








Google近期在Udacity上发布了Android性能优化的在线课程,分别从渲染,运算与内存,电量几个方面介绍了如何去优化性能,这些课程是Google之前在Youtube上发布的Android性能优化典范专题课程的细化与补充。
下面是运算篇章的学习笔记,部分内容与前面的性能优化典范有重合,欢迎大家一起学习交流!
1)Intro to Compute and Memory Problems
Android中的Java代码会需要经过编译优化再执行的过程。代码的不同写法会影响到Java编译器的优化效率。例如for循环的不同写法就会对编译器优化这段代码产生不同的效率,当程序中包含大量这种可优化的代码的时候,运算性能就会出现问题。想要知道如何优化代码的运算性能就需要知道代码在硬件层的执行差异。
2)Slow Function Performance
如果你写了一段代码,它的执行效率比想象中的要差很多。我们需要知道有哪些因素有可能影响到这段代码的执行效率。例如:比较两个float数值大小的执行时间是int数值的4倍左右。这是因为CPU的运算架构导致的,如下图所示:

虽然现代的CPU架构得到了很大的提升,也许并不存在上面所示的那么大的差异,但是这个例子说明了代码写法上的差异会对运算性能产生很大的影响。
通常来说有两类运行效率差的情况:第1种是相对执行时间长的方法,我们可以很轻松的找到这些方法并做一定的优化。第2种是执行时间短,但是执行频次很高的方法,因为执行次数多,累积效应下就会对性能产生很大的影响。
修复这些细节效率问题,需要使用Android SDK提供的工具,进行仔细的测量,然后再进行微调修复。
3)Traceview Walkthrough
通过Android Studio打开里面的Android Device Monitor,切换到DDMS窗口,点击左边栏上面想要跟踪的进程,再点击上面的Start Method Tracing的按钮,如下图所示:
启动跟踪之后,再操控app,做一些你想要跟踪的事件,例如滑动listview,点击某些视图进入另外一个页面等等。操作完之后,回到Android Device Monitor,再次点击Method Tracing的按钮停止跟踪。此时工具会为刚才的操作生成TraceView的详细视图。
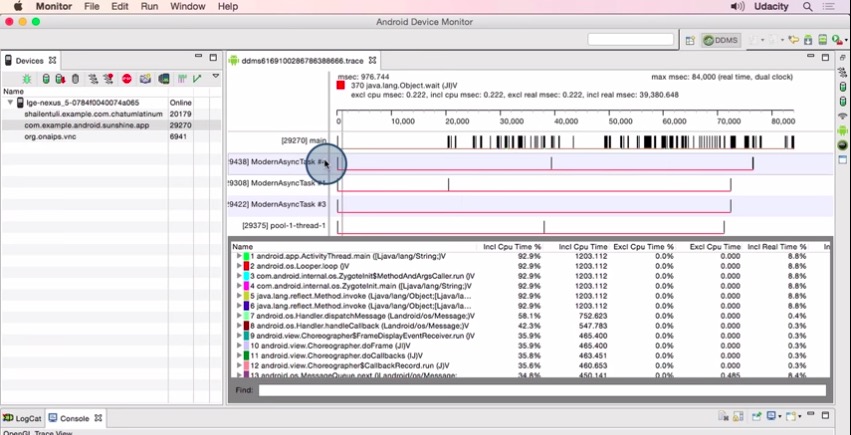
关于TraceView中详细数据如何查看,这里不展开了,有很多文章介绍过。
4)Batching and Caching
为了提升运算性能,这里介绍2个非常重要的技术,Batching与Caching。
Batching是在真正执行运算操作之前对数据进行批量预处理,例如你需要有这样一个方法,它的作用是查找某个值是否存在与于一堆数据中。假设一个前提,我们会先对数据做排序,然后使用二分查找法来判断值是否存在。我们先看第一种情况,下图中存在着多次重复的排序操作。

在上面的那种写法下,如果数据的量级并不大的话,应该还可以接受,可是如果数据集非常大,就会有严重的效率问题。那么我们看下改进的写法,把排序的操作打包绑定只执行一次:
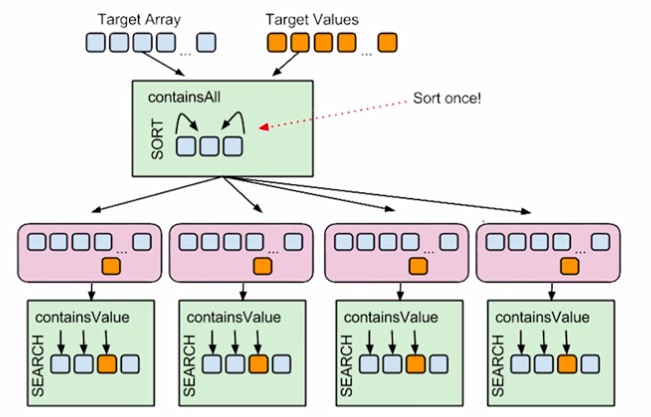
上面就是Batching的一种示例:把重复的操作拎出来,打包只执行一次。
Caching的理念很容易理解,在很多方面都有体现,下面举一个for循环的例子:

上面这2种基础技巧非常实用,积极恰当的使用能够显著提升运算性能。
5)Blocking the UI Thread
提升代码的运算效率是改善性能的一方面,让代码执行在哪个线程也同样很重要。我们都知道Android的Main Thread也是UI Thread,它需要承担用户的触摸事件的反馈,界面视图的渲染等操作。这就意味着,我们不能在Main Thread里面做任何非轻量级的操作,类似I/O操作会花费大量时间,这很有可能会导致界面渲染发生丢帧的现象,甚至有可能导致ANR。防止这些问题的解决办法就是把那些可能有性能问题的代码移到非UI线程进行操作。
6)Container Performance
另外一个我们需要注意的运算性能问题是基础算法的合理选择,例如冒泡排序与快速排序的性能差异:
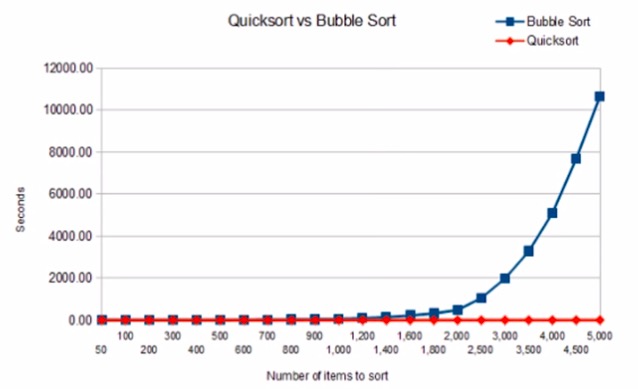
避免我们重复造轮子,Java提供了很多现成的容器,例如Vector,ArrayList,LinkedList,HashMap等等,在Android里面还有新增加的SparseArray等,我们需要了解这些基础容器的性能差异以及适用场景。这样才能够选择合适的容器,达到最佳的性能。

Performance Tips
以下主要介绍一些小细节的优化技巧,虽然这些小技巧不能较大幅度的提升应用性能,但是恰当的运用这些小技巧并发生累积效应的时候,对于整个App的性能提升还是有不小作用的。通常来说,选择合适的算法与数据结构会是你首要考虑的因素,在这篇文章中不会涉及这方面的知识点。你应该使用这篇文章中的小技巧作为平时写代码的习惯,这样能够提升代码的效率。
通常来说,高效的代码需要满足下面两个原则:
- 不要做冗余的工作
- 尽量避免执行过多的内存分配操作
在优化App时其中一个难点就是让App能在各种型号的设备上运行。不同版本的虚拟机在不同的处理器上会有不同的运行速度。你甚至不能简单的认为“设备X的速度是设备Y的F倍”,然后还用这种倍数关系去推测其他设备。另外,在模拟器上的运行速度和在实际设备上的速度没有半点关系。同样,设备有没有JIT(关于JIT,简单的理解可以参考这里)也对运行速度有重大影响:在有JIT情况下的最优化代码不一定在没有JIT的情况下也是最优的。
为了确保App在各设备上都能良好运行,就要确保你的代码在不同档次的设备上都尽可能的优化。
避免创建不必要的对象
创建对象从来不是免费的。Generational GC可以使临时对象的分配变得廉价一些,但是执行分配内存总是比不执行分配操作更昂贵。
随着你在App中分配更多的对象,你可能需要强制gc,而gc操作会给用户体验带来一点点卡顿。虽然从Android 2.3开始,引入了并发gc,它可以帮助你显著提升gc的效率,减轻卡顿,但毕竟不必要的内存分配操作还是应该尽量避免。
因此请尽量避免创建不必要的对象,有下面一些例子来说明这个问题:
- 如果你需要返回一个String对象,并且你知道它最终会需要连接到一个
