







在许多业务数据分析场景中,数据不一定十分完整,总是存在部分缺失值,因此,数据清洗阶段,对缺失值进行处理就显得尤为重要。本文介绍一些缺失值处理的示例,主要用到的库有:pandas、numpy 、sklearn。
1.导入需要的库。
import pandas as pd
import numpy as np
from sklearn.preprocessing import Imputer
2.生成缺失数据。
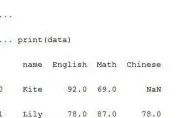
data=pd.DataFrame({'name':['Kite','Lily','Hanmei','Danny','Bob'],'English':[92,78,np.nan,23,82],'Math':[69,87,91,np.nan,90],'Chinese':[np.nan,78,96,np.nan,75]})
print(data)
3.查看缺失值。
data.isnull()#查看所有缺失值
data.isnull().any()#获取含有缺失值的列
data.isnull().all()#获取全部为NA的列
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1485
1485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









