







简介:郑丽版C++课件是一套专为初学者和进阶者设计的教程,涵盖了C++的核心概念、语法和编程实践。通过理论与实例结合的教学方式,让学习者能够深入理解数据类型、控制结构、面向对象编程、函数、异常处理、I/O流、预处理器、模板和STL等关键知识点。本课件旨在帮助学生建立起扎实的C++编程基础,并提高编程思维和问题解决能力。 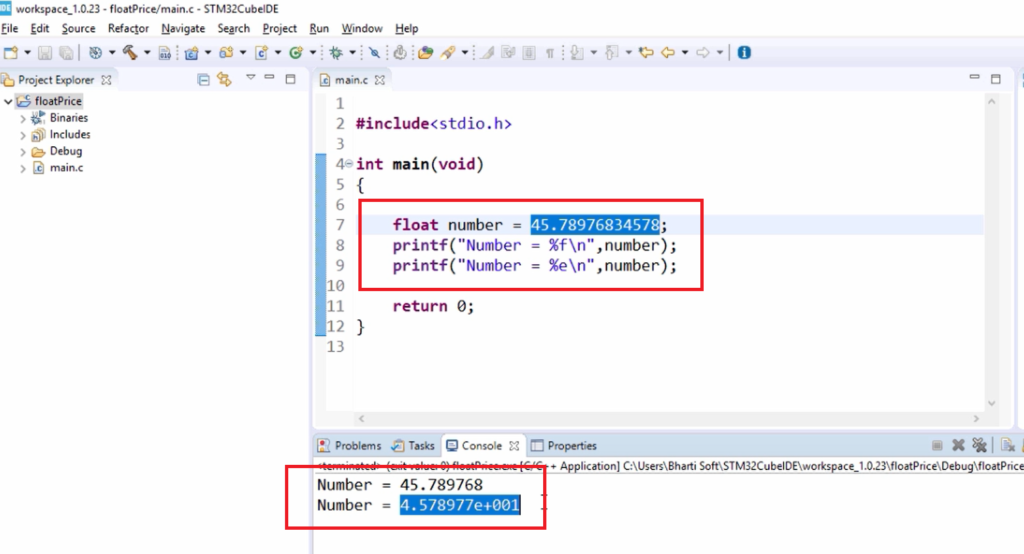
1. C++基础概念详解
C++是一种静态类型、编译式、通用的编程语言,它支持过程化、面向对象以及泛型编程。在深入了解C++的高级特性和库之前,我们需要掌握其基础概念。这些基础概念包括了程序结构的基本构成元素,如变量、数据类型、函数等。
1.1 C++的历史与特点
C++语言是在1980年代初期由Bjarne Stroustrup在贝尔实验室中开发的。它最初是作为C语言的一个增强版本,目的是在保持C语言的执行效率的同时,增加面向对象编程(OOP)的能力。从C到C++的演变过程中,C++支持了类的定义,增强了数据的抽象能力,引入了运算符重载和异常处理等特性。
C++的主要特点包括:
- 多范式编程语言 :支持过程式、面向对象和泛型编程。
- 高性能 :编译型语言,具有接近汇编语言的执行速度。
- 丰富标准库 :提供了丰富的标准模板库(STL),包括数据结构、算法等。
- 跨平台 :通过抽象层实现代码在不同平台间的可移植性。
1.2 C++程序的基本结构
一个基本的C++程序结构通常包含以下部分:
#include <iostream> // 引入输入输出流库
int main() {
// 主函数,程序的入口点
std::cout << "Hello, World!" << std::endl; // 输出语句
return 0; // 返回0,表示程序正常结束
}
上述代码展示了C++程序的基本框架,其中包含了预处理指令 #include <iostream> ,用于包含标准输入输出流库。 main 函数是每个C++程序的执行入口, std::cout 是用于输出的流对象, << 操作符用于向流中插入数据, std::endl 是插入一个换行符并刷新输出缓冲区。最后, return 0; 语句表示程序正常退出。
C++程序的执行总是从 main 函数开始,结束于 main 函数的返回。程序的其他部分可以通过函数或类来组织和管理。接下来的章节将深入介绍C++的各种基础概念和高级特性,帮助开发者编写出高效、健壮且可维护的代码。
2. 数据类型和变量的探索
2.1 基本数据类型的理解与应用
在编程中,数据类型是定义变量可以存储的数据种类,每种类型都有其特定的大小和表示方式。C++提供了多种基本数据类型,它们可以分为两大类:内置类型和用户自定义类型。内置类型包括整型、浮点型、字符型等,这些类型对于存储和处理数据至关重要。理解这些数据类型及其用法是深入学习C++的基础。
2.1.1 整型、浮点型和字符型的区别及使用场景
整型数据类型用于表示整数值。根据大小和符号的不同,整型又分为几种: int 、 short 、 long 、 unsigned 和 signed 。不同编译器可能对它们的大小有不同的实现,但通常情况下, int 是32位, short 是16位, long 至少是32位, unsigned 表示无符号整数。
浮点型数据类型用来存储小数或科学计数法表示的数值。C++中最常用的浮点型是 float 和 double 。 float 类型通常是单精度,而 double 类型是双精度。浮点数在计算机内部是以IEEE 754标准进行编码的。
字符型数据类型用于表示单个字符,常见的有 char 类型,它可以是有符号的也可以是无符号的,这取决于编译器。字符型常用于存储字符数据,如字母、数字等。
在选择使用哪种数据类型时,需要考虑数据的大小范围、精度需求以及存储空间的限制。例如,如果需要存储大量的小数值,可能会优先考虑使用 double 类型以获得更高的精度;而如果是在嵌入式系统中,空间非常宝贵,则可能会选择 int 或 short 来减少内存使用。
int main() {
int integerNum = 10; // 整型示例
float floatingNum = 3.14159f; // 浮点型示例
char charValue = 'A'; // 字符型示例
return 0;
}
在上述代码中,声明了一个整型变量 integerNum ,一个浮点型变量 floatingNum ,以及一个字符型变量 charValue 。每个变量都被赋予了一个适当的字面量值。
2.2 变量的作用域和生命周期
