






今天惠风和畅,天气晴朗,正是写代码的好时候,今天就用java来爬爬知乎。
爬取网址: https://www.zhihu.com/roundtable/jiqiganzhi/questions
所用语言: java
所用工具: Jsoup、phantomjs
总所周知,知乎有很多的圆桌,可以理解为一个个的专栏。今天要爬的是“人工智能”圆桌如图
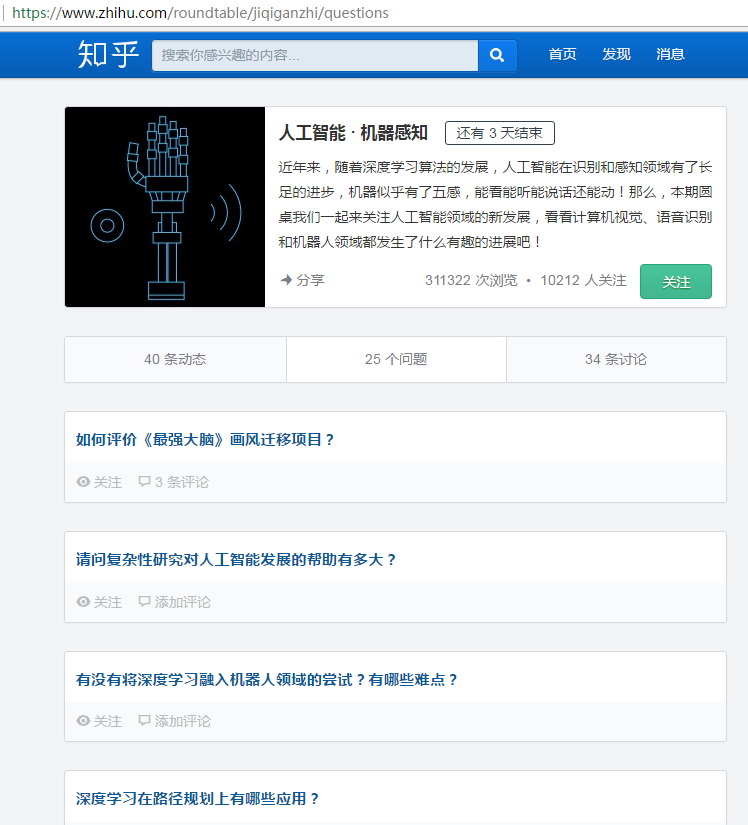
如图,这个圆桌下有25个问题,这些问题下有很多的回答,而这些正是我们的爬取目标。
流程: 专栏 -> 爬取出该专栏下25个问题的网址和问题名 -> 对每个问题爬取出每个回答的答主的名字、内容、发布时间
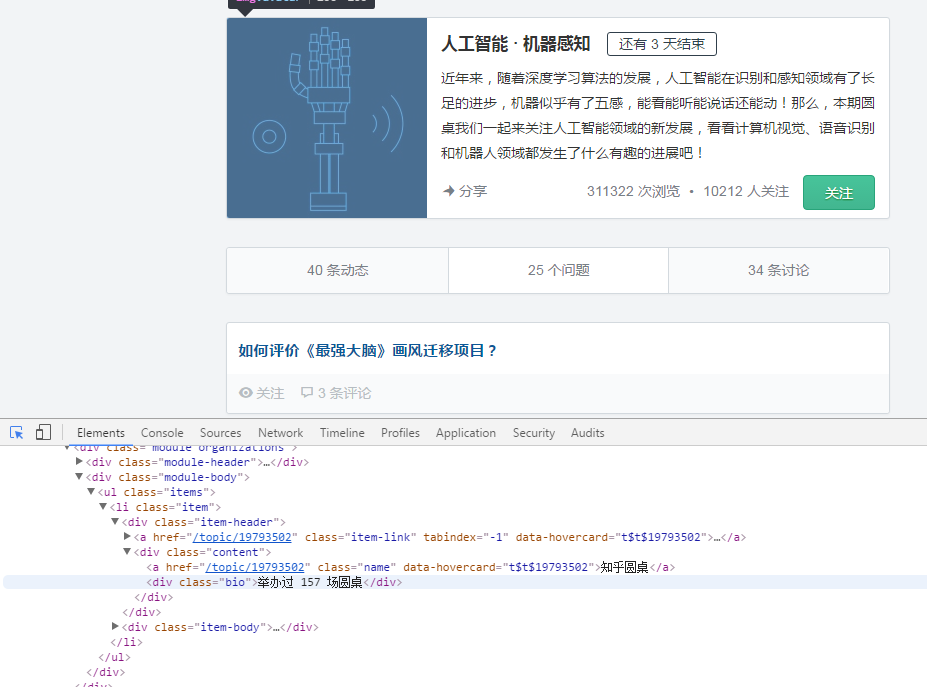
先是爬出问题的名字和网址,和以往一样,右键检查,点击左上角的鼠标按键。
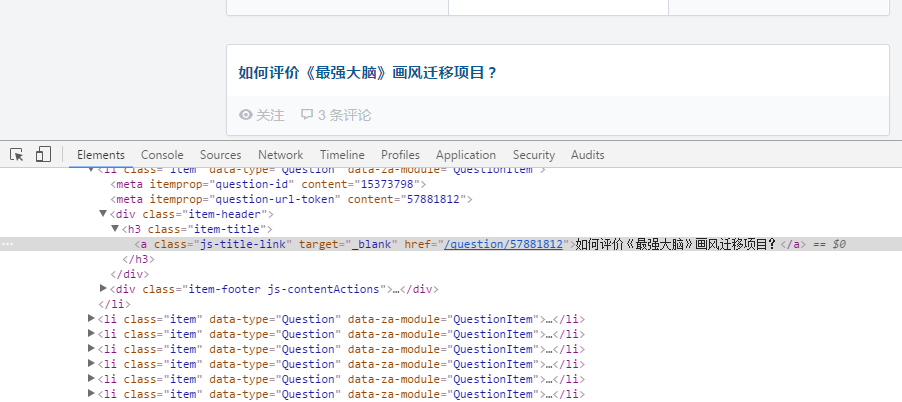
找出来发现问题和网址都是在h3标签下的"class=item-title",只要找到了就可以用select去得到我们想要的信息
得出代码
String url="https://www.zhihu.com/roundtable/jiqiganzhi/questions";
Document document = Jsoup.connect(url).userAgent("Chrome Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36").get();
Elements elements=document.select(".item-title");
代码中的userAgent是表示模拟浏览器,浏览器的userAgent可以打开http://service.spiritsoft.cn/ua.html去获取(低级的浏览器是无法正常打开知乎的)
