







如何使用
需要安装 PHP 5.5+ 环境;
需要安装 php-pdo,php-mysql;
修改 combine_tool/etc/dbConfig.php 文件,修改狼服和羊服的配置。具体配置内容,可以参考:dbConfig.php.template 文件;
回到 combine_tool 目录执行:
php App_Combine.php
首先
这是一篇介绍“合服工具”的技术文档;
合服工具代码可以参考:https://git.oschina.net/afrxprojs/xgame-php_tool,
注意:合服工具使用 PHP 语言开发!为什么使用 PHP,我后面会简要说明;
该文档的主要目的是说明开发“合服工具”的思维过程,而不仅仅是使用说明!技术文档的价值在于过程而不是结论;
我假定你对游戏行业的技术岗位工作有所了解。如果你亲身参与过游戏合服工作,这篇文档阅读起来可能会比较轻松;
这是一篇不合规范的文档,所有符合规范的文档,没有人喜欢读……该文档以“轻松、易读、实用”作为规范;
在内容开始之前,我先简单的交代一下背景……
背景
假设我们的游戏服采用的是单服架构,即每个游戏服都有自己的数据库;
数据库我们使用的是 MySQL;
我们的合服工具必须能够一次合并 10 个游戏服,即,其中 1 个服务器吃掉另外 9 个;
但是运营给我们的时间最多只有 6 个小时,这是极限值。一般是在 4 个小时之内完成;
合服时,将服务器分为“狼服”和“羊服”。例如将 S2 服数据合并到 S1 服,即,S1 吃掉 S2。那么 S1 称作狼服,S2 称作羊服;
我所使用的最早的合服工具,一次只能合并 2 个游戏服(1 个狼服吃掉 1 个羊服)。而且合服时间最长的一次用了将近 8 个小时……随着新项目的迅速扩大以及运营需求标准的提高,早期的合服工具已经无法胜任,所以只好另行开发新工具。旧的合服工具在合并数据时,所采用的办法是从羊服读出单条数据,再将这条数据写入到狼服数据库。这种办法的确比较直观,但是效率实在太低了,而且合服过程一旦中断,是不能重启并接着合服的,否则数据就乱了。
我们必须改变原有思路,找到更快、更可靠的办法!
核心实现
经过反复思考,我决定利用 MySQL 的“insert into ... select ...”语法来批量插入数据,这样做的效率非常高,基本可以应对时间约束。这样一来我们也就可以确定一个核心思路:
利用批量插入!如果遇到问题,则尽量往这个思路上靠……
“利用批量插入!“,这句话很好理解。那么,“如果遇到问题,则尽量往这个思路上靠……”这句话该怎么理解呢?我曾经和一个同事打过一盘台球,他告诉我一个打台球的小技巧:如果当你没把握一杆就把球打进洞的时候,你就想办法让球慢慢往洞口靠拢。等球距离洞口很近了,你也就有把握了。技术实现又何尝不是这样呢?如果我们没有把握一下子搞定一个大系统,那么我们就想办法把这个大系统拆成若干个可以搞定的小系统,逐个击破不就可以了么……技术源于生活,却又高于生活。
在接下来的文字中,我们一点点亲历这样的过程。
分析
上一段文字中,我们确定了核心实现。接下来,我们对几个具体的业务模块进行分析。因为篇幅有限,所以我们只看 3 个业务模块:角色数据、单人副本、竞技场。之所以选这 3 个业务模块,是因为这几个模块比较有代表性,可以基本说明合服过程的设计思路。
接下来,我们分别对这 3 各个业务模块进行分析,从具体到抽象,提取出整个合服流程的设计思路。
角色数据
对于角色数据,在合服的时候大概要经历如下过程:
(图1)角色数据的合服流程
清理无用数据,就是把 30 天没登录的,并且角色等级小于指定等级的,并且没有冲过钱的,再并且不是军团长的角色数据给删除掉;
合并数据,就是把羊服数据合并到狼服,完成狼吃羊的过程。这一步我们就可以使用 insert into … select … 这个语法,进行批量插入;
这里需要注意的一个地方是,我们事先将无用数据清理完,再执行合并数据。而不是把有用的数据捡出来一条一条的合并过去……这符合我刚提到的思路:利用批量插入!
单人副本
对于单人副本这个业务模块,在合服的时候大概要经历如下过程:

(图2)单人副本的合服流程
单人副本的合服流程跟“角色数据”那个基本一样,甚至可以说是完全一样!单人副本模块,也需要事先清理无用数据,之后再合并数据。到这里,我们算是找到了两个模块在合服过程中的一些共同点。可以总结出如下流程图:

(图3)合服流程总览
但是这里面有一些问题,可能需要我们思考一下。
单人副本执行清理无用数据这一步,这“无用数据”指的是什么?应该是“角色数据”那一步被清理掉的数据!如果角色数据都已经不存在了,那么这个角色对应的单人副本数据无任何意义,所以也需要删除掉。那么清理工作执行到单人副本这一步的时候,如何知道有哪些角色数据被删除掉了呢?我们可以在执行“角色数据”清理的时候,使用一个数组变量把已删除的角色 Id 都记录下来。在清理单人副本的时候,从数组变量中取出角色 Id,用这个值作为单人副本数据是否需要删除的判断条件,这样就可以了……
这么做确实没错,但是存在两个问题:
这样做的效率比较低,而且需要额外占用内存;
如果第 1 点你不完全同意的话,那么如果应用程序中途出现异常被中断,这个保存着被删除角色的数组变量也就不复存在了。这无法保证程序的可靠性;
其实,技术设计不是需求驱动的,而是质疑驱动的。技术设计的一个根本方法是:举反例。在你想出一个设计方案之后,必须在一定范围之内禁得起质疑。我们可以使用穷举法尽可能找出这个方案的反例。不管思路有多么精妙,只要在一定范围内存在反例,那么设计就会被击翻。这种倒地击翻在设计阶段并不可怕,如果是在编码实现阶段才出现,那么所有人的体力劳动都会白费……其实,由于设计缺陷导致的代码完全推翻重做,并不多见。更为常见的情况是,维护或修复一个简单的功能或 Bug 也能让你花费好几天时间。
设计和科学一样,科学应该是可证伪的。
为了解决第 1 个问题,我们可以采用 MySQL 的 where … in … 的查询方式,而第 2 个问题,应用程序不是怕中断么?我就把变量写到磁盘上!这样,即便是中途宕机或者断电,我还是能知道有哪些角色被删除掉了。因为我把数据存在文件里了……让我们再仔细想想,有现成的 MySQL 数据库,往这里面存更方便!干嘛还要写到文件里呢?MySQL 数据库不是也可以看作是一个“文件”么?而且这样,我们使用 in 查询还更方便了。
为此,我们可以在羊服数据库中建立一张临时表,专门用来记录将要被删除的角色 Id,这个表只有一个字段,就是“角色 Id”。为了让整个过程更可靠,我们还可以把角色数据的清理过程放在最后,也就是说,先执行单人副本模块的数据清理过程,然后再执行角色数据的清理过程。