变量的作用域是指变量在程序中的有效范围,而生命周期则是指变量从创建到销毁的时间段。理解这两者对于管理程序中的数据至关重要。
2.2.1 全局变量与局部变量的区别
全局变量是在函数外部定义的变量,它们在整个程序中都是可见的,且其生命周期贯穿整个程序运行期。全局变量虽然方便了数据在不同函数间共享,但过度使用可能导致程序难以理解和维护。
局部变量是在函数或代码块内部定义的变量,它们只在定义它们的作用域内有效,生命周期从变量声明开始,到作用域结束。局部变量提供了数据封装,有助于防止对数据的意外修改。
int globalVar = 1; // 全局变量声明
void functionA() {
int localVar = 2; // 局部变量声明
// 局部变量localVar只在functionA内可见和有效
}
void functionB() {
// globalVar在functionB内也是可见的
}
int main() {
// globalVar和localVar都在main函数的作用域内有效
return 0;
}
在上述代码中, globalVar 作为全局变量,可在任何函数内部访问。而 localVar 仅在 functionA 内部声明和有效。注意,在 main 函数和 functionB 内也能够访问 globalVar ,因为全局变量的作用域是整个程序。
2.2.2 静态变量、常量和引用变量的特性
静态变量分为静态局部变量和静态全局变量。局部静态变量具有全局生命周期,但其作用域仅限于声明它的函数内部。全局静态变量与普通全局变量类似,但它仅在声明它的文件内可见,即具有文件作用域。静态变量在程序启动时初始化,并在程序结束时销毁。
常量是一种不可修改的变量,它必须在定义时初始化,之后的任何尝试修改都将导致编译错误。常量表达式在编译时期就被求值。
引用变量是对已经存在变量的别名。声明引用时,必须初始化,且一旦初始化之后就无法再引用其他变量。
const int constVar = 100; // 常量声明
void function() {
static int staticVar = 0; // 静态局部变量声明
staticVar++;
// staticVar在function调用之间保持其值
}
int main() {
int &refVar = constVar; // 引用变量声明
// refVar是对constVar的引用
return 0;
}
在上述示例中, constVar 是一个常量,不能修改; staticVar 是一个静态局部变量,它的值会在函数调用之间保持不变; refVar 是一个引用变量,它引用了 constVar 。
通过变量的不同特性,我们可以控制数据在程序中的存储方式和生命周期,以更好地适应程序设计的需要。全局变量、局部变量、静态变量、常量以及引用变量,每种类型在不同的编程场景中发挥着各自的作用。
在本章节中,我们介绍了基本数据类型和变量的作用域与生命周期。通过深入理解这些基础概念,我们可以更加灵活地使用数据类型和控制变量,从而编写出更健壮、高效的代码。在后续章节中,我们将继续深入探讨C++编程的其他重要概念和高级特性。
3. 运算符和控制结构的深入剖析
3.1 运算符的分类和用法
3.1.1 算术运算符、关系运算符和逻辑运算符
在 C++ 中,算术运算符用于执行基本的数学运算,关系运算符用于比较操作,而逻辑运算符用于连接条件表达式。理解这些基础概念对于编写清晰和高效的控制结构至关重要。
- 算术运算符 :
+(加)、-(减)、*(乘)、/(除)和%(取模)。 - 关系运算符 :
==(等于)、!=(不等于)、<(小于)、>(大于)、<=(小于等于)、>=(大于等于)。 - 逻辑运算符 :
&&(逻辑与)、||(逻辑或)、!(逻辑非)。
举个例子,我们可以使用关系运算符来判断一个数是否在特定的范围内:
int number = 10;
if (number > 0 && number < 20) {
// 当 number 大于 0 且小于 20 时执行的代码
}
代码逻辑说明: - 此代码段首先声明了一个整型变量 number 并初始化为 10。 - 接着,使用 if 控制结构和关系运算符来检查 number 是否位于 0 到 20 的范围内。 - 如果条件为真,执行大括号内的代码块。
3.1.2 赋值运算符、位运算符及条件运算符
C++ 中的赋值运算符不仅包括基本的赋值操作 = ,还有复合赋值运算符如 += 、 -= 等,用于将运算的结果重新赋值给左侧变量。位运算符如 & (与)、 | (或)、 ^ (异或)和 ~ (取反)用于对整型数据的二进制位进行操作。条件运算符(也称为三元运算符) ?: 提供了一个简短的方式来实现基于条件的赋值。