StringBuffer,请修改你的函数实现方式,避免直接进行连接操作,应该采用创建一个临时对象来做字符串的拼接这个操作。 - 当从已经存在的数据集中抽取出String的时候,尝试返回原数据的substring对象,而不是创建一个重复的对象。使用substring的方式,你将会得到一个新的String对象,但是这个string对象是和原string共享内部
char[]空间的。
一个稍微激进点的做法是把所有多维的数据分解成一维的数组:
- 一组int数据要比一组Integer对象要好很多。可以得知,两组一维数组要比一个二维数组更加的有效率。同样的,这个道理可以推广至其他原始数据类型。
- 如果你需要实现一个数组用来存放(Foo,Bar)的对象,记住使用Foo[]与Bar[]要比(Foo,Bar)好很多。(例外的是,为了某些好的API的设计,可以适当做一些妥协。但是在自己的代码内部,你应该多多使用分解后的容易)。
通常来说,需要避免创建更多的临时对象。更少的对象意味者更少的gc动作,gc会对用户体验有比较直接的影响。
选择Static而不是Virtual
如果你不需要访问一个对象的值,请保证这个方法是static类型的,这样方法调用将快15%-20%。这是一个好的习惯,因为你可以从方法声明中得知调用无法改变这个对象的状态。
常量声明为Static Final
考虑下面这种声明的方式
1 2 | |
编译器会使用一个初始化类的函数,然后当类第一次被使用的时候执行。这个函数将42存入intVal,还从class文件的常量表中提取了strVal的引用。当之后使用intVal或strVal的时候,他们会直接被查询到。
我们可以用final关键字来优化:
1 2 | |
这时再也不需要上面的方法了,因为final声明的常量进入了静态dex文件的域初始化部分。调用intVal的代码会直接使用42,调用strVal的代码也会使用一个相对廉价的“字符串常量”指令,而不是查表。
Notes:这个优化方法只对原始类型和String类型有效,而不是任意引用类型。不过,在必要时使用
static final是个很好的习惯。
避免内部的Getters/Setters
像C++等native language,通常使用getters(i = getCount())而不是直接访问变量(i = mCount)。这是编写C++的一种优秀习惯,而且通常也被其他面向对象的语言所采用,例如C#与Java,因为编译器通常会做inline访问,而且你需要限制或者调试变量,你可以在任何时候在getter/setter里面添加代码。
然而,在Android上,这不是一个好的写法。虚函数的调用比起直接访问变量要耗费更多。在面向对象编程中,将getter和setting暴露给公用接口是合理的,但在类内部应该仅仅使用域直接访问。
在没有JIT(Just In Time Compiler)时,直接访问变量的速度是调用getter的3倍。有JIT时,直接访问变量的速度是通过getter访问的7倍。
请注意,如果你使用ProGuard,你可以获得同样的效果,因为ProGuard可以为你inline accessors.