(图4)清理无用数据,调换单人副本和角色数据的执行顺序
我们的核心思路,经历了一次小的考验,倒没有太大问题,值得庆幸。不过,接下来的竞技场模块,就没这么幸运了……
竞技场
竞技场模块的合服流程也可以总结为“删除无用数据”及“合并数据”,流程图没什么两样,所以就不在这里画了。但是竞技场有个排名问题,这个问题非常棘手。我来具体说明一下:
假设,在 S1 服务器中的竞技场数据如下:
(表1)S1 服竞技场数据
再假设,在 S2 服务器中的竞技场数据如下:
(表2)S2 服竞技场数据
名字起的有点俗,能说明问题就好。在合服时,我们不能把竞技场数据全部清掉,让玩家重新来过。这样的结果运营是无法接受的。竞技场会根据排名,每天给玩家发一些奖励,所以清掉竞技场数据,众玩家也是不会答应的。比较合理的结果类似下面这样:
S1 服的第 1 名保持不变还排在第 1 的位置;
S2 服的第 1 名,排第 2;
S1 服的第 2 名,排第 3;
S2 服的第 2 名,排第 4;
结果就像这样:
(表3)S1、S2 合服结果,S1 为狼服,S2 为羊服
这是大家还都能接受的一个方案。为此,我们需要写一个算法,把 S1 的竞技场数据全部读出,把 S2 竞技场的数据也全部读出,然后排序,最后回写到 S1 服。这么做可以,但这实在是太麻烦了……
通过算法方式,并不符合我们最开始的核心思路:利用批量插入!所以,这个时候,我们执行第二套方针,如果遇到问题,则尽量往这个思路上靠……
我们试试,如果让 S1 服的排名数值都乘以 1.5 并取整,而让 S2 服的排名数值都乘以 2,最后再利用批量插入合并数据。怎么样?这真是一个很牛 B 的想法!
但这个想法实在是过于幼稚!我举一个反例,假设,S2 的排名数值实际上是不连续的,就像这样:
(表4)S2 服竞技场数据,带木桩
S2 服排行榜中,第 4 到第 8 名,都是木桩(假人)。这些木桩是为了保障竞技场模块刚开放给玩家的时候,不会让玩家一下子冲到第 1 名所设置的,而这些木桩数据,是不能参与合服的。也就是说最终的合服结果应该如下:
(表5)S1、S2 合服结果,S1 为狼服,S2 为羊服。S2 服的木桩数据不应被合并
所以修改排名数值再合服的方法是行不通的。如果竞技场里存在被清掉的角色,也会发生排名不连续的情况。如果我们通过算法来解决这个问题,那么算法的难度会相当高。
完了,遇到大问题了,框架流程到此打结了,无法继续进行了……
逆向思考
如果一个问题正向解决,难度太高了,那么就试试倒过来解决。其实前面的思路方式,已经是很大进步了。对于竞技场数据,我们就把数据先一股脑的合并过来,然后再对排名数值进行整理,又能怎么样呢?反正我们也有原数据,大不了回滚呗。数据合并完成之后,已经是在同一个 DB 中了,所以整理过程也会比较高效。即便算法在复杂,性能应该也不会差到哪去?
说到这个排名数值的算法,本质上不就是把每条数据按顺序读出来,更新一下排名数值,然后再更新到数据库。这不就是一个打标签的过程么,多么简单啊……
简单是简单,但是回想一下,还是需要写一些代码的。怎么着也得写个 for 循环,来更新每一条数据吧。有没有效率更高,更简单的办法呢?我们没法一下子做到的事情,我们可以用两下子做到。我们是不是可以建立一张临时表来存放新的排名数据?例如,我们建立这样的一张表:
create table `临时表`
(
`角色 Id` bigint,
`排名` int not null auto_increment,
primary key ( `角色 Id` ),
unique key ( `排名` )
);
然后通过 SQL 语句把角色 Id 插入到这张临时表里:
insert into `临时表` ( `角色 Id` )
select X.`角色 Id`
from `排行榜` as X
order by X.`排名` asc, X.`服务器名` asc;
因为临时表中的排名字段是自增的,所以数据插入之后,自然就会形成连续的排名。我们再通过一条 SQL 语句将临时表中的数据,回写到竞技场:
update `竞技场` as A, `临时表` as B
set A.`排名` = B.`排名`
where A.`角色 Id` = B.`角色 Id`;
得益于 MySQL 在 update 语法上支持关联查询,给我们省去了很大的工作量。至此,我们的核心思路再一次经受住考验。
总结
我们的整个框架,可以总结为这样三步:

(图5)
每个功能模块都可以通过这 3 步合服,我们还可以找更多的系统模块来验证,看看是否有反例。由于篇幅限制,我们就不在这里继续列举了。我们是否可以设计这样的一个框架,就由这 3 大步来组成,上层的控制模块用来控制该执行哪个大步骤。而且上层控制逻辑是不关心每个业务模块具体是怎么操作的,它只需要知道工作的流程。而每个具体的业务模块,只需要知道具体该怎么做,但是并不需要关心什么时候做?以后有新增的功能模块,也是按照这 3 大步来做,只要做好自己的本职工作就可以了……想想富士康手机生产线上的线工
这就是典型的执行过程与具体实现的分离,它其实是一个工作流(Work Flow)!
我们把系统的运行过程想象成一道洪流,洪流流到“清理无用数据”这一关,每个业务模块按照事先规定好的顺序,一个接一个的清理自己的数据。当最后一个业务模块清理完数据之后,系统的洪流向下流动,流到合并数据这一关。这时,每个业务模块又开始忙碌起来,按照顺序合并自己的数据。系统的洪流继续向下流动,流动到“数据整理”这一关,各个业务模块继续忙碌,直到全部结束……
具体实现
我们可以做出如下的类定义:

(图6)合服工具类定义
在合服工具的主控类中,规定了调用顺序。即,先调用“清理无用数据”类,再调用“合并数据”,最后调用“整理数据”。注意:这 3 个类都是抽象类,需要具体的实现!具体实现如下定义:

(图7)具体实现类
这一步也很好理解。我们可以做一步整理,比如把“清理无用数据”、“合并数据”、“整理数据”这三步的函数名都改成一样的!如图 8 所示:

(图8)将所有的函数名改为相同的名字
这一步只有目的的,之后,我们可以将“工作”函数提取到一个接口里。如图 9 所示:

(图9)提取“工作节点”接口
“合服工具主控类”,现在不再依赖“清理无用数据”、“合并数据”、“整理数据”这 3 个抽象类了。而是直接依赖“工作节点”接口!而且,这个接口只提供一个函数,就是“工作”。这样做的意义在于高度抽象,让主控类彻底摆脱具体实现!我们甚至可以干掉这 3 个抽象类,让具体类直接实现“工作节点”接口。如图 10 所示:

(图10)令具体实现类直接继承“工作节点”接口
这样,主控类无需知道有多少个具体实现,更无需知道他们具体是怎么实现的?最后我们要做的,就是把这些规整到不同目录下去,如图 11 所示:
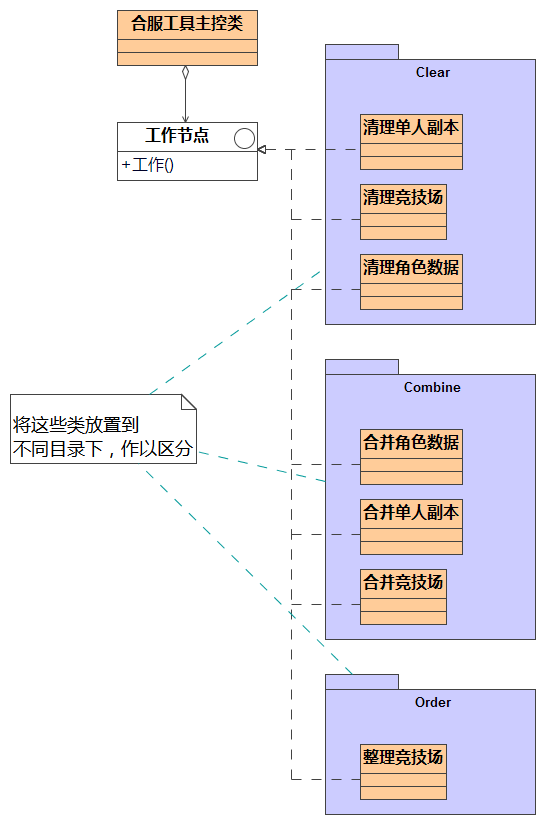
(图11)强具体实现类规整到不同目录中
主控类,只知道调用“Clear”、“Combine”、“Order”这 3 个目录里的“工作节点”实现类,而这些实现类都只有一个统一的命名的方法:“工作”。这样主控程序省了很大心。而对于每个具体的实现类,他们只要保证自己的工作是正确无误的就可以了……
看着图,回想一下之前提到的工作流(Work Flow),这就是一个具体实现过程!这是也是设计中的责任链模式。是用责任链模式的一大好处就是,我可以任意添加和删除工作节点,甚至是修改工作节点的链接顺序,但又不用修改大量代码。例如,我想在“Clear”和“Combine”这两大关之间增加一个“Fixed”用于修复一些错误的数据,那么,只要增加一个新目录,并增加“工作节点”的实现类,就可以了。其它代码根本不用动……当然,主控类还要稍微修改一下。
PHP
最后,再提一下 PHP 语言。合服工具使用 PHP 语言开发,不是因为 PHP 是世界上最好的语言(这话扔出来,不知道能不能拉点仇恨吸点流量)。而是因为PHP 语言的动态性可以满足易扩展的需求,它不像编译语言那样,每次更新的时候都需要编译和打包。PHP 可以直接修改代码。利用 PHP 的动态性和文件系统的目录结构,可以很轻松的实现合服框架代码。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









