







这个实战例子是构建一个大规模的异步新闻爬虫,但要分几步走,从简单到复杂,循序渐进的来构建这个Python爬虫
本教程所有代码以Python 3.6实现,不兼顾Python 2,强烈建议大家使用Python 3

要抓取新闻,首先得有新闻源,也就是抓取的目标网站。国内的新闻网站,从中央到地方,从综合到垂直行业,大大小小有几千家新闻网站。百度新闻(news.baidu.com)收录的大约两千多家。那么我们先从百度新闻入手。
打开百度新闻的网站首页:news.baidu.com
我们可以看到这就是一个新闻聚合网页,里面列举了很多新闻的标题及其原始链接。如图所示:
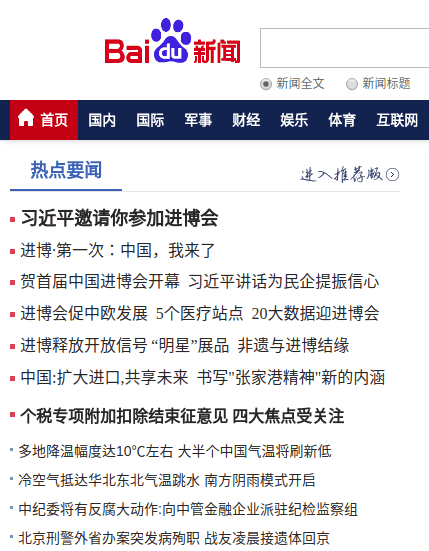
我们的目标就是从这里提取那些新闻的链接并下载。流程比较简单:
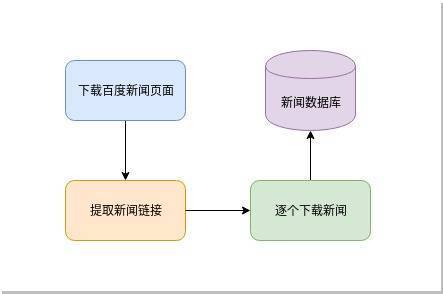
根据这个简单流程,我们先实现下面的简单代
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9194
9194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