下面是一个使用复合赋值运算符的例子:
int a = 10;
a += 5; // a = a + 5, 结果 a 现在等于 15
代码逻辑说明: - 在这个代码段中,我们首先声明并初始化一个整数变量 a 为 10。 - 使用 += 运算符将 a 的值增加 5,这样做比 a = a + 5; 更为简洁。
3.2 控制结构的灵活运用
3.2.1 if-else、switch语句的决策控制
C++ 提供了 if 、 else 和 switch 语句来实现程序的条件分支。 if 语句用于基于布尔表达式的条件执行,而 switch 语句主要用于基于整型或枚举值的多路分支。
以下是 switch 语句的一个典型用法,用于根据用户的输入执行不同的动作:
int choice = 2;
switch (choice) {
case 1:
// 执行选择1的操作
break;
case 2:
// 执行选择2的操作
break;
default:
// 默认操作
break;
}
代码逻辑说明: - 代码开始于声明一个名为 choice 的整型变量,并将其初始化为 2。 - switch 语句检查 choice 的值,并与每个 case 标签进行比较。 - 当找到匹配的 case 标签时,执行相应的代码块, break 语句用于退出 switch 。 - 如果没有任何 case 匹配,则执行 default 代码块。
3.2.2 for、while、do-while循环的结构与优化
循环结构是控制结构中的另一重要组成部分,包括 for 、 while 和 do-while 循环,它们使得代码可以重复执行多次。
- for 循环 :通常用于预先知道循环次数的情况。
- while 循环 :在不确定循环次数的情况下非常有用,它会在给定的条件为真时持续执行。
- do-while 循环 :至少执行一次循环体,之后再根据条件判断是否继续执行。
这里展示一个使用 while 循环的例子:
int count = 0;
while (count < 5) {
// 执行循环体内的代码
count++;
}
代码逻辑说明: - while 循环开始之前,声明并初始化一个名为 count 的整型变量为 0。 - 循环条件检查 count 是否小于 5,如果是,则进入循环体。 - 在循环体内,执行需要重复的操作,然后通过 count++ 递增计数器。 - 当 count 达到 5 时,循环结束。
以上内容是对 C++ 运算符和控制结构的深入剖析,详细分析了每种运算符和控制结构的用途和具体使用方式。理解这些基础概念对于编写高效、逻辑清晰的代码是必不可少的。下一节我们将探讨类与对象,深入理解面向对象编程的核心。
4. 类与对象——面向对象编程的核心
4.1 类的定义与对象的创建
在面向对象编程(OOP)中,类是创建对象的蓝图或模板。一个类定义了一组对象共享的属性(成员变量)和行为(成员函数)。对象是类的实例,拥有类定义的属性和方法。
4.1.1 类的成员变量和成员函数
成员变量表示类的状态,而成员函数定义了类能够执行的操作。一个简单的例子如下所示:
class Rectangle {
public:
// 构造函数
Rectangle(int width, int height) : width_(width), height_(height) {}
// 成员函数计算面积
int area() const {
return width_ * height_;
}
// 其他成员函数...
private:
int width_;
int height_;
};
在这个 Rectangle 类中, width_ 和 height_ 是成员变量, area 是成员函数。成员函数可以访问和修改对象的私有成员变量。
. . . 成员变量和函数的作用域
成员变量和函数的作用域局限于类的定义中,它们默认为私有(private),这意味着它们不能被类的外部访问。通过在成员变量或函数前加 public 或 private 关键字,可以控制其访问权限。
class Example {
public:
int publicVariable; // 可以被任何代码访问
private:
int privateVariable; // 只能被Example类的成员函数访问
};
4.1.2 对象的初始化与构造函数
对象的初始化通常是在声明对象时完成的,构造函数在对象创建时被自动调用。
. . . 构造函数的特性
构造函数具有以下特性:
- 与类名相同
- 没有返回类型
- 可以重载,即一个类可以有多个构造函数,区别在于它们的参数列表
下面是一个构造函数的示例:
Rectangle(int w, int h) : width_(w), height_(h) {
// 初始化列表设置成员变量的值
}
Rectangle() : Rectangle(0, 0) { // 默认构造函数
// 默认构造函数调用了另一个构造函数
}
4.2 封装、继承与多态的实现
封装、继承和多态是面向对象编程的三大特性。它们是实现代码重用、维护和扩展的基础。
4.2.1 访问控制符的使用与封装原理
封装是隐藏对象的内部实现细节,仅暴露操作接口给外界。访问控制符 public 、 private 和 protected 可以控制类成员的访问级别。
class EncapsulationExample {
private:
int privateMember;
public:
void setPrivateMember(int value) {
privateMember = value;
}
};
在这个例子中, privateMember 是私有的,不能被类外直接访问,而通过 setPrivateMember 函数提供的接口可以间接修改。
. . . 封装的好处
封装的好处包括:
- 隐藏实现细节
- 保护对象中的数据
- 通过接口控制外部对对象的访问
4.2.2 继承机制与多态性的应用
继承允许我们创建一个类的层次结构,其中子类继承父类的属性和方法。多态性是允许使用父类类型的引用指向子类对象,而调用时执行子类的特定实现。
class Base {
public:
virtual void print() const { // 虚函数实现多态性
std::cout << "Base class" << std::endl;
}
};
class Derived : public Base {
public:
void print() const override { // 重写基类函数
std::cout << "Derived class" << std::endl;
}
};
Base *bPtr = new Derived(); // 多态性使用
bPtr->print(); // 输出 "Derived class"
在这个例子中, Derived 类重写了基类 Base 的 print 函数。创建一个基类指针指向一个派生类对象,并调用 print 函数时,将执行派生类的 print 方法,这个特性称为多态。
. . . 继承的类型
在C++中,继承可以是单一继承或多重继承。单继承指一个类只继承自一个基类,而多重继承指一个类可以继承自多个基类。
class SingleDerived : public Base {};
class MultipleDerived : public Base, public AnotherBase {};
继承类型的选择取决于设计需求和复杂性。多重继承在某些情况下可能导致菱形继承问题,这需要额外的注意。
. . . 多态性的实现
多态是通过虚函数实现的,其核心是虚拟函数表(vtable)。当基类指针或引用指向派生类对象时,通过vtable,程序能够在运行时确定调用哪个函数版本。
flowchart LR
A[Base] --> B[vtable]
B --> C[print()]
A --> D[Derived]
D --> E[vtable]
E --> F[print()]
在上述mermaid流程图中,展示了多态工作原理的一个简化表示。每个对象中包含一个指向vtable的指针,vtable中包含了指向实现的函数指针。当多态性被调用时,程序通过vtable中合适的函数指针来实现正确的函数调用。
5. 函数与函数模板的高级应用
5.1 函数的声明与定义
5.1.1 函数重载与默认参数的策略
函数重载和默认参数是C++中实现多态的重要特性之一。函数重载允许我们定义多个同名函数,但它们的参数列表必须不同(参数的类型、数量或顺序至少有一个不同)。这是函数的多态性,允许根据调用时提供的参数类型和数量来选择合适的函数版本。
#include <iostream>
using namespace std;
// 函数重载示例
void print(int a) {
cout << "Int value: " << a << endl;
}
void print(double a) {
cout << "Double value: " << a << endl;
}
void print(string a) {
cout << "String value: " << a << endl;
}
// 默认参数示例
void display(int a, int b = 0, int c = 0) {
