







使用 Pipcook 识别图片中的前端组件
前言
为了让大家更好地学习 Pipcook 和机器学习,我们准备了实战系列教程,会分别从前端组件识别、图片风格迁移、AI 作诗以及博客自动分类,这几个具体示例来讲解如何在我们日常开发中使用 Pipcook,如果需要了解 Pipcook 1.0,请前往我们的官方仓库
背景
您是否在前端业务中遇到过这样的场景:手中有一些图片,您想有一种自动的方式来识别这些图片这个图片里都包含哪些组件,这些组件都在图片的什么位置,属于哪种类型的组件,这种类型的任务一般在深度学习领域称为目标检测。
目标检测与识别是指从一幅场景(图片)中找出目标,包括检测(where) 和识别(what) 两个过程
这种检测是非常有用的,例如,在图片生成代码的研究里,前端代码主要就是由 div, img, span 组成的,我们可以识别图片里的形状,位图,和文本的位置,然后直接生成相应的描述代码即可。
这篇教程将会教你如何训练出一个模型来做这样一个检测任务。
场景示例
举个例子,如下图所示,这个图片包含着多个组件,包括按钮,开关,输入框等,我们想要识别出他们的位置和类型:

对于训练好的模型来说,在输入这张图片之后,模型会输出如下的预测结果:
{
boxes: [
[83, 31, 146, 71], // xmin, ymin, xmax, ymax
[210, 48, 256, 78],
[403, 30, 653, 72],
[717, 41, 966, 83]
],
classes: [
0, 1, 2, 2 // class index
],
scores: [
0.95, 0.93, 0.96, 0.99 // scores
]
}同时,我们会在训练的时候生成 labelmap,labelmap 是一个序号和实际类型的一个映射关系,这个的生成主要是由于现实世界我们的分类名是文本的,但是在进入模型之前,我们需要将文本转成数字。下面就是一个 labelmap:
{
"button": 0,
"switch": 1,
"input": 2
}我们对上面的预测结果做一个解释:
- boxes:这个字段描述的是识别出来的每一个组件的位置,按照左上角和右下角的顺序展示,如 [83, 31, 146, 71],说明这个组件左上角坐标为 (83, 13), 右下角坐标为 (146, 71)
- classes: 这个字段描述的是每一个组件的类别,结合 labelmap,我们可以看出识别出来的组件分别为按钮,开关,输入框和输入框
- scores: 识别出来的每一个组建的置信度,置信度是模型对于自己识别出来的结果有多大的信息,一般我们会设置一个阈值,我们只取置信度大于这个阈值的结果
数据准备
当我们想要做这样一个目标检测的任务时,我们需要按照一定规范制作,收集和存储我们的数据集,当今业界主要有两种目标检测的数据集格式,分别是 Coco 数据集 和 Pascal Voc 数据集, 我们也分别提供了相应的数据收集插件来收集这两种格式的数据,下面我们以 Pascal voc 格式举例,文件目录为:
train
|- 1.jpg
|- 1.xml
|- 2.jpg
|- 2.xml
|- ...
validation
|- 1.jpg
|- 1.xml
|- 2.jpg
|- 2.xml
|- ...
