






摘要:本文深入浅出的讲述了设计模式中的
解释器
模式
,
并给出了简单的示例
,
例子浅显易懂
,
并附带源代码。
<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" />
解释器模式属于行为型模式,其意图是给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。如果一种特定类型的问题发生的频率足够高,那么就可值得将该问题的各个实例表述为一个简单语言的句子,这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。解释器模式使用类来表达每一条文法规则,在规则右边的符号是这些类的实例变量。
适用性:
当有一个语言需要解释执行,并且你可将该语言中的句子表示为一个抽象语法树,可以使用解释器模式。而当存在以下情况时该模式效果最好
l
该文法的类层次结构变得庞大而无法管理。此时语法分析程序生成器这样的工具是最好的选择。他们无需构建抽象语法树即可解释表达式,这样可以节省空间而且还可能节省时间。
l
效率不是一个关键问题,最高效的解释器通常不是通过直接解释语法分析树实现的,而是首先将他们装换成另一种形式,例如,正则表达式通常被装换成状态机,即使在这种情况下,转换器仍可用解释器模式实现,该模式仍是有用的。
参与者:
AbstractException:
抽象表达式,声明一个抽象的解释操作,这个接口为抽象语法树中所有的节点所共享。
TerminalExpression:
终结符表达式。实现与文法中的终结符相关联的解释操作,一个句子中的每个终结符需要该类的一个实例。
NonterminalExpression:
非终结符表达式,对于文法中的每一条规则
R
::
=R1R2..
都需要一个
NonterminalExpression
类。为从
R1
到
Rn
的每个符号都维护一个
AbstractExpression
类型的实例变量。为文法中的非终结符实现解释操作,解释操作一般要递归地调用表示
R1
到
Rn
的那些对象的解释操作。
Context
:上下文,包含解释器需要解释的全局信息。
Client:
构建表示该文法定义的语言中一个特定的句子的抽象语法树。该抽象语法树由
NonterminalExpression
和
TerminalExpression
的实例装配而成。调用解释操作等。
协作
:
Client
构建一个句子,它是
NonterminalExpression
和
TerminalExpress
的实例的一个抽象语法树,然后初始化上下文并调用解释操作。然后初始化上下文并调用解释操作。
每一个非终结符表达式节点定义相应子表达式的解释操作。而各终结符表达式的解释操作构成了递归的基础。
每一节点的解释操作用上下文来存储和访问解释器的状态。
例如有文法表达式:
program::=commandlist
commandlist::=(space|print|break|linebreak|repeat|)*
repeat::=commandlist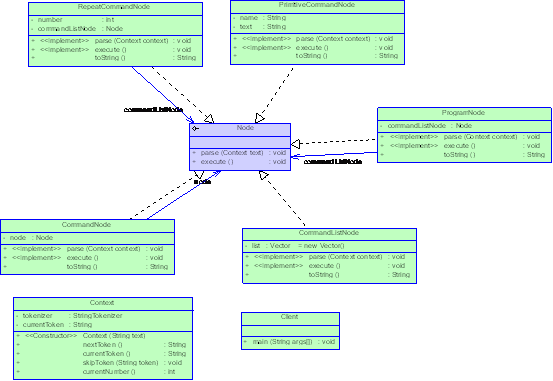
图1 文法解释器的类图
如果输入相应的程序代码为
PROGRAM REPEAT 4 LINEBREAK PRINT justin SPACE SPACE SPACE SPACE PRINT momor LINEBREAK END END
则可以通过解释器的解释执行。
相应的代码:
Node代码:
package
interpreter;
public
interface
Node{
public
void
parse(Context text);
public
void
execute();
}
Context代码:
package
interpreter;
import
java.util.*;
public
class
Context{
private
StringTokenizer
tokenizer
;
private
String
currentToken
;
public
Context(String text){
tokenizer
=
new
StringTokenizer(text);
nextToken();
}
public
String nextToken(){
if
(
tokenizer
.hasMoreTokens()){
currentToken
=
tokenizer
.nextToken();
}
else
{
currentToken
=
null
;
}
return
currentToken
;
}
public
String currentToken(){
return
currentToken
;
}
public
void
skipToken(String token){
if
(!token.equals(
currentToken
)){
System.
err
.println(
"Warning:"
+token+
" is Expected,but"
+
currentToken
+
" is found"
);
}
nextToken();
}
public
int
currentNumber(){
int
number = 0;
try
{
number = Integer.parseInt(
currentToken
);
}
catch
(NumberFormatException e){
System.
err
.println(
"Warning:"
+e);
}
return
number;
}
}
Client代码:
package interpreter;
import java.util.*;
import java.io.*;
public class Client{
public static void main(String[] args){
try{
BufferedReader reader = new BufferedReader(new FileReader("prog.txt"));
String text;
text = reader.readLine();
System.out.println(text);
Node node = new ProgramNode();
node.parse(new Context(text));
System.out.println("node = " + node);
node.execute();
}
catch(ArrayIndexOutOfBoundsException e){
System.err.println("Usage java interpreter.Client!");
}
catch(Exception e){
e.printStackTrace();
}
}
}
其余的代码不一一列举,请下载附件查看其余的代码。
总结:解释器模式为制作编译器提供了指导思路,在使用面向对象语言实现的编译器中得到了广泛的应用。
转载于:https://blog.51cto.com/tianli/41998















 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