筛选出来的Elements可以用一个循环去处理
for (Element element : elements) {
BufferedWriter out=new BufferedWriter(new FileWriter("C:\\Users\\user\\Desktop\\123\\"+(n++)+".txt"));
String title=element.text(); //问题
String wet="https://www.zhihu.com"+element.select("a").attr("href").trim(); //网站
if(wet.length()>"https://www.zhihu.com/question/56567517".length()) wet=wet.substring(0,"https://www.zhihu.com/question/56567517".length());
Link.add(wet);
out.write(title);
System.out.println((n-1)+".txt"+title);//输出爬取到的文章标题
out.newLine();
out.flush();
}我们将标题和网址都提取出来,标题title写入到文本文档里,将网址写入到队列Link中。其中标题我还输出到控制台看看Queue Link=new LinkedList(); //队列Link的声明
就这样获取到了圆桌下所有问题和其网址
接下来就是每个问题的回答的提取,这里举其中一个问题为例子"请问复杂性研究对人工智能发展的帮助有多大"
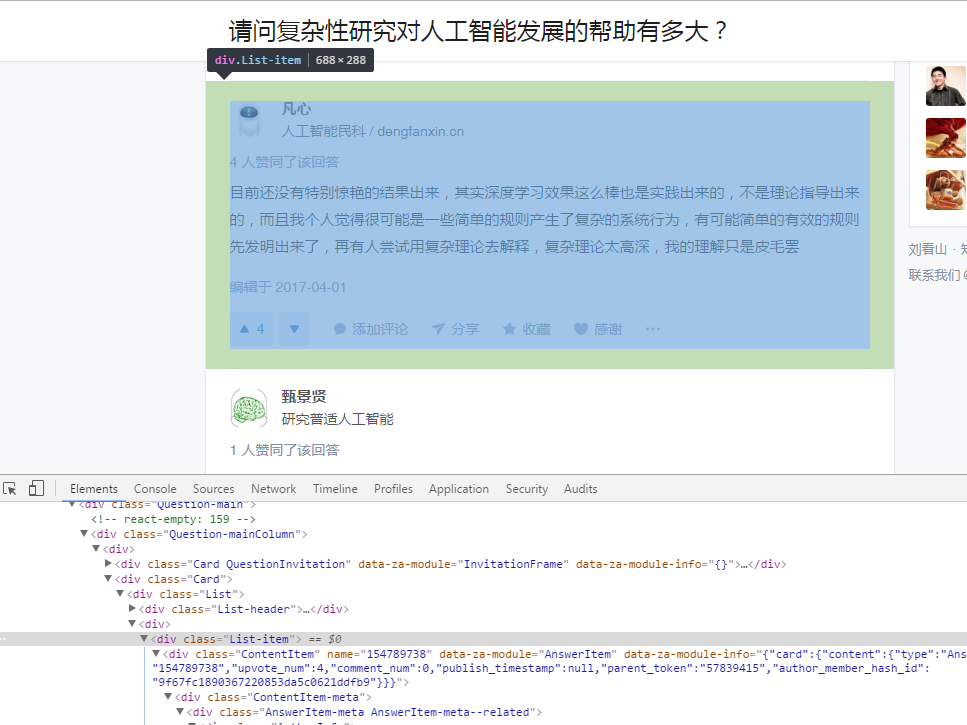