test
|- 1.jpg
|- 1.xml
|- 2.jpg
|- 2.xml
|- ...我们需要按照一定比例把我们的数据集分成训练集 (train),验证集 (validation) 和测试集 (test),其中,训练集主要用来训练模型,验证集和测试集用来评估模型。验证集主要用来在训练过程中评估模型,以方便查看模型过拟合和收敛情况,测试集是在全部训练结束之后用来对模型进行一个总体的评估的。
对于每一张图片,Pascal Voc 都指定有一个 xml 注解文件来记录这个图片里有哪些组件和每个组件的位置,一个典型的 xml 文件内容为:
<?xml version="1.0" encoding="UTF-8"?>
<annotation>
<folder>less_selected</folder>
<filename>0a3b6b38-fb11-451c-8a0d-b5503bc351e6.jpg</filename>
<size>
<width>987</width>
<height>103</height>
</size>
<segmented>0</segmented>
<object>
<name>buttons</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>83</xmin>
<ymin>31.90625</ymin>
<xmax>146</xmax>
<ymax>71.40625</ymax>
</bndbox>
</object>
<object>
<name>switch</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>210.453125</xmin>
<ymin>48.65625</ymin>
<xmax>256.453125</xmax>
<ymax>78.65625</ymax>
</bndbox>
</object>
<object>
<name>input</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>403.515625</xmin>
<ymin>30.90625</ymin>
<xmax>653.015625</xmax>
<ymax>72.40625</ymax>
</bndbox>
</object>
<object>
<name>input</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>717.46875</xmin>
<ymin>41.828125</ymin>
<xmax>966.96875</xmax>
<ymax>83.328125</ymax>
</bndbox>
</object>
</annotation>这个 xml 注解文件主要由以下几个部分组成:
- folder / filename: 这两个字段主要定义了注解对应的图片位置和名称
- size: 图片的宽高
- object:
- name: 组件的类别名
- bndbox: 组件的位置
我们已经准备好了一个这样的数据集,您可以下载下来查看一下:下载地址
开始训练
在准备好数据集之后,我们就可以开始训练了,使用 Pipcook 可以很方便的进行目标检测的训练,您只需搭建下面这样的 pipeline,
{
"plugins": {
"dataCollect": {
"package": "@pipcook/plugins-object-detection-pascalvoc-data-collect",
"params": {
"url": "http://ai-sample.oss-cn-hangzhou.aliyuncs.com/pipcook/datasets/component-recognition-detection/component-recognition-detection.zip"
}
},
"dataAccess": {
"package": "@pipcook/plugins-coco-data-access"
},
"modelDefine": {
"package": "@pipcook/plugins-detectron-fasterrcnn-model-define"
},
"modelTrain": {
"package": "@pipcook/plugins-detectron-model-train",
"params": {
"steps": 100000
}
},
"modelEvaluate": {
"package": "@pipcook/plugins-detectron-model-evaluate"
}
}
}通过上面的插件,我们可以看到分别使用了:
- @pipcook/plugins-object-detection-pascalvoc-data-collect 这个插件用于下载 Pascal Voc 格式的数据集,主要,我们需要提供 url 参数,我们提供了上面我们准备好的数据集地址
- @pipcook/plugins-coco-data-access 我们现在已经下载好了数据集,我们需要将数据集接入成后续模型需要的格式,由于我们模型采用的 detectron2 框架需要 coco 数据集格式,所以我们采用此插件
- @pipcook/plugins-detectron-fasterrcnn-model-define 我们基于 detectron2 框架构建了 faster rcnn 模型,这个模型在目标检测的精准度方面有着非常不错的表现
- @pipcook/plugins-detectron-model-train 这个插件用于启动所有基于 detectron2 构建的模型的训练,我们设置了 iteration 为 100000,如果您的数据集非常复杂,则需要调高迭代次数
- @pipcook/plugins-detectron-model-evaluate 我们使用此插件来进行模型训练效果的评估,只有提供了 test 测试集,此插件才会有效,最终给出的是各个类别的 average precision
由于目标监测模型,尤其是 rcnn 家族的模型非常大,需要在有 nvidia gpu 并且 cuda 10.2 环境预备好的机器上进行训练:
pipcook run object-detection.json --verbose --tuna模型在训练的过程中会实时打印出每个迭代的 loss,请注意查看日志确定模型收敛情况:
[06/28 10:26:57 d2.data.build]: Distribution of instances among all 14 categories:
| category | #instances | category | #instances | category | #instances |
|:------------:|:-------------|:-----------:|:-------------|:----------:|:-------------|
| tags | 3114 | input | 2756 | buttons | 3075 |
| imagesUpload | 316 | links | 3055 | select | 2861 |
| radio | 317 | textarea | 292 | datePicker | 316 |
| rate | 292 | rangePicker | 315 | switch | 303 |
| timePicker | 293 | checkbox | 293 | | |
| total | 17598 | | | | |
[06/28 10:28:32 d2.utils.events]: iter: 0 total_loss: 4.649 loss_cls: 2.798 loss_box_reg: 0.056 loss_rpn_cls: 0.711 loss_rpn_loc: 1.084 data_time: 0.1073 lr: 0.000000
[06/28 10:29:32 d2.utils.events]: iter: 0 total_loss: 4.249 loss_cls: 2.198 loss_box_reg: 0.056 loss_rpn_cls: 0.711 loss_rpn_loc: 1.084 data_time: 0.1073 lr: 0.000000
...