使用增强的For循环
增强的For循环(也被称为 for-each 循环)可以被用在实现了 Iterable 接口的 collections 以及数组上。使用collection的时候,Iterator会被分配,用于for-each调用hasNext()和next()方法。使用ArrayList时,手写的计数式for循环会快3倍(不管有没有JIT),但是对于其他collection,增强的for-each循环写法会和迭代器写法的效率一样。
请比较下面三种循环的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
- zero()是最慢的,因为JIT没有办法对它进行优化。
- one()稍微快些。
- two() 在没有做JIT时是最快的,可是如果经过JIT之后,与方法one()是差不多一样快的。它使用了增强的循环方法for-each。
所以请尽量使用for-each的方法,但是对于ArrayList,请使用方法one()。
Tips:你还可以参考 Josh Bloch 的 《Effective Java》这本书的第46条
使用包级访问而不是内部类的私有访问
参考下面一段代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
这里重要的是,我们定义了一个私有的内部类(Foo$Inner),它直接访问了外部类中的私有方法以及私有成员对象。这是合法的,这段代码也会如同预期一样打印出”Value is 27”。
问题是,VM因为Foo和Foo$Inner是不同的类,会认为在Foo$Inner中直接访问Foo类的私有成员是不合法的。即使Java语言允许内部类访问外部类的私有成员。为了去除这种差异,编译器会产生一些仿造函数:
1 2 3 4 5 6 | |
每当内部类需要访问外部类中的mValue成员或需要调用doStuff()函数时,它都会调用这些静态方法。这意味着,上面的代码可以归结为,通过accessor函数来访问成员变量。早些时候我们说过,通过accessor会比直接访问域要慢。所以,这是一个特定语言用法造成性能降低的例子。
如果你正在性能热区(hotspot:高频率、重复执行的代码段)使用像这样的代码,你可以把内部类需要访问的域和方法声明为包级访问,而不是私有访问权限。不幸的是,这意味着在相同包中的其他类也可以直接访问这些域,所以在公开的API中你不能这样做。
避免使用float类型
Android系统中float类型的数据存取速度是int类型的一半,尽量优先采用int类型。
就速度而言,现代硬件上,float 和 double 的速度是一样的。空间而言,double 是两倍float的大小。在空间不是问题的情况下,你应该使用 double 。
同样,对于整型,有些处理器实现了硬件几倍的乘法,但是没有除法。这时,整型的除法和取余是在软件内部实现的,这在你使用哈希表或大量计算操作时要考虑到。
使用库函数
除了那些常见的让你多使用自带库函数的理由以外,记得系统函数有时可以替代第三方库,并且还有汇编级别的优化,他们通常比带有JIT的Java编译出来的代码更高效。典型的例子是:Android API 中的 String.indexOf(),Dalvik出于内联性能考虑将其替换。同样 System.arraycopy()函数也被替换,这样的性能在Nexus One测试,比手写的for循环并使用JIT还快9倍。
Tips:参见 Josh Bloch 的 《Effective Java》这本书的第47条
谨慎使用native函数
结合Android NDK使用native代码开发,并不总是比Java直接开发的效率更好的。Java转native代码是有代价的,而且JIT不能在这种情况下做优化。如果你在native代码中分配资源(比如native堆上的内存,文件描述符等等),这会对收集这些资源造成巨大的困难。你同时也需要为各种架构重新编译代码(而不是依赖JIT)。你甚至对已同样架构的设备都需要编译多个版本:为G1的ARM架构编译的版本不能完全使用Nexus One上ARM架构的优势,反之亦然。
Native 代码是在你已经有本地代码,想把它移植到Android平台时有优势,而不是为了优化已有的Android Java代码使用。
如果你要使用JNI,请学习JNI Tips
Tips:参见 Josh Bloch 的 《Effective Java》这本书的第54条
关于性能的误区
在没有JIT的设备上,使用一种确切的数据类型确实要比抽象的数据类型速度要更有效率(例如,调用HashMap map要比调用Map map效率更高)。有误传效率要高一倍,实际上只是6%左右。而且,在JIT之后,他们直接并没有大多差异。
在没有JIT的设备上,读取缓存域比直接读取实际数据大概快20%。有JIT时,域读取和本地读取基本无差。所以优化并不值得除非你觉得能让你的代码更易读(这对 final, static, static final 域同样适用)。
文章学习自http://developer.android.com/guide/components/processes-and-threads.html
转载请注明出自http://kesenhoo.github.com,谢谢
知识共享许可协议:本站作品由HuKai创作,采用知识共享 署名-非商业性使用-相同方式共享 4.0 国际 许可协议进行许可。
如果你觉得这篇文章对你有帮助,请点击下面的分享链接,你还可以选择扫描二维码进行打赏!















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









