







一、简介
Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
特点:
- 简单、容易上手 (提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
- 灵活性高,可以自定义用户函数 (UDF) 和存储格式;
- 为超大的数据集设计的计算和存储能力,集群扩展容易;
- 统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
- 执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。
二、Hive的体系架构
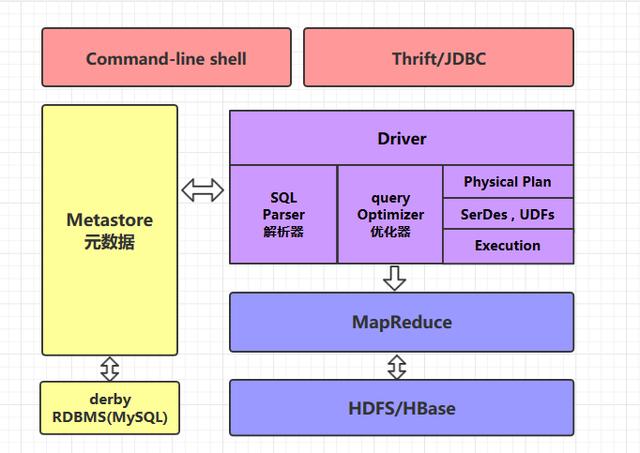
2.1 command-line shell & thrift/jdbc
可以用 command-line shell 和 thrift/jdbc 两种方式来操作数据:
- command-line shell
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