[06/28 12:28:32 d2.utils.events]: iter: 100000 total_loss: 0.032 loss_cls: 0.122 loss_box_reg: 0.056 loss_rpn_cls: 0.711 loss_rpn_loc: 1.084 data_time: 0.1073 lr: 0.000000训练完成后,会在当前目录生成 output,这是一个全新的 npm 包,那么我们首先安装依赖:
cd output
BOA_TUNA=1 npm install安装好环境之后,我们就可以开始预测了:
const predict = require('./output');
(async () => {
const v1 = await predict('./test.jpg');
console.log(v1);
// {
// boxes: [
// [83, 31, 146, 71], // xmin, ymin, xmax, ymax
// [210, 48, 256, 78],
// [403, 30, 653, 72],
// [717, 41, 966, 83]
// ],
// classes: [
// 0, 1, 2, 2 // class index
// ],
// scores: [
// 0.95, 0.93, 0.96, 0.99 // scores
// ]
// }
})();注意,给出的结果包含三个部分:
- boxes: 此属性是一个数组,每个元素是另一个包含四个元素的数组,分别是 xmin, xmax, ymin, ymax
- scores:此属性是一个数组,每个元素是对应的预测结果的置信度
- classes:此属性是一个数组,每个元素是对应的预测出来的类别
制作自己的数据集
看完上面的描述,你是否已经迫不及待想要用目标检测解决自己的问题了呢,要想制作自己的数据集,主要有以下几步
收集图片
这一步比较好理解,要想有自己的训练数据,您需要先想办法收集到足够的训练图片,这一步,您不需要让您自己的图片有相应的标注,只需要原始的图片进行标注就好
标注
现在市面上有很多的标注工具,您可以使用这些标注工具在您原始的图片上标注出有哪些组件,每个组件的位置和类型是什么,下面我们拿 labelimg 为例,详细的介绍一下
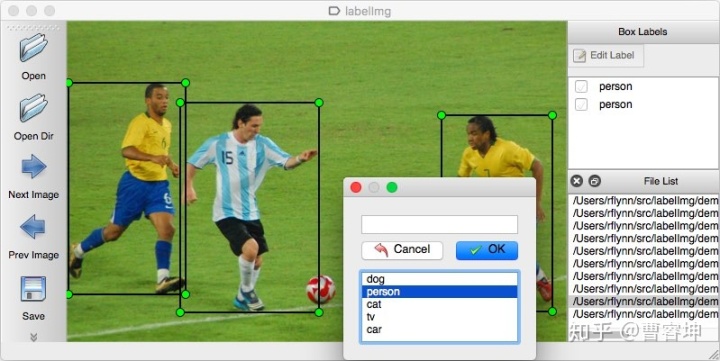
您可以先从上面的 labelimg 官网上安装软件,然后按照以下步骤操作:
- 按照官网的说明进行构建和启动。
- 在菜单/文件中单击“更改默认保存的注释文件夹”
- 点击“打开目录”
- 点击“创建RectBox”
- 单击并释放鼠标左键以选择一个区域来标注矩形框
- 您可以使用鼠标右键拖动矩形框来复制或移动它
训练
在制作好上面的数据集之后,根据之前的章节中的介绍组织文件结构,之后,就可以启动 pipeline 进行训练了,赶快开始吧。
总结
读者到这里已经学会如识别一张图片中的多个前端组件了,可以适用于一些更加通用的场景了。那么在一篇,我们会介绍一个更有趣的例子,就是如何使用 Pipcook 实现图片风格迁移,比如将图片中的橘子都替换称苹果,或者将写实的照片风格替换为油画风格等。














 1338
1338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