cout << "Display with defaults: " << a << " " << b << " " << c << endl;
}
int main() {
print(10); // 输出: Int value: 10
print(3.14); // 输出: Double value: 3.14
print("text"); // 输出: String value: text
display(1); // 输出: Display with defaults: 1 0 0
display(1, 2); // 输出: Display with defaults: 1 2 0
display(1, 2, 3); // 输出: Display with defaults: 1 2 3
return 0;
}
在使用函数重载时,编译器会根据调用时的参数类型和数量来确定调用哪个函数。而在使用默认参数时,如果调用者没有提供足够的参数,编译器会自动补全默认值。
5.1.2 inline函数与递归函数的特点
inline 关键字用于函数定义时,可以告诉编译器这个函数应该尽可能在调用点展开,而不是作为传统函数调用。 inline 函数的主要目的是为了减少函数调用的开销,但需要注意的是,并不是所有的函数都应该声明为 inline 。只有当函数体很小,且被频繁调用时, inline 才可能提高程序的性能。
递归函数是一种调用自身的函数,它通常用于解决可以分解为更小子问题的问题,例如树的遍历、快速排序和斐波那契数列等。递归函数需要注意的是递归深度以及递归终止条件,否则可能造成栈溢出或者性能问题。
// inline函数示例
inline int max(int a, int b) {
return (a > b) ? a : b;
}
// 递归函数示例
int factorial(int n) {
if (n <= 1) {
return 1;
} else {
return n * factorial(n - 1);
}
}
int main() {
cout << max(20, 30) << endl; // 输出: 30
cout << factorial(5) << endl; // 输出: 120
return 0;
}
在 max 函数的定义中使用了 inline ,它是一个非常短的函数,适合内联。而 factorial 函数是一个典型的递归函数,它会不断调用自身直到达到基本情况。这两个特性都是高级应用,在实际编程中应合理使用以提高代码的性能和可读性。
5.2 函数模板的设计与应用
5.2.1 模板的定义与实例化
函数模板是泛型编程的一个重要工具,它允许程序员编写与数据类型无关的代码。模板定义了一个或多个未指定类型的占位符(通常是 T ),然后在实例化时由编译器自动替换为具体的数据类型。
// 函数模板定义
template <typename T>
T max_template(T a, T b) {
return (a > b) ? a : b;
}
// 函数模板实例化
int main() {
cout << max_template(10, 20) << endl; // int类型实例化
cout << max_template(10.5, 20.5) << endl; // double类型实例化
cout << max_template("text1", "text2") << endl; // const char*类型实例化
return 0;
}
模板可以在编译时进行参数化类型替换,能够创建通用的函数或类,从而提高代码的复用性。编译器在编译时会根据使用模板时提供的实际类型进行实例化,生成特定类型的代码。
5.2.2 模板特化与函数模板的混合使用
模板特化允许我们为特定类型提供专门的模板实现。当标准模板不能满足特定类型需求时,模板特化就显得十分重要。此外,还可以对模板进行部分特化,这为模板编程提供了更大的灵活性。
// 模板特化示例
template <typename T>
T const& min_template(T const& a, T const& b) {
return (a < b) ? a : b;
}
// 针对数组类型的特化
template <typename T>
T const& min_template(T const arr[], size_t n) {
T const* smallest = arr;
for (size_t i = 1; i < n; ++i) {
if (arr[i] < *smallest) {
smallest = &arr[i];
}
}
return *smallest;
}
int main() {
