






近期在看CF的相关论文,《Collaborative Filtering for Implicit Feedback Datasets》思想非常好,非常easy理解。可是从目标函数
是怎样推导出Xu和Yi的更新公式的推导过程却没有非常好的描写叙述。所以以下写一下
推导:
首先对Xu求导:
当中Y是item矩阵,n*f维,每一行是一个item_vec,C^u是n*n维的对角矩阵。
对角线上的每个元素是c_ui,P(u)是n*1的列向量,它的第i个元素为p_ui。
然后令导数=0,可得:
因为x_u和y_i在目标函数中是对称的。所以非常easy得到:
当中X是user矩阵,m*f维度,每一行是一个user_vec,C^i是m*m的对角矩阵。对角线上的每个元素是c_ui。P(i)是m*1的列向量。它的第u和元素是p_ui
然后令导数=0,可得:
以下是论文算法思想的Python实现:
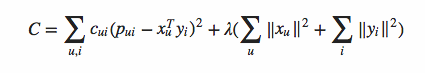
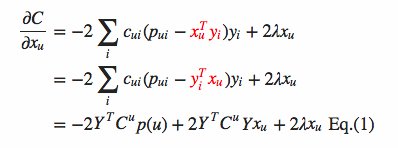
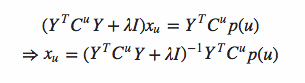
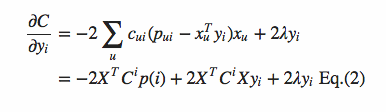
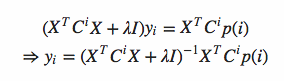
import numpy as np
import scipy.sparse as sparse
from scipy.sparse.linalg import spsolve
import time
def load_matrix(filename, num_users, num_items):
t0 = time.time()
counts = np.zeros((num_users, num_items))
total = 0.0
num_zeros = num_users * num_items
'''假设要对一个列表或者数组既要遍历索引又要遍历元素时。能够用enumerate,当传入參数为文件时,索引为
行号,元素相应的一行内容'''
for i, line in enumerate(open(filename, 'r')):
#strip()去除最前面和最后面的空格
user, item, count = line.strip().split('\t')
user = int(user)
item = int(item)
count = float(count)
if user >= num_users:
continue
if item >= num_items:
continue
if count != 0:
counts[user, item] = count
total += count
num_zeros -= 1
if i % 100000 == 0:
print 'loaded %i counts...' % i
#数据导入完成后计算稀疏矩阵中零元素个数和非零元素个数的比例,记为alpha
alpha = num_zeros / total
print 'alpha %.2f' % alpha
counts *= alpha
#用CompressedSparse Row Format将稀疏矩阵压缩
counts = sparse.csr_matrix(counts)
t1 = time.time()
print 'Finished loading matrix in %f seconds' % (t1 - t0)
return counts
class ImplicitMF():
def __init__(self, counts, num_factors=40, num_iterations=30,
reg_param=0.8):
self.counts = counts
self.num_users = counts.shape[0]
self.num_items = counts.shape[1]
self.num_factors = num_factors
self.num_iterations = num_iterations
self.reg_param = reg_param
def train_model(self):
#创建user_vectors和item_vectors,他们的元素~N(0,1)的正态分布
self.user_vectors = np.random.normal(size=(self.num_users,
self.num_factors))
self.item_vectors = np.random.normal(size=(self.num_items,
self.num_factors))
'''要生成非常大的数字序列的时候,用xrange会比range性能优非常多,
因为不须要一上来就开辟一块非常大的内存空间,这两个基本上都是在循环的时候用'''
for i in xrange(self.num_iterations):
t0 = time.time()
print 'Solving for user vectors...'
self.user_vectors = self.iteration(True, sparse.csr_matrix(self.item_vectors))
print 'Solving for item vectors...'
self.item_vectors = self.iteration(False, sparse.csr_matrix(self.user_vectors))
t1 = time.time()
print 'iteration %i finished in %f seconds' % (i + 1, t1 - t0)
def iteration(self, user, fixed_vecs):
#相当于C的三木运算符。if user=True num_solve = num_users,反之为num_items
num_solve = self.num_users if user else self.num_items
num_fixed = fixed_vecs.shape[0]
YTY = fixed_vecs.T.dot(fixed_vecs)
eye = sparse.eye(num_fixed)
lambda_eye = self.reg_param * sparse.eye(self.num_factors)
solve_vecs = np.zeros((num_solve, self.num_factors))
t = time.time()
for i in xrange(num_solve):
if user:
counts_i = self.counts[i].toarray()
else:
#假设要求item_vec,counts_i为counts中的第i列的转置
counts_i = self.counts[:, i].T.toarray()
''' 原论文中c_ui=1+alpha*r_ui,可是在计算Y’CuY时为了减少时间复杂度,利用了
Y'CuY=Y'Y+Y'(Cu-I)Y,因为Cu是对角矩阵,其元素为c_ui,即1+alpha*r_ui。
所以Cu-I也就是对角元素为alpha*r_ui的对角矩阵'''
CuI = sparse.diags(counts_i, [0])
pu = counts_i.copy()
#np.where(pu != 0)返回pu中元素不为0的索引,然后将这些元素赋值为1,不知道这里为什么要赋值为1?
pu[np.where(pu != 0)] = 1.0
YTCuIY = fixed_vecs.T.dot(CuI).dot(fixed_vecs)
YTCupu = fixed_vecs.T.dot(CuI + eye).dot(sparse.csr_matrix(pu).T)
xu = spsolve(YTY + YTCuIY + lambda_eye, YTCupu)
solve_vecs[i] = xu
if i % 1000 == 0:
print 'Solved %i vecs in %d seconds' % (i, time.time() - t)
t = time.time()
return solve_vecs















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