同样方法得到一个答主的所有回答信息都是在div标签下的"class=List-item"中,通过这个我们能筛选出每个答主的回答信息Elements elementN = document2.select(".List-item");然后再逐步剖析
先是答主的名字
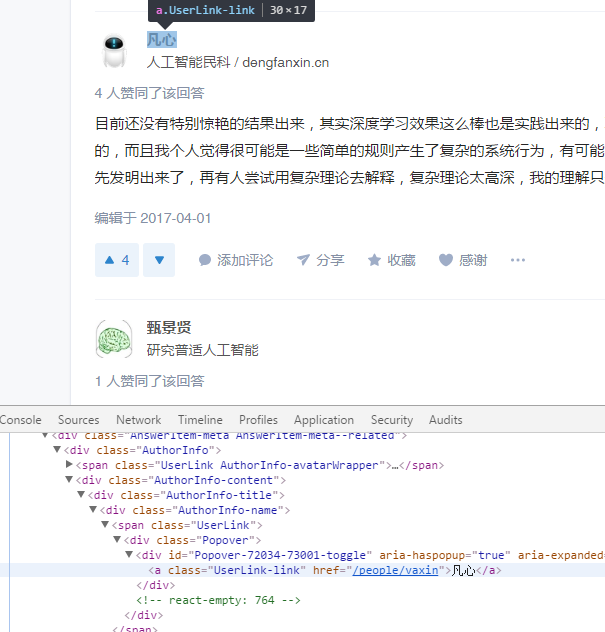
发现答主的名字都是在a标签下的"class=UserLink-link"中
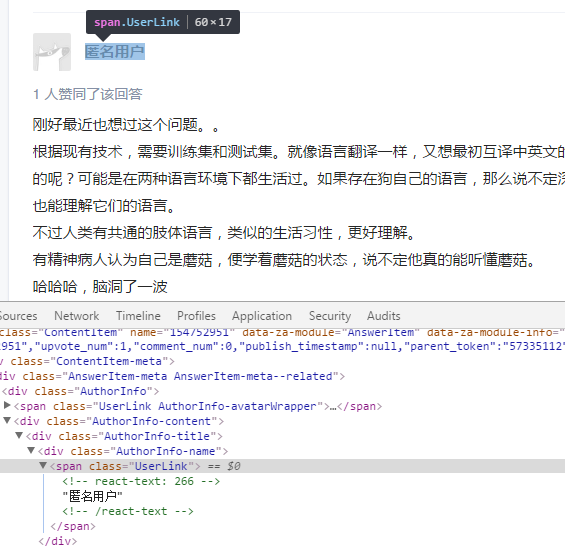
而有些匿名用户是在span中的"class=UserLink",所以要对此做一个条件
String name = element.select("a.UserLink-link").text();
if(name.length()==0) name=element.select("span.UserLink").text(); //若是找不到名字说明为匿名用户 就换个标签去找
然后到内容,同样道理
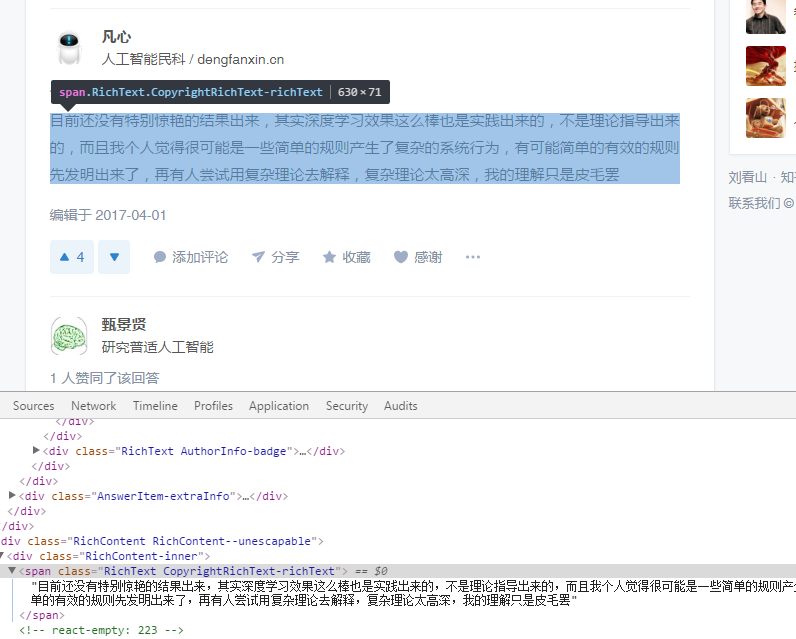
发现内容是在span标签下的"class=RichText.CopyrightRichText-richText"中,所以得到代码
String txt = element.select(".RichContent-inner").select(".RichText.CopyrightRichText-richText").text();//有时要select两次才能精确得到
发布时间就不做演示是一样道理的
String Time = element.select(".ContentItem-time").select("a").text();
全部得到完以后就将其写入到对应问题下的文本文档中
最后代码如下
Elements elementN = document2.select(".List-item");