int array[] = {1, 2, 3, 4, 5};
cout << min_template(array, 5) << endl; // 特化后的模板实例化
return 0;
}
在上面的代码中,我们定义了一个泛型的 min_template 函数模板,以及针对数组类型的特化版本。模板特化是模板编程中一个高级特性,它允许程序员为特定的数据类型提供更加高效的实现。
通过上述内容的详细介绍,函数与函数模板的高级应用不仅深入理解了C++中函数的多样性和灵活性,同时也展示了如何有效地利用这些特性来设计出更加通用、高效和可重用的代码。在实际的软件开发过程中,合理运用这些高级特性,将大大提升程序的性能和开发效率。
6. 异常处理机制——代码健壮性的保障
异常处理是现代编程语言中用于处理程序运行时错误的标准机制。它允许程序在遇到错误情况时不会直接崩溃,而是可以优雅地处理错误,并继续执行或安全地终止。C++作为一种强类型语言,对异常处理提供了完善的机制,本章将深入探讨C++中的异常处理原理及应用。
6.1 异常处理的基本原理
异常处理允许程序定义异常处理代码块,在发生错误时将程序流程转移到对应的异常处理代码块,从而实现对异常情况的响应。理解其基本原理是编写健壮C++程序的关键。
6.1.1 try、catch和throw的关键作用
在C++中,异常处理主要涉及三个关键字: try 、 catch 和 throw 。 try 块用于包围可能抛出异常的代码, catch 块用于捕获和处理异常,而 throw 用于显式地抛出异常。
异常的抛出
异常抛出使用 throw 关键字后跟异常对象。通常情况下, throw 后面跟的是一个对象,这个对象的类型决定了catch块如何处理异常。
throw std::runtime_error("An error occurred");
上述代码抛出了一个 std::runtime_error 异常,通常用于表示运行时错误。构造函数中的字符串是异常信息,可在 catch 块中获取。
异常的捕获
try 块内代码若抛出了异常,控制流就会被传递到与之匹配的 catch 块。 catch 块的参数类型应与 throw 抛出的异常类型一致。
try {
// Code that may throw an exception
} catch (const std::runtime_error& e) {
// Handle std::runtime_error exceptions
std::cerr << "Runtime error: " << e.what() << std::endl;
} catch (const std::exception& e) {
// Catch-all for any other exception derived from std::exception
std::cerr << "Exception: " << e.what() << std::endl;
}
在上述代码中,如果抛出了 std::runtime_error 类型的异常,则会被第一个 catch 块捕获;如果是其他从 std::exception 派生的异常类型,则会被第二个 catch 块捕获。如果没有任何 catch 块匹配,则程序会调用 std::terminate() 函数,通常会立即终止程序。
6.1.2 标准异常类及其使用
C++标准库中定义了一系列标准异常类,这些类都继承自 std::exception 。包括 std::runtime_error 、 std::logic_error 、 std::out_of_range 等,它们为处理各种常见错误情况提供了方便。
标准异常类的层次结构
| 继承层次 | 类型 | |-----------|------| | std::exception | 最顶层的标准异常类 | | std::runtime_error | 仅在运行时可以检测到的错误 | | std::logic_error | 逻辑错误,可通过检查发现的错误 | | std::out_of_range | 表示值超出了有效范围 | | ... | 更多标准异常类 |
使用标准异常类
使用标准异常类时,通常不需要从它们继承。可以直接抛出和捕获这些类的实例,传递给 what() 方法的字符串,作为错误信息的一部分。
try {
if (some_condition) {
throw std::out_of_range("Value is out of allowed range");
}
} catch (const std::out_of_range& e) {
