)
for file in source_dir.glob(f'*{args.pattern}*'):
old_file = file.resolve()
new_file = old_file.with_name(old_file.name.replace(args.pattern, args.replacement))
old_file.rename(new_file)
if __name__ == '__main__':
main()
在上面的代码块中, parse_arguments 函数使用 argparse 模块来解析命令行输入。这使得脚本更具灵活性,用户可以直接指定需要处理的文件夹、匹配模式和替换字符串。脚本的主函数 main 中,我们使用 Path 来处理文件路径,并通过 glob 方法找到符合模式的文件。然后,使用文件名替换方法和 rename 方法完成重命名操作。
执行逻辑与参数说明
在执行逻辑方面,用户首先运行脚本并传入必要的参数。脚本接收源目录、文件匹配模式和替换字符串作为输入。通过遍历目录中的所有文件,脚本检查文件名是否与用户提供的匹配模式相匹配。如果匹配,脚本将使用指定的替换字符串来修改文件名并进行重命名。
此过程中,参数 source_dir 定义了需要批量重命名文件的目录,参数 pattern 为文件名中需要被替换的部分,参数 replacement 是用于替换的字符串。为了更好地理解这个过程,下面提供了一个简单的用例。
python rename.py /path/to/files "old_pattern" "new_pattern"
假设用户在命令行中输入上述命令,脚本将会遍历 /path/to/files 目录中的所有文件。如果文件名中包含 old_pattern ,则将其替换为 new_pattern 。
源代码逐行解读
现在,我们将逐行分析 main 函数内的关键代码,以便更好地理解脚本的工作机制。
source_dir = Path(args.source_dir)
这一行将命令行输入的 source_dir 参数转换为一个 Path 对象, Path 对象是 pathlib 模块提供的,用于操作文件系统路径。
for file in source_dir.glob(f'*{args.pattern}*'):
这里使用 glob 方法查找所有匹配 pattern 参数的文件。 glob 方法返回一个生成器,包含匹配到的所有文件路径。
old_file = file.resolve()
resolve 方法将相对路径转换为绝对路径,确保操作的是正确的文件。
new_file = old_file.with_name(old_file.name.replace(args.pattern, args.replacement))
with_name 方法用来获取一个新路径对象,其中文件名部分被替换。 replace 方法则是用来替换文件名中的指定字符串。
old_file.rename(new_file)
最后,使用 rename 方法将旧文件名替换为新文件名。这是完成重命名操作的关键一步。
功能性扩展与优化
为了提高rename.py脚本的灵活性和用户体验,我们可以考虑加入一些额外的功能。例如:
- 增加日志记录功能,记录每次重命名的操作结果。
- 添加文件类型过滤选项,只处理特定类型的文件。
- 实现撤销功能,以便在错误操作时能够快速恢复原文件名。
此外,我们还可以通过异常处理来优化脚本,确保在遇到无法访问的文件或者权限问题时能够给用户清晰的反馈。
try:
old_file.rename(new_file)
except OSError as e:
print(f"文件重命名失败: {old_file} -> {new_file},错误信息: {e}")
以上代码段展示了如何处理文件操作中可能出现的异常情况。
通过本章的详细分析,我们揭示了rename.py脚本的内部工作逻辑及其核心功能。理解这些内容将帮助读者更好地掌握如何使用Python脚本来解决实际的文件处理问题,并且可以在此基础上进行适当的定制和扩展。
5. kalman.py脚本的概念介绍
在现代信号处理和控制系统领域,卡尔曼滤波算法被广泛应用于解决实际问题。这种算法是一种高效的递归滤波器,它能够从一系列的含有噪声的测量中,估计动态系统的状态。尽管其数学原理相对复杂,但Python作为一种高级编程语言,通过其丰富的库支持,使得实现卡尔曼滤波算法变得简单。本章将介绍kalman.py脚本的基本概念和用途。
5.1 卡尔曼滤波算法简介
卡尔曼滤波算法由Rudolf E. Kalman于1960年提出,它的核心思想是利用线性系统状态方程,通过预测和更新两个步骤对系统的状态进行估计。该算法可以应对含有噪声的系统和测量数据,从而提供一个较为精确的状态估计。
5.1.1 预测(Prediction)步骤
在预测步骤中,算法根据系统模型预测下一时刻的状态,同时考虑过程噪声。
# 预测步骤的伪代码示例
predicted_state = A * current_state + B * control_input
predicted_error_covariance = A * current_error_covariance * A.T + Q
5.1.2 更新(Update)步骤
在更新步骤中,根据实际测量值来校正预测值,得到更加准确的当前状态估计。
# 更新步骤的伪代码示例
measurement_matrix = ...
measurement = ...
predicted_state = ...
predicted_error_covariance = ...
kalman_gain = predicted_error_covariance * measurement_matrix.T * ...
updated_state = predicted_state + kalman_gain * (measurement - measurement_matrix * predicted_state)
updated_error_covariance = (I - kalman_gain * measurement_matrix) * predicted_error_covariance
5.2 kalman.py脚本功能
kalman.py脚本是Python语言实现的一个简单示例,展示了如何使用卡尔曼滤波算法来处理序列数据。该脚本不仅仅用于学术研究,它在实际工程问题中也具有广泛的应用前景,例如导航系统、股票市场分析、机器人运动控制等领域。
5.2.1 脚本的主要功能
- 数据状态估计
- 过程和测量噪声的处理
- 动态系统状态的实时跟踪
5.2.2 关键代码块解读
下面是一个简化的kalman.py脚本的关键部分,用于说明脚本如何实现卡尔曼滤波算法。
# 卡尔曼滤波算法核心函数
def kalman_filter(measurement, control_input):
# 预测当前状态估计
predicted_state = A * state + B * control_input
predicted_error_covariance = A * error_covariance * A.T + Q
# 更新状态估计
kalman_gain = predicted_error_covariance * H.T * np.linalg.inv(H * predicted_error_covariance * H.T + R)
state = predicted_state + kalman_gain * (measurement - H * predicted_state)
error_covariance = (I - kalman_gain * H) * predicted_error_covariance
return state, error_covariance
# 初始化变量
state = np.zeros((n, 1)) # 初始状态估计
error_covariance = np.eye(n) # 初始状态误差协方差
5.2.3 使用场景与应用
kalman.py脚本的应用场景涵盖了需要状态估计的各种动态系统,例如:
- 在导航系统中,用于估计和修正飞行器的位置和速度;
- 在金融分析中,用于预测股票价格的走势;
- 在机器人领域,用于实时校正机械臂的位置。
5.3 本章总结
通过本章的介绍,我们了解了卡尔曼滤波算法的基本原理及其在kalman.py脚本中的应用。这种算法能够提供一种有效的手段来处理不确定性问题,它在多个领域都有广泛的应用。了解和掌握其原理,对于想要提高数据分析能力和系统建模能力的读者来说,是一种宝贵的知识财富。
简介:Python是IT领域中用于自动化任务的广泛应用的编程语言。本文将深入探讨如何利用Python实现文件的批量重命名功能,特别通过实际的脚本文件如rename.py进行操作演示。我们会看到如何使用Python的os模块来读取文件列表、生成新的文件名,并执行重命名操作。同时,简要介绍了一个名为kalman.py的脚本,虽然与批量重命名文件不直接相关,但涉及到了在数据处理中常见的卡尔曼滤波器技术。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