for (Element element : elementN) {
BufferedWriter out2 = new BufferedWriter(new FileWriter("C:\\Users\\user\\Desktop\\123\\"+n+".txt", true));
String name = element.select("a.UserLink-link").text();
if(name.length()==0) name=element.select("span.UserLink").text();
out2.newLine();
out2.write("作者:" + name);
out2.newLine();
String txt = element.select(".RichContent-inner").select(".RichText.CopyrightRichText-richText").text();
out2.write("内容:" + txt);
out2.newLine();
String Time = element.select(".ContentItem-time").select("a").text();
out2.write(Time);
out2.newLine();
out2.newLine();
out2.flush();
}写入进去美滋滋
为了能更快的去爬取,所以我采用了多线程的方法,但是对于知乎有个问题,知乎是具有反爬虫机制的,一旦对其进行过快的访问就会抛出异常。而且在爬取的过程中发现这样去爬会导致只能抓取到前两个答主的回答,看图
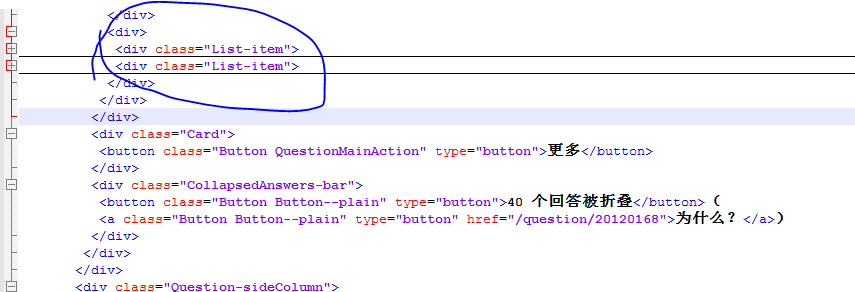
自己抓取到的网页源码是只有两个答主的
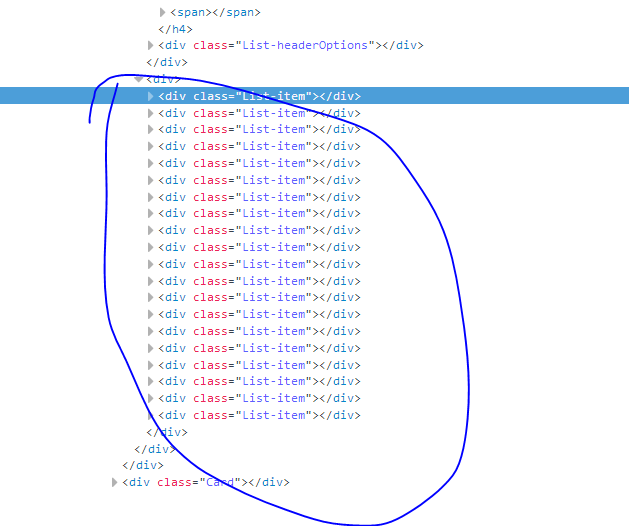