std::cerr << "Caught an out-of-range exception: " << e.what() << std::endl;
}
以上代码中,如果 some_condition 为真,则会抛出一个 std::out_of_range 异常。在对应的 catch 块中,可以获取到具体的异常信息,并进行处理。
6.2 自定义异常与异常安全编程
虽然标准异常类能够满足大多数错误处理的需求,但在某些情况下,需要定义自己的异常类以提供更具体的信息或行为。
6.2.1 设计自定义异常类
设计自定义异常类时,一般建议继承自 std::exception 或者其派生类。这样可以利用已有的功能,如提供错误信息的 what() 方法。
自定义异常类结构
class MyCustomException : public std::runtime_error {
public:
MyCustomException(const std::string& message)
: std::runtime_error(message) {}
};
上述自定义异常类 MyCustomException 继承自 std::runtime_error 。构造函数接受一个字符串参数,用于提供异常信息。
使用自定义异常
try {
// Code that may throw MyCustomException
} catch (const MyCustomException& e) {
std::cerr << "Caught a MyCustomException with message: " << e.what() << std::endl;
}
在此代码段中,如果抛出了 MyCustomException 异常,则会被相应的 catch 块捕获,并输出异常信息。
6.2.2 异常安全保证和资源管理策略
异常安全保证是编写健壮C++代码的一个重要方面。它指的是在程序发生异常时,能够保证程序的正确性,特别是对资源的管理。
异常安全保证的级别
C++标准定义了三个异常安全保证级别:
- 基本保证:在异常发生时,对象处于一个有效的状态,但资源可能已经泄漏。
- 强烈保证:在异常发生时,对象保持原有状态,或者如果无法恢复,则程序安全退出。
- 不抛出保证:承诺在函数内不会抛出异常。
使用RAII管理资源
资源获取即初始化(RAII)是一种资源管理技术,通过对象的构造函数和析构函数来管理资源。利用RAII,可以确保即使在发生异常的情况下,资源也会被正确释放。
class ResourceGuard {
public:
ResourceGuard() { /* 初始化资源 */ }
~ResourceGuard() { /* 释放资源 */ }
// 其他方法
};
void someFunction() {
ResourceGuard rg; // 构造函数初始化资源
// 函数体
// rg的析构函数将在函数退出时调用,释放资源
}
在上述例子中, ResourceGuard 类的对象 rg 在创建时分配资源,在析构时释放资源。无论 someFunction 中的代码是否抛出异常, rg 的析构函数都会确保资源被正确释放。
在处理异常时,如果遵循良好的RAII实践,就可以简化异常安全保证的实现。确保在异常发生时,所有资源都会被正确释放,并且程序状态保持一致。
7. 输入输出流操作与预处理器的应用
7.1 标准输入输出流与文件操作
在C++中,输入输出流是程序与外界进行数据交换的主要手段。标准输入输出流处理了大多数的输入输出任务,而文件操作则扩展了数据交换到磁盘等存储介质上。
7.1.1 cin、cout和cerr的高级用法
cin 、 cout 和 cerr 是C++中最基本的标准输入输出流对象,分别用于标准输入、标准输出和标准错误输出。
-
cin用于从标准输入设备(通常是键盘)读取输入数据。 -
cout用于输出数据到标准输出设备(通常是控制台)。 -
cerr用于输出错误信息到标准错误输出,通常也是控制台,但区别于cout的是,cerr不会缓存输出内容。
C++提供了一个强大的流操纵符来增强 cin 和 cout 的功能。例如:
#include <iostream>
using namespace std;
int main() {
int num;
cout << "Enter an integer: ";
cin >> num; // 输入整数
// 使用操纵符设置输出格式
cout << "The entered number is: " << num << endl;
cout << boolalpha << (num % 2 == 0) << endl; // 输出布尔值为文字
