







引言
关于负载均衡,什么是负载均衡? 这个概念挺大的。但是我们要理解一个大的概念,就得把化繁为简,把它分成多个部分,或者是拆成多个层次的来理解。我所理解的负载均衡: 按照实现方式分成两种,一种是动态的负载均衡:根据当前服务的负载来分配新的请求;与之相对的就是非动态的负载均衡:用预先设计好的算法去分配新的请求。从统计学角度来看,大多数的情况下非动态的负载均衡方案能够满足负载的平均分配了。曾经和一位资深同事了解过在某个非动态负载均衡的系统中,统计每台服务器的请求量,发现每一台机器的请求总量几乎相等。 而动态均衡方案只是在一些非动态负载均衡不能有效分配的情况下的补充。负载均衡如果按照业务类型来分 ,又有好多不同方面。比如网络交换机系统的负载均衡,web服务系统的负载均衡,分布式任务的负载均衡,存储类集群的负载均衡。 每一种系统的负载均衡的概念和方法差异都又有千差万别。
问题描述
提到数据存储类服务集群的负载均衡方案这个问题, 主要的想法来源是和我们组的panda同学上个星期的一次关于数据存储类服务如何扩容的讨论。panda同学提了一个实际的问题。把这个问题稍微从具体业务中抽象出来一点点,可以这样表述: 有一个数据存储类的服务集群一共有3台机器,一共保存着300万用户的资料,也就是每台机器保存有100万用户的资料。 现在要扩容一台服务器,也就是要变成4台机器,每台保存75万用户的资料,应该怎么做呢?
非一致性哈希解决方案以及问题
问题是这样的,我们暂且不去讨论它的答案,而是先关注一个可能被忽略的细节。"现在有3台服务器,一共保存着这300万用户的资料。" 如何分这300万用户的资料的呢?其实这个细节问题的答案就是负载均衡的方案。对于数据存储类服务集群的负载均衡,其核心问题就是如何分配数据。而且一般情况下,对于数据存储类的服务集群,无法采用动态的负载均衡来实现。毕竟数据在那里,如果用户甲的数据在A机器上,那就无法从B机器来获取用户甲的数据。因此,我们采用非静态的方式来分配这300万用户的资料,最常见的方法就是哈希。假如每个用户都有一个整数的uid作为唯一表示。那么可以用哈希函数把用户的uid映射成到[1,3]的区间内,再将哈希值作为机器的ID就可以实现负载均衡了。而最常见的哈希函数就是取模。比如有3台服务器就模3, 用户的具体分配方案如下图:
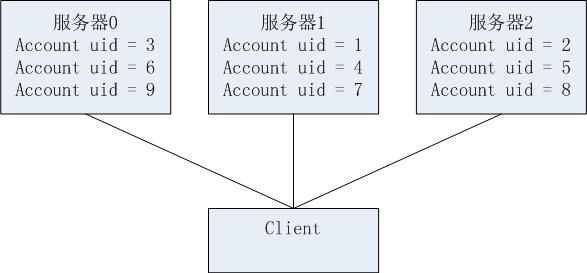
图1 取模的方式分配用户
比如uid=3, 3%3=0,用户就被分到server0. 在client端的存取用户资料的代码大概就像下面这样的写法:
GetServiceByUid(uid)
{
server_id = uid % serverCount ;
return Service(server_id);
}
GetUserInfo(uid)
{
service = GetServiceByUid(uid);
return service.GetUserInfo(uid);
}
SetUserInfo(info)
{
service = GetServiceByUid(info.uid);
return service.SetUserInfo(info);
}

图2 取模方式的扩容方案
可以看到。服务器0的数据全部都要换,服务器1也是如此。假如要扩容,就会造成大量的数据迁移。并且这样的数据迁移几乎没法在不停服务的方法下完成。如果一定要不停服务迁移,则需要用额外的四台机器,一边让老系统提供服务,一边迁移数据。等新老系统的数据总量完全相等的时候,再把整个系统切到新的系统。用这样的方法做扩容,估计运维部门听到就会很头痛吧。
上面的方案不好,究其原因在于哈希函数。当机器数+1时,绝大多数的数据的哈希值都发生了改变。这样一来,我们以前所分配的存储方案全部都失效了。因此,需要哈希函数在增减机器时,尽量少去打乱原来的数据分配。因此需要提高哈希函数的单调性。有一种算法叫一致性哈希可以解决这个问题。
一致性哈希算法
这篇 一致性哈希算法 的文章是这样介绍的:
1 用户的整数uid可以看成是一个0 至 2^32-1 的数值空间。 可以把这个数值空间想象成一个收尾相连的圆环。如下图所示:

图3 原型数据空间
2 把用户的uid的hash值映射成圆环上的点。这很好理解, 下图中的object就是uid。

图4 圆形数据空间的哈希映射
3 将'服务器' 利用同样的哈希函数映射到同个数值空间中。 这句话比较不好理解。 ’服务器'如何能够映射到一个数值空间中。实际上你可以自己想办法去实现,比如你可以用服务器的IP做哈希。如下图所示:

图5 一致性哈希
上图中的CacheA 、CacheB 和CacheC等蓝色的节点就是存储服务器。红色的节点是数据。可以清楚的看到,几个蓝色的节点把数值空间清晰的分成了多个子空间。查找数据所在服务器,看一下红色节点在哪个子空间就可以了。再增加一点想象力,一台服务器可以分成许多虚拟的蓝色节点。查找数据所在的服务器的时候,分成两步走,先查数据所在的虚拟空间再查虚拟节点对应的服务器。
一致性哈希算法最大的好处就是在于增加、删除节点时,不会大面积的影响数据所在的服务器的位置。而只影响有限的一到两台服务器。 一致性哈希的精华在于虚拟节点。因为当蓝色节点数量较少的时候,很难保证用户数据是平均分配到不同的服务器上的。当把一个节点分成多个虚拟节点的时候,可以保证用户数据在物理机器上更平均的分配。
在实践中使用一致性哈希算法
如何在实践中使用一致性哈希? 首先把数据空间的粒度划分的更大,先将整个数据空间划分为有限个子空间作为数据扩容最基本的单位。例如我们将用户的uid通过哈希函数映射成[0, 99] 这100个值,也就是划分为100个子空间。 这就好比先找来100个大桶,把所有用户资料先丢到这100个大桶里。 第二步是用一台服务器管理多个哈希值的用户资料,这就好比把几个大桶放在一个服务器里。可以看下图:

图6 实践中的一致性哈希
在上图中,有3台服务器,7个桶。先用哈希把用户uid映射到7个大桶里, 比如用模7的方式就可以实现。然后根据配置文件查找到桶对应的服务器在哪里。具体的代码和非一致性哈希的代码只有GetServiceByUid有所不同。配置文件和伪代码如下:
//file: userinfo_client.conf
[server1]
addr = 10.0.0.2
bucket = 1,2
[server2]
addr = 10.0.0.3
bucket= 3,4
[server3]
addr = 10.0.0.4
bucket = 5,6,7
//file: userinfo_client.cpp
GetServiceByUid(uid)
{
bucket_id = uid%7 +1 ;
service_id = GetServiceByBucketId(bucket_id)
return Service(service_id);
}不停机扩容与“阴影桶"
这种方法实践简单实用。扩容起来也比较方便。停机扩容我们就不谈了,只要迁移完数据再修改配置文件。
如果要不停机扩容又该如何操作呢? 这里就需要用到一个“阴影桶”的概念了。阴影桶是一个数据桶的未完成的复制品。在扩容的过程中,我们首先要在新机器上配置一个阴影桶。将原来的数据桶的数据逐步迁移到阴影桶中。然后将对于被迁移的数据通的写操作全部要写两次。既要写原来的数据桶,也要写阴影桶。当阴影桶和原数据桶的数据保持完全一致的时候,废弃掉原数据桶,将阴影桶升级为数据桶就完成数据迁移了。
比如在下面的系统中,我们要扩容一台server4, 并把数据桶 bucket7的不停机迁移到server4上。
原来系统是这样的:
图7 系统扩容之前
第一步,我们在配置文件中增加一台服务器server4, 然后在server4中配置一个bucket7的阴影桶。
[server1]
addr = 10.0.0.2
bucket = 1,2
[server2]
addr = 10.0.0.3
bucket= 3,4
[server3]
addr = 10.0.0.4
bucket = 5,6,7
[server4]
addr= 10.0.0.5
shadow_bucket=7
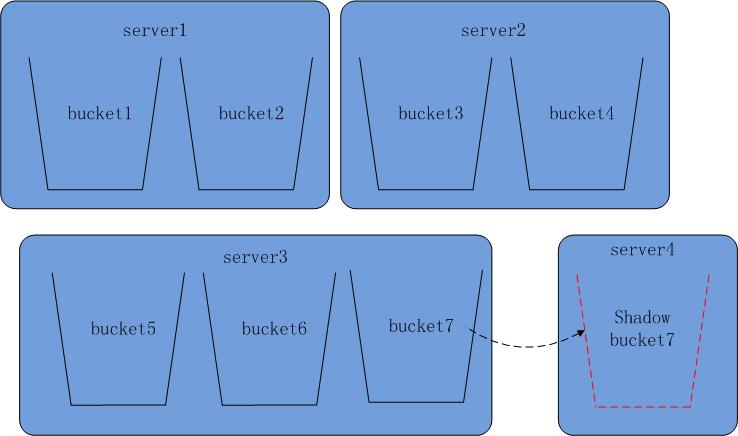
图8 扩容中的系统
server4是一台新的服务器,我们在上面设置一个bucket7的阴影桶。 对于bucket7的写操,既要写server3上的原数据桶,也要写server4上的阴影桶。同时进行server3到server4的数据迁移。在数据迁移过程中, shadow bucket7上的数据是不完全的,所以对于bucket7的读操作还全部是在server3上进行的。
这时的client程序所有的写操作的代码会和以前的版本有修改,对于任何的写操作都要检查是否有阴影桶,如果有阴影桶则也要写到阴影桶中:
SetUserInfo(info)
{
service = GetServiceByUid(info.uid);
service.SetUserInfo(info);
if((shadow_service = GetShadowServiceByUid(info.uid)))
shadow_service.SetUserInfo(info);
}
[server1]
addr = 10.0.0.2
bucket = 1,2
[server2]
addr = 10.0.0.3
bucket= 3,4
[server3]
addr = 10.0.0.4
bucket = 5,6
[server4]
addr= 10.0.0.5
bucket=7
这时的集群系统如下图所示:

图9 扩容后的系统
对于合并操作也是采用相同的方法,设置阴影桶并在双写的同时做数据迁移。
总结
这篇文章讨论了多种数据存储集群的实现方案。采用一致性哈希的算法可以在一定程度上减少扩容带来的冲击。我们在实践中可以结合实际情况使用一致性哈希算法实现数据存储集群的负载均衡,简化扩容的操作以避免相应的问题和风险。















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