但是网页上的源码是有很多的
这涉及到了ajax的问题。大家有兴趣的可以去百度一下ajax,为了解决这个问题我也上网查了好久,终于被我发现了一个牛逼的东西那就是phantomjs(大家自行去下载)。
要能使用这个软件我们还需要去配置其环境变量,不过配置很简单网上一查都有。
我们还需要去写一些JavaScript的代码,先写在一个txt文件中然后转成js的格式即可,这里我命名为code1.js
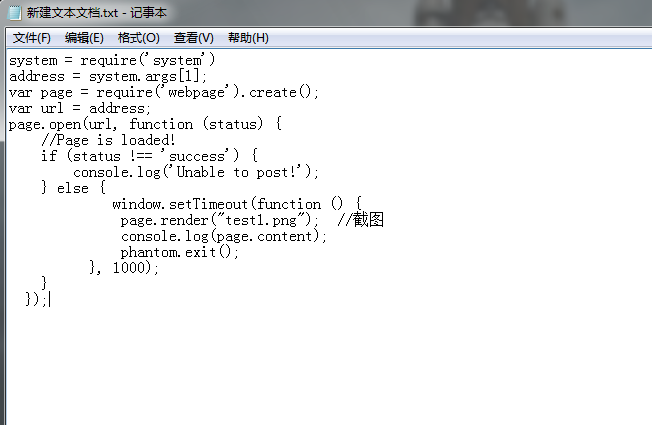
这是代码 我也是摘录自一个博客的代码http://www.jianshu.com/p/96220e239c35 大家可以去看看
 直接改名为code1.js即可
直接改名为code1.js即可
然后用几行代码去使用它
Runtime rt = Runtime.getRuntime();
String exec = "C:\\Users\\user\\Desktop\\phantomjs-2.1.1-windows\\bin\\phantomjs C:\\Users\\user\\Desktop\\phantomjs-2.1.1-windows\\bin\\code1.js " + urlNice;
Process p = rt.exec(exec);
InputStream is = p.getInputStream();
Document document2= Jsoup.parse(is,"UTF-8",urlNice);这样我们就可以获得真正的网页源码
跑出来如图

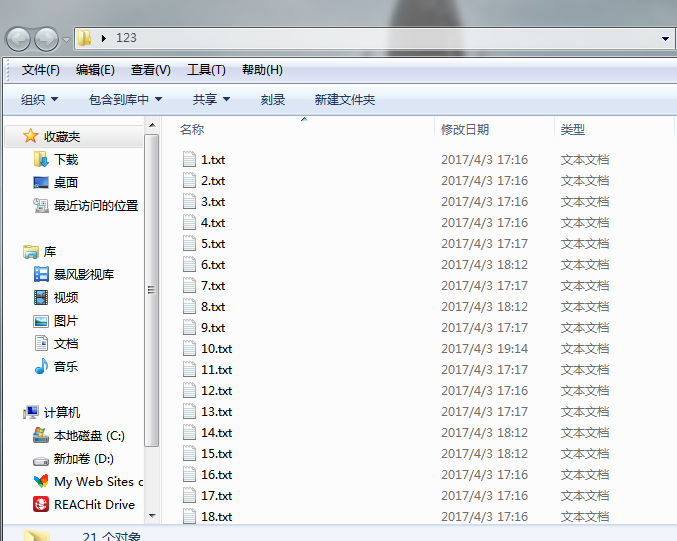
最后的源码就不公开了,大家想要的来私信我吧















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