cerr << "An error occurred!" << endl; // 输出错误信息
return 0;
}
以上代码片段展示了如何通过操纵符 boolalpha 改变布尔值的输出格式,并通过 endl 自动添加换行符并刷新输出缓冲区。
7.1.2 文件输入输出流的处理
文件输入输出流是通过 <fstream> 头文件中的 ifstream 和 ofstream 类来处理的。这些类封装了标准C语言的文件操作函数,使得文件操作更简便和安全。
-
ifstream用于从文件读取数据。 -
ofstream用于向文件写入数据。
例如,以下代码展示了如何创建文件输出流,并将数据写入文件:
#include <fstream>
#include <iostream>
using namespace std;
int main() {
ofstream outfile;
outfile.open("output.txt", ios::out | ios::app); // 创建并打开文件以追加内容
if (outfile.is_open()) {
outfile << "Hello, World!" << endl;
outfile << "This is a test file." << endl;
outfile.close(); // 关闭文件
} else {
cerr << "Unable to open file!" << endl;
}
return 0;
}
7.2 预处理器的命令与宏定义
预处理器是C++编译过程中一个重要的阶段,它在编译代码前对源代码进行处理。预处理器的命令用于实现条件编译、宏定义等操作。
7.2.1 #include、#define的深入解析
#include 命令用于包含头文件,使得其他编译单元可以使用同一段代码。它有两种形式:
-
#include <header-file>:包含标准库头文件。 -
#include "header-file":包含用户自定义的头文件。
#define 命令用于定义宏,以便在编译之前对源代码进行文本替换。
-
#define MACRO_NAME replacement_text:将所有宏名称替换为给定的替换文本。 -
#define MACRO_NAME(parameter1, parameter2, ...) replacement_text:定义带参数的宏。
例如:
#define PI 3.14159
#define SQUARE(x) ((x) * (x))
cout << "The area of a circle with radius 2 is: " << PI * 2 * 2 << endl;
cout << "The square of 2 is: " << SQUARE(2) << endl;
7.2.2 条件编译指令的使用与实例
条件编译允许程序的某些部分根据特定的编译条件进行编译。最常用的预处理器指令有 #ifdef 、 #ifndef 、 #else 和 #endif 。
例如,可以使用条件编译来防止头文件被重复包含:
// 假设这是 a.h 文件
#ifndef A_H
#define A_H
void function_a();
#endif // A_H
// 在其他文件中使用 a.h
#include "a.h"
// 如果 a.h 已经被包含,那么预处理器指令将防止再次包含
// a.cpp
#include "a.h"
void function_a() {
// A_H 宏未定义,因此 a.h 的内容被包含
}
// b.cpp
#include "a.h"
// 由于 A_H 已定义,a.h 的内容不会被再次包含
上述代码片段通过 #ifndef 防止 a.h 文件内容的重复包含,避免了潜在的重复定义错误。
总结
在本章中,我们深入探讨了C++中的输入输出流操作和预处理器的应用。标准输入输出流为与控制台的数据交换提供了便捷,同时文件流类提供了对文件操作的直观支持。预处理器指令为编译过程提供了额外的灵活性,通过宏定义和条件编译来增强代码的可配置性和可维护性。这些知识对于开发复杂的应用程序和库是必不可少的,为高效编程提供了坚实的基础。
简介:郑丽版C++课件是一套专为初学者和进阶者设计的教程,涵盖了C++的核心概念、语法和编程实践。通过理论与实例结合的教学方式,让学习者能够深入理解数据类型、控制结构、面向对象编程、函数、异常处理、I/O流、预处理器、模板和STL等关键知识点。本课件旨在帮助学生建立起扎实的C++编程基础,并提高编程思维和问题解决能力。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









